技術部データ基盤チームに所属しているまつもとです。ペパボではGoogle Cloud Platform(以下 GCP)をメインで利用した社内データ活用基盤「Bigfoot」を開発・運用しています。BigfootはBigQueryによるデータウェアハウス・データマートを各部署へ提供することが大きな役割となっています。BigQueryへのETLはGCPのワークフローオーケストレーションサービスであるCloud Composerによって構成しています。データのExtractとLoadは基本的にEmbulkとStitchを利用していますが、対応していないデータソースについてはPythonでExtractとLoadのコードを個別に実装しています。
新たなデータソースに対応するために都度ETLを実装するのは非効率であるため、最近急速に対応データソースの数を増やしているOSSのETLシステム Airbyteを導入しました。この記事では、Airbyteを安定的に本番運用するうえで工夫した点を紹介します。
Airbyteの現状のステータス
AirbyteはOSSのETLシステムです。データ抽出元(Source)とデータロード先(Destination)を設定することでデータ同期を自動で行うことができます。この分野のソフトウェアとしては、EmbulkやSingerが有名ですが、ジョブスケジューリングやエラー通知の機能なども含まれるため、どちらかというとtroccoやStitchなどの統合データサービスが比較対象になると思います。
AirbyteはOSS版と有料のマネージド・サービスが用意されています。OSS版は各種プラットフォーム向けにdocker-composeやKubernetesでデプロイする方法が用意されています。マネージド・サービスはAirbyte Cloudという名称でサービスを開始していますが、現在USのみでの提供となっています。(2022年にはUS以外の国にもサービス提供を広めていく予定となっているようです。)
Airbyteの採用理由
ペパボではCustomer Opsを推進1しています。自社が運営するWebサービスのカスタマーサポートに関わるデータをBigfootに収集して分析をしています。主にZendeskのSupportやChatというサービスから Bigfootにデータを同期して利用していましたが、新たにTalkのデータも同期することになりました。SupportとChatのデータ同期にはStitchを利用していますが、StitchはTalkには対応していません。他のETLサービスも検討しましたが対応しているものが見当たりませんでした。そのため、自前でREST APIからのデータ抽出を開発するか、すでに対応する機能が用意されているAirbyteをセルフホストするという選択肢に絞られました。
これまでStitchやEmbulkが対応していないデータソースについては、データ抽出部分を自前で開発してきましたが、今後対応するデータソースが増えていくとそのメンテナンスに手が足りなくなることが予想されます。特に、SaaSのAPIの仕様変更に追随していくのは大変であり、少人数のチームで運用していくのは難しいと考えました。
一方でAirbyteの場合はZendesk Talkからのデータ抽出機能がすでに用意されています。様々なWebサービスやデータベースに対するデータ抽出とデータロードの機能は、Connectorと呼ばれるプラグインの形式で実装されています。ConnectorのコードもAirbyte本体のリポジトリでmonorepoで管理されており、Airbyte社のメンバーとコミュニティによってメンテナンスされています。全てのConnectorに対してユニットテストだけでなく、一貫したインテグレーションテストが用意されておりCI/CDで品質が維持されています。バグ修正や機能追加などの変更はAirbyteの開発コアメンバーのレビューのもと速やかにリリースされます。
ETL対象のサービスごとに開発されるConnectorの継続的な品質維持は重要です。既にStitchやEmbulkでETLしているサービスも今後移行することを視野に入れてAirbyteを導入することに決めました。
尚、Airbyteは現状Alpha版のステータスなので、導入に際しては注意深く検証をしながらスモールスタートで本番運用を開始しました。
システム構成
先に述べた通りペパボのデータ基盤はBigQueryを中心としたGCPのリソースをメインに使用して構成されています。今回はスモールスタートとしてZendesk TalkのETLを対象に本番運用を開始し、安定稼働の確認を取りながら少しずつ他サービスのETLを追加していく計画としました。AirbyteのドキュメントではGCEにdocker-composeでデプロイする方法が記述されているので、この方法でデプロイして暫く運用することにしました。Kubernetesでのデプロイ方法も用意されていますが、GKEはインフラコストだけでなくそれなりに運用のコストも掛かるため今回は見送りました。
運用
ここからがこの記事の本題になります。Airbyteを本番システムとして運用していくうえで実装したシステム監視やバックアップなどの仕組みを紹介します。
監視
システムの正常性監視は本番システムでは必須ですが、GCE上にセルフホストでサービスを稼働させる環境で監視を実装するのはそれなりに手間が掛かります。スモールスタートで始める場合でも、本番システムである以上堅牢な仕組みを作る必要があります。
Airbyteサーバにおいてはデータ同期処理が行える状態にあるかどうかという点が一番重要です。これを正常の定義として監視する対象としました。より細かいシステムの状態を捉えるためには、サーバインスタンスの生死、サービスプロセスの生死、ネットワーク疎通などの粒度で監視する必要がありますが、今回はスモールスタートなので最も重要な基準としてデータ同期処理が行えるかどうかを捉えることにしました。
データ同期処理が行えるかどうかを確認をするには、Airbyteに設定されているConnection(データ同期処理)が実行できるかどうかの確認ができれば良いです。そのために、何も同期しないで終了するConnection(監視用Connection)を用意してそれを定期的に実行することにしました。Airbyteのスケジューラで実行する構成にすると、外部からジョブを特定して実行ステータスを取得する必要がありエラーを検知する処理が煩雑になるため、外部からConnectionをトリガして成否を確認する設計を選びました。具体的には、Cloud FunctionsからAirbyteのREST API経由で監視用Connectionをトリガするように実装し、そのCloud FunctionsをCloud Schedulerで定期実行しています。Connectionの実行に失敗した場合はSentryに通知されます。また、Cloud FunctionsからはServerless VPC access connectorを経由してGCEのVPC内部IPアドレスにアクセスするように構成しています。以下がその全体像です。
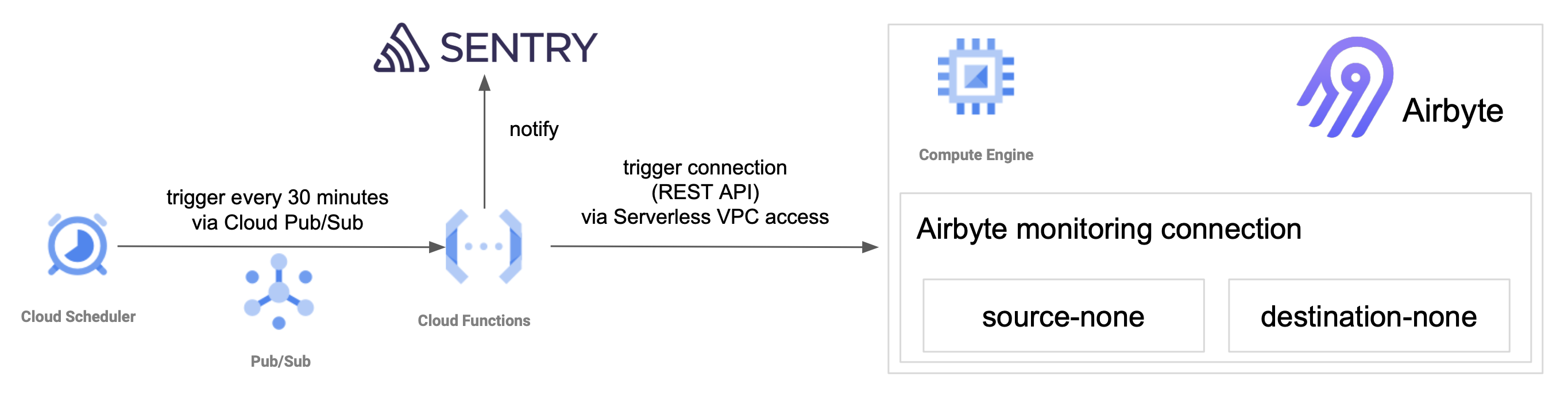
何も同期しないConnectionは、source-noneとdestination-noneというConnectorで構成されています。これらは、内部だけで使うため独自に開発してローカルのDocker imageとしてbuildして使っています。
ジョブ実行結果のロギングとエラー通知
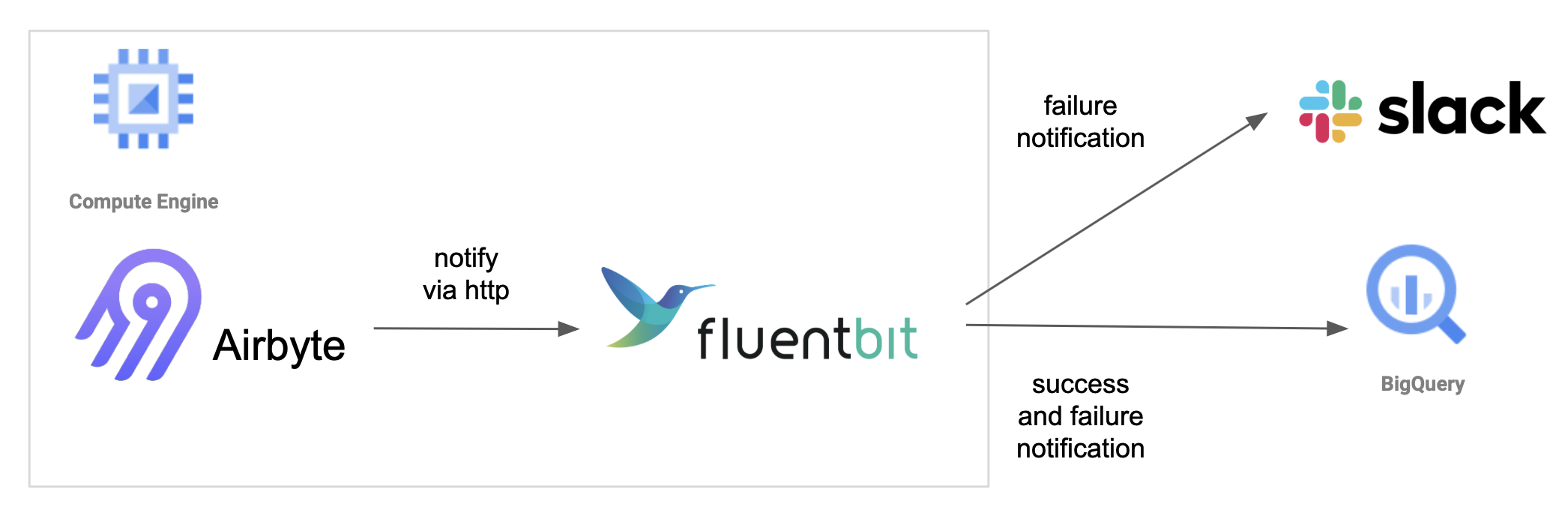
データ同期ジョブが失敗した場合にすぐに気付けるようにSlackへの失敗通知も設定しています。また、データ基盤チームではシステムのSLI/SLOを設定しているため、AirbyteにおいてもSLIとしてジョブ失敗率を計測しています。ジョブ失敗率計測のため、全ジョブの実行結果をBigQueryへ連携するようにしています。
Airbyteはジョブ実行結果をHTTP POSTでSlackのWeb Hookへ通知する機能が備わっていますので、この機能を利用してSlackとBigQueryへ通知を送信しています。ただし通知先は1つしか設定できないため、AirbyteコンテナにFluent Bitコンテナを併設し、Fluent Bitで通知を分岐させてルーティングしています。
コンフィグのバックアップ
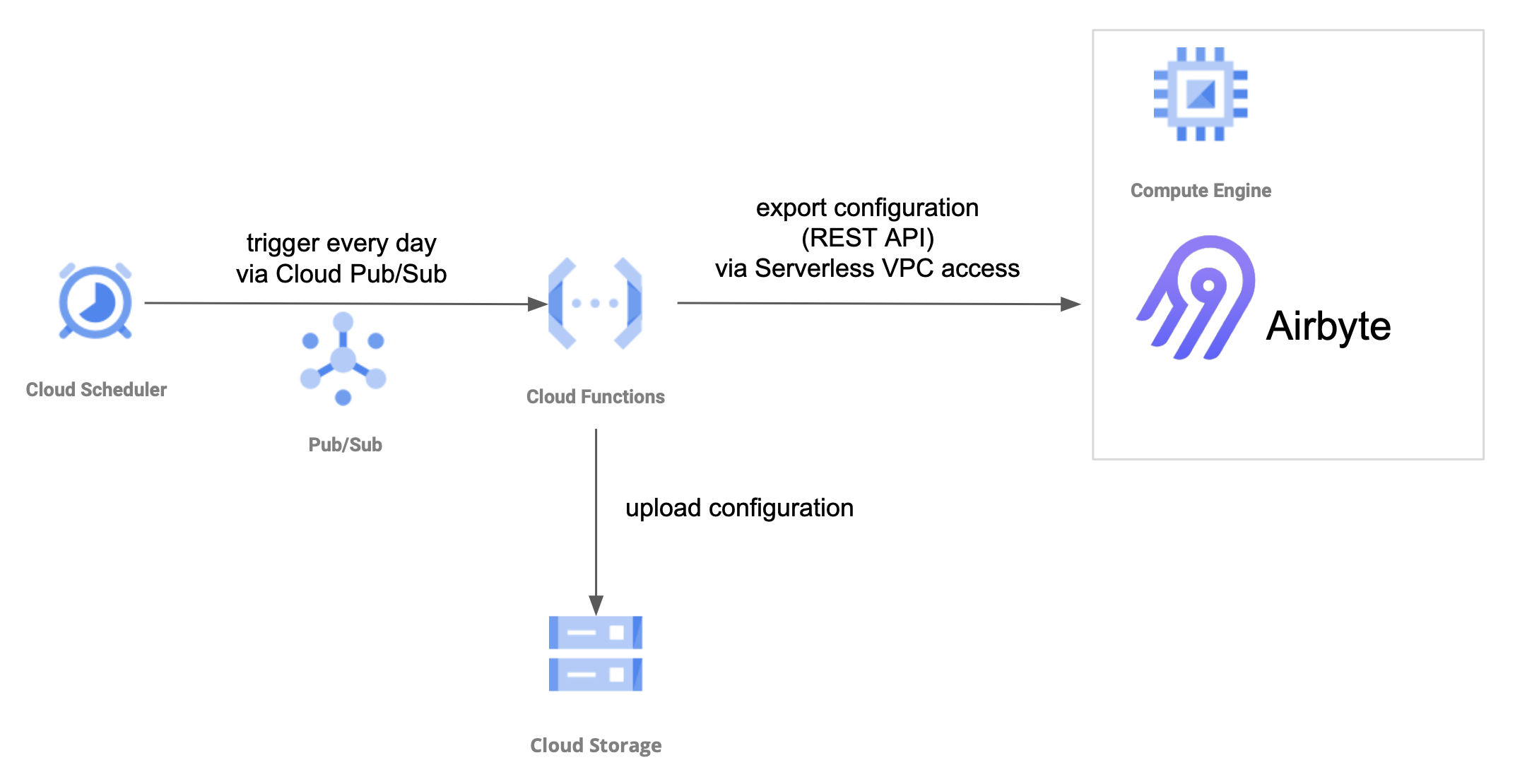
サーバインスタンスのトラブル等でAirbyteのコンフィグが消失するのも避けたいです。そのため、定期的なコンフィグの自動バックアップも実装しました。データ基盤チームではGitHub Enterpriseを使ったIaCを実践しているため、サーバの設定なども基本的にはリポジトリで管理をしています。しかし、AirbyteのコンフィグにはAPIやデータベースへアクセスする際に使うクレデンシャルの情報が平文で記載されています。従ってリポジトリ管理はできないため、アクセス制御が可能なGCSバケットへコンフィグを保存することにしました。定期的に自動でバックアップするため、ここでもCloud SchedulerとCloud Functionsを使って構成しました。
今後に向けて
現在、上記構成で安定的に稼働を続けていますが、今後対応しなければならない課題がいくつかあります。今回の構成では、Airbyteへのアクセス制御のため、Web UIへアクセスするためには、GCEインスタンスへSSH Tunnelを張る必要があります。今はそれほど頻繁にアクセスしないので問題になりませんが、いずれはユーザアカウントによるアクセス制御ができるようにしたいと考えています。その場合、GCPのIdentity Aware Proxy経由でアクセスする構成になるかと思います。また、ETL対象が増えてきたときにスケールしやすようにKubernetesへの移設も考えていきたいです。
まだ日本での提供が発表されていないAirbyte Cloudについても併せて検討していきたいです。個人的にはAirbyteの最高経営責任者(CEO)のインタビュー記事で言及されているビジネスモデルに注目しています。「データ量ではなく、接続先の数やデータから得られる価値の種類に応じて課金」することを考えているようですのでコスト面でも期待しています。
最後に
Zendesk Talkのデータ同期から運用を開始したAirbyteですが、その後、データ基盤チームが運用しているシステム基盤のエラーログを分析するために、Sentryからのデータ同期でも利用しています。今後SaaSからのデータ同期をメインに利用が拡大していくものと予想しています。尚、個人的にもConnectorを開発するなどAirbyteへコントリビュート2していますので、引き続きOSSとしてのAirbyteの発展に寄与しながらペパボのデータ基盤の成長に活用していきたいと思います。