こんにちは!GMOペパボで Customer Ops を担当しているもりまい(@morimai)です。今回は、2020年7月に発足した CS 室の Customer Ops チームで取り組んでいる「ペパボのログ活用基盤『Bigfoot』を使った Zendesk のデータ可視化」について紹介します。
CS がひとつになった!Customer Ops チーム立ち上げ
元々ペパボでは、活動拠点やサービスごとに CS(カスタマーサポート、カスタマーサクセス)を担当する部署が存在していましたが、2020 年に CS 室として 1 つの組織に生まれ変わりました。CS 室発足については、CS 室室長のよっちさんが書いたマネージャーコラムで詳しく紹介しています。
CS 室には、カスタマーサポートやカスタマーサクセスの業務に必要なデータ基盤の構築や業務の自動化を担当する『Customer Ops チーム』が新設され、現在は、モニタリングボードの構築やデータ活用の促進をメインに活動をおこなっています。
CS 室の課題
発足当時、CS 室には以下のような課題がありました。
- CS に関わる数値の一部しか取得できていない
- CS がおこなった改善活動の効果測定ができない
- 「数値を取る」という仕事が増えることで、本来のミッションであるお客様の体験向上のためのリソースが取られてしまう
これらの課題解決のために、まずは「数値取得の自動化」をおこない、権限を持つ人は誰でも「見たいときに必要なデータを閲覧し利用することができる状態」を目指しました。2020 年時点でペパボのほとんどのサービスの問い合わせ対応ツールは Zendesk へ移行していたため、Zendesk 上の問い合わせデータの可視化を優先的に行いました。
ペパボのログ活用基盤『Bigfoot』を使った Zendesk の問い合わせデータの可視化
ペパボでは Zendesk の製品のうち、主に Support, Chat, Guide を利用しています(一部で Talk も利用しています)。これらのデータの多くは Zendesk のデータ分析ツールである Explore で参照・可視化が行えるため、以前までは Explore を使う場面が多くありました。
ですが、「数値取得の自動化」の環境を整える中で、「サービスを利用するお客様の情報を Zendesk 上の問い合わせデータ以外(サービスの利用状況など)と組み合わせて分析したい」という要望が出て、Explore だけで運用することが難しいということになり、ペパボのお客様の行動ログや属性情報を収集・分析・活用するための全社基盤『Bigfoot』を活用して、データの可視化を行うこととなりました。
(1)Zendesk のデータを BigQuery へ取り込む
『Bigfoot』のバックエンドは Google Cloud Platform(以下 GCP)が採用されています。Zendesk のデータの可視化は、GCP のデータウェアハウスである BigQuery へ Zendesk のデータを取り込むところから始まりました。
『Bigfoot』のバックエンドは以前まで Treasure Data が使われていましたが、2020年に GCP に移行されています。(※1)
GCP には、Treasure Data にあった連携サービスからデータを取り込む機能がないため、各種データソースからデータを抽出し BigQuery へデータを格納する ETL を個別に準備する必要がありました。ETL の実装の工数と運用の負荷が発生することが想像されましたが、Stitch(※2)という ETL をおこなえるサービスを導入することで、データソースごとに ETL を都度実装する必要がなくなりました。
Stitch でサインアップし、Zendesk のデータ連携の頻度や連携させたいテーブルやカラムを指定し、連携先として BigQuery を指定することで Zendesk の問い合わせデータを BigQuery へ取り込むことができました。(※3)
※1 :
ペパボのログ活用基盤「Bigfoot」を Google Cloud Platform に移設しました
※2 : Stitch: Simple, extensible ETL built for data teams
※3 : Zendesk Support (v1.0) | Stitch Documentation
(2)BigQuery へ取り込んだ Zendesk のデータをサービスごとのデータセットに振り分ける
ペパボでは、『ロリポップ!』や『minne』、『カラーミーショップ』、『SUZURI』など複数のサービスを運営しており、CS 室ではそれらのサービスの問い合わせを Zendesk のブランドに分け、各パートナーが担当するサービス(ブランド)のみ閲覧・返信が行えるようになっています。
ですが、Stitch では Zendesk のブランドを指定して抽出することはできず、全ブランドのデータが BigQuery 内の 1 つのデータセット内にロードされます。
BigQuery で 問い合わせデータを見たい人全員に Zendesk のデータを格納したデータセットの閲覧権限をつけてしまうと、「Zendesk 側では(管理者以外)特定のブランドの問い合わせデータのみ閲覧・返信が行える状態にある」にも関わらず、BigQuery から見ると全ブランドの問い合わせデータが閲覧できてしまい、Zendesk 側の権限と整合性が取れなくなります。
そこで、CS 室では、Stitch を使って BigQuery へ Zendesk の問い合わせデータを取り込んだ後は、Zendesk の権限に合わせて、BigQuery でサービスごとにデータセットを作成し、作成したデータセットに各サービスの問い合わせデータを振り分け、サービスデータセットに対して個別に閲覧権限を付与する運用としました。
サービスごとに作成されたデータセットへの Zendesk の問い合わせデータの振り分けは、GCP の Cloud Composer を使って実装しています。データの流れは次で説明します。
(3)サービスごとに振り分けられたデータを集計、グラフ化する
サービスのデータセットに振り分けられた問い合わせデータは、tickets や users, satisfaction_ratings というテーブルに分かれており、それぞれ、チケット情報、ユーザー情報、満足度アンケート情報などが格納されています。
例えばこれらのテーブルを使って、「担当者ごとの日々の対応件数や満足度を確認したい」といった場合には、tickets や satisfaction ratings などのテーブル単体では、担当者のユーザー名が確認できず集計しづらいため、tickets テーブルと users テーブルを JOIN したクエリを書くと、担当者の名前と日々の対応件数や満足度が参照できるようになります。
また、一部のサービスのデータセットにはお客様の利用サービスの設定情報もロードされているため、設定情報と問い合わせ頻度などを組み合わせて確認できるクエリを書いて、問い合わせされたお客様の傾向を分析する要素として利用できます。
頻繁に利用するクエリは、定期的に自動で実行されて特定のテーブルに情報が溜まっているとクエリ実行の手間がなくて嬉しいので、ここでも Cloud Composer を使って、集計用クエリの実行結果を格納するテーブルを集めたデータセットを作成し、毎時集計結果が更新されるように構築しています。
CS 室のホスティンググループでは、以下のような構成で合計 5 ブランド分の問い合わせデータを集計し、Data Studio でグラフ化して KPI の進捗を管理しています。
Bigfoot を活用した Zendesk のデータ可視化のための構成図
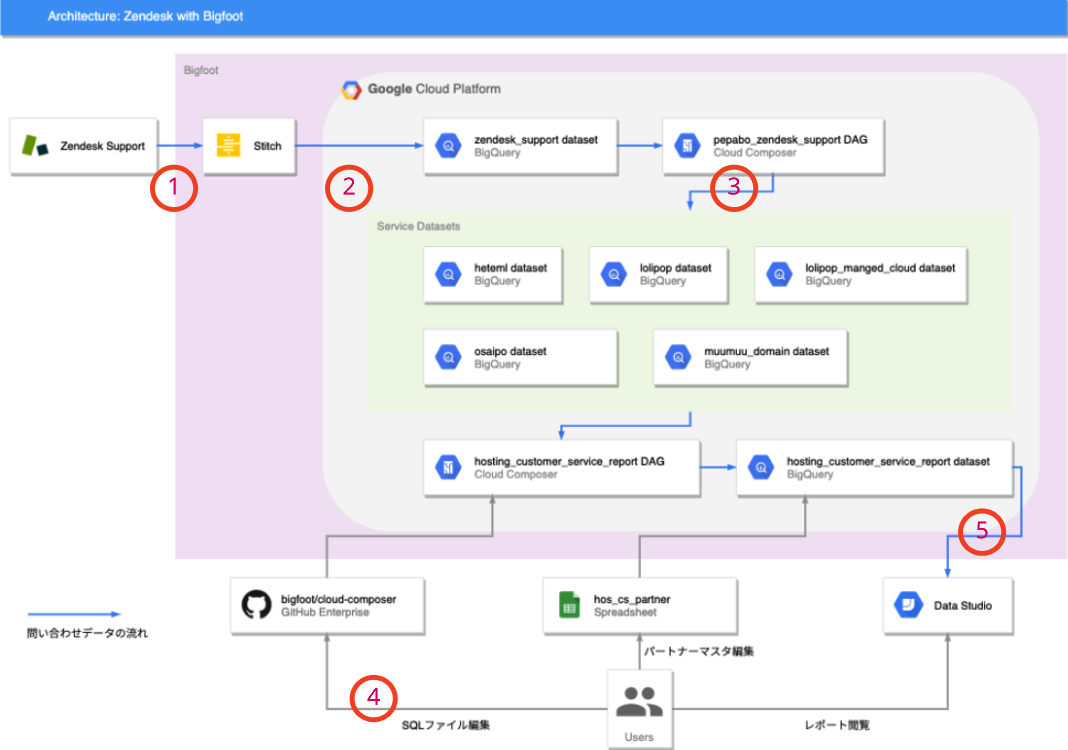
- Zendesk から Stitch を使ってデータの抽出
- Stitch から BigQuery の Zendesk データを格納するデータセットへデータをロード
- Cloud Composer を使って、サービスごとのデータセットへ Zendesk のデータを振り分け
- 管理がしやすい形に集計するためのクエリを CS 室のパートナーが作成し、Cloud Composer によって定期実行
- 集計データが格納されたテーブルを参照して Data Studio でグラフを作成、レポート化
まとめ
今回は、ペパボのログ活用基盤『Bigfoot』を使った Zendesk のデータ可視化についてご紹介しました。
紹介した内容は、ほとんどが 2020 年前半までにおこなったことだったのですが、CS 室が 1 つになってからはさらに可視化の範囲を広げて、現在は、ペパボのほとんどのサービスの問い合わせに関するデータが可視化された状態になりました。
今後は、CS 室がさらにデータドリブンな組織として活動を展開していき、対応品質や生産性の向上、顧客体験の向上へ繋げることができるよう取り組んでいきます。
また、現在 CS 室では、「キャリア採用」「新卒採用」「契約社員・アルバイト採用」で募集がございます。進化するペパボの CS で一緒に働きませんか!

