こんにちは!猫と布団と寿司が好きなことで有名なtsummichanです。 前回のテックブログでは、4月18日〜20日に開催されたRubyKaigi 2019の参加レポートをお届けしました。 今回は第2弾として、再びリレー形式で参加レポートをお届けしたいと思います!
Best practices in web API client development
こんにちは!minneでWebアプリケーションエンジニアをしている tsummichan と申します。
私は初めて技術系のカンファレンスに参加したのですが、RubyKaigiはお祭りのようでした。もっと勉強会っぽい雰囲気を想像していたので驚きましたが、楽しくてずっとワクワクしっぱなしな3日間でした!!
さて、私からは最終日であるDay3のセッションBest practices in web API client developmentについてレポートしたいと思います。
発表者は、ピクシブ株式会社の@sue445さんです。
このセッションでは、@sue445さんがAPIクライアントを実装した経験を通して、何をAPIクライアントで作るべきかについてやAPIクライアントを作る際に気をつけるべきことについて紹介されています。
資料はこちらです。
どうしてAPIクライアントを作るのか
@sue445さんがAPIクライアントを作るのは、仕事で必要になるので作る場合が多いそうです。
外部Webサービスを利用したアプリケーションを作成するときは、その外部WebサービスのAPIを使うことになります。場合によっては、公開されていないAPIを使用するためのクライアントを作成する必要があります。
何かのアプリケーションを作る際に作成されるAPIクライアントには4つのタイプがあると述べられていました。
- 自分が作った、公開されているAPIクライアント
- 自分が作った、非公開のAPIクライアント
- 他人が作った、公開されているAPIクライアント
- 他人が作った、非公開のAPIクライアント
公開されているAPIクライアントは、勉強や車輪の再開発的な目的で作られることもあります。他人が作った公開されているAPIクライアントには、サービスが公式に提供を行っているものも含みます。サービスが公式に提供しているAPIクライアントは利用する際に安心して利用できるという利点があるので、提供されている場合は自作するよりもそちらを使ったほうが良いです。
非公開のAPIクライアントは、自社サービスなど限定的な使われ方がされることが多いです。同じ社内なら言語が統一されていて、APIクライアントの提供側は楽ですが、サービスと密結合になってしまったり、APIクライアントをどこに置くのか?で迷うことがあります。そういった場合、gemとして切り出すことで結合を疎にすると良いと述べていました。
何をAPIクライアントで作るべきか?
APIクライアントの責務について、「単一責務で、対象のAPIを対象の言語で使いやすくすること」と述べていました。
これは、例えばGoならキャメルケース、Rubyならスネークケースというように言語の規約に合わせてパラメータを使いやすいように加工したり、APIを叩いた時のレスポンスを独自のエラークラスとしてラップして処理するというようなことはAPIクライアントで作るべきということです。
他にも、アクセストークン切れのエラーになったら新しいものを生成して自動送信するなど、アクセストークンの管理を利用者に意識させないためにAPIクライアントを作ることも例として挙げられていました。
何をAPIクライアントで作るべきでないか?
APIクライアントで作るべきでないものは、ライブラリの責務ではないことをする機能です。このセッションでは、例としてレスポンスを一定時間キャッシュするような仕組みやリクエストパラメータのバリデーションなどを挙げていました。
短期間のキャッシュはmemcachedやRedisに頼りたくなってしまいますが、そうするとmemcachedやRedisの設定が必要になりますし、複雑な実装になってメンテナンスしづらいコードになります。キャッシュの責務はクライアントではなくアプリケーションなので、アプリケーションに実装すべきです。
リクエストパラメータのバリデーションに関しては、パラメータが正しいかどうかはサーバーサイドしかわからないためクライアントの責務ではではないとのことですが、このあたりはケース・バイ・ケースでもある、と述べられていました。必須パラメータかどうかや空白を調整したりする程度ならクライアント側でやるほうがコストがかからないこともあります。
7つのGood patterns
@sue445さんが今までAPIクライアントを実装した経験を通して、APIクライアントを作る際に気をつけるべきことを7つ紹介されていました。
1.依存を少なく保つ
結合を疎にして、依存を少なく保つことでアップデートコストを抑えることができます。
たとえば、GETリクエストをするだけのシンプルなものなら、Ruby標準のopen-uriライブラリだけで十分なものが作れます。
2.Faradayを使う
Faradayは@sue445さん曰く「銀の弾丸」だそうです。
Faraday gemはRuby製のHTTPクライアントライブラリです。Rubyには標準のHTTPクライアントライブラリとしてNet::HTTPがありますが、Faradayの便利なところは、リクエストを送る際のパラメータ受け渡しのインターフェースが扱いやすいことです。Net::HTTPで同様のことをするよりも簡潔で、わかりやすく記述できます。
またFaradayにはMiddlewareという仕組みがあり、これを使うと独自にミドルウェアを拡張できるため、拡張性の高いAPIクライアントを作ることが可能です。Faradayは内部的にNet::HTTPを利用しているため、Net::HTTPのラッパーであると言えますが、他にも数種類のミドルウェアをサポートしています。
@sue445さんはこの拡張性の高さを活用し、レスポンスをbooleanでパースする「FaradayBoolean」という独自のgemを開発し、公開しています。このgemはもともと社内で使っていたそうですが、gemとして切り出すことでOSSとして公開できたとのことでした。
3.どのエンドポイントでも使われるような情報の扱い
認証情報のような、どのエンドポイントでも使う情報はインスタンス変数として保持し、それ以外をパラメータで送るとシンプルに実装できます。
4.ハッシュよりもキーワード引数を使う
args = {}のようにハッシュパラメータを使うと便利ですが、定義されていないパラメータが送られたときにその処理をしなくてはならなくなります。
これをキーワード引数を使うようにすると、必須・任意をRubyで表現できたり、どんなパラメータがあるのかが実装を見るだけで判断できるようになります。
5.パラメータオブジェクトを検討する
パラメータが増えてくると複雑になってしまい、コメントで引数の説明を書く必要が出てきたり、可読性が低下しやすくなります。
パラメータを作るためのクラスを作るとオブジェクト自身にメソッドを持たせることができ、より便利になります。例えば、パラメータを使う前に加工するような前処理をするメソッドを実装して、加工したいときにそのメソッドを呼び出すといった使い方ができます。
さらに、オブジェクトにするとテストを書けるため、信頼性が増します。
6.メソッドアクセスしやすいレスポンスにする
メソッドアクセスできると嬉しい場合が多いです。例えば
first_content_name = contents[0]["name"]
とアクセスするものが、メソッドアクセスが使えると
first_content_name = contents[0].name
と、Rubyらしい書き方ができます。
このように便利な書き方ができるFaraday Middlewareを同時に紹介されていました。
7.curlは万国共通語
APIクライアント開発者にバグレポートを書いたり問い合わせることがあるかもしれませんが、開発者がRubyを知っているとは限りません。
curlは特定のプログラミング言語に依存しませんし、レスポンスが読みやすく、ワンライナーでシンプルに書くことができるためレポーティングに向いています。ただcurlはパラメータが複数ある場合長くなってしまい手間がかかるので、HTTPリクエストをcurlに変換するfaraday_curlというgemを使うと楽に記述できます。curlの実行結果を pbcopyコマンドでクリップボードにコピーされるようにしたりログに記録されるようにしておくと、問い合わせ時に便利です。
今までに作ったAPIクライアントの紹介
@sue445さんが開発したAPIクライアントもいくつか紹介されていました。
Pixela
Pixelaは、Githubのアクティビティのようなピクセル状のグラフを作成できます。
Pixelaは2018年10月14日にローンチされたそうですが、APIクライアントは翌日の15日にリリースされたそうです!速があって素晴らしいですね。
Chatwork Ruby
チャットツールでお馴染みChatWorkのAPIクライアントです。
@sue445さんはもともと利用者側でしたが、何度かプルリクエストを送っていたらメンテナになった、とのことでした。
感想
私が所属する minneにも、様々なAPIクライアントがあります。
まだ自分ひとりでAPIクライアントを実装した経験はありませんが、今後その機会が訪れる可能性がありますし、自分で使うために作ることがあるかもしれません。
今回のセッションの中で一番印象に残ったのは、APIクライアントの責務を「単一責務で、対象のAPIを対象の言語で使いやすくすること」と述べていたことです。
「対象の言語で使いやすくする」を意識し忘れてしまうと、APIクライアントが本来やらなくてもいいような(レスポンスをキャッシュするとか、リクエストパラメータのバリデーションをするとか)機能を持ってしまい、結果的に使いにくくなってしまいそうだと感じました。「使いやすくする」ためにはどんな機能を持っていると良いのか?を考えながら実装するように心がけたいと思います。
また、「疎結合にしてメンテナンス性を高く保つ」ことも大切であると改めて意識させられました。一見当たり前のように感じますが、特定のサービスからしか使われないようなAPIクライアントだと密結合になってしまう危険性は高そうに感じました。APIクライアントとしての使いやすさも大切ですが、アップデートコストを抑えることで提供側として苦しむことが少なくなりそうです。
疎結合にして依存性を少なくすることが重要であるということは、APIクライアント以外にも言えることかもしれませんね。
@sue445さんのこのセッションで述べられていたことを考慮しながら、APIを使う人が実装しやすくメンテナンスする人が苦しまないような、みんなが幸せになれるAPIクライアントを作れるようになろうと思いました。
内容がぎっしり詰まっていて、最高のセッションでした!
私からのレポートは以上です。お読みいただきありがとうございました。それでは次にバトンタッチしたいと思います!
The send-pop optimisation
こんにちは、西のモーリス・グリーンこと @pyama86 です。僕のターンでは、@shyouhei さんのセッションについてレポートをお届けします。
資料はこちらです。
該当のPRは#2100です。
概要
Rubyはメソッド呼び出し時に戻り値を利用しない場合であったとしても、何らかの値をレシーバーに返却します。利用しない値なのに、そういった挙動をするのは時間とメモリを浪費するので、それらを最適化する仕組みを作り、ベンチマークを取り、優位性を示したというトークでした。
まずこのトークの中で何度も出てくる send、pop とはなんでしょうか?Rubyの言語開発者ではない多くの方にとってはよくわからない言葉だと思うのですが、結論から述べるとsendはメソッド呼び出しを行うYARV命令で、popはスタックから値を一つ取り出すYARV命令です。
「え?よくわからないんだけど・・・」
というかたは、今すぐ Rubyのしくみを買うと良いでしょう。内容自体は古い箇所も多いのですが、概念の理解や、Rubyの処理系に踏み込むにあたり、有益な情報が体系的にまとまっており、とてもいい本でした。
Rubyのしくみにも記載がありますが、RubyのコードからYARV命令を見るには下記のようなコードを実行すると確認できます。
#!/bin/ruby
code = <<-EOS
def something
'give'
end
def something_another
'me'
end
def something_else
'a chance'
end
def foo
something
something_another
return something_else
end
foo
EOS
puts RubyVM::InstructionSequence.new(code).disasm
実行してみましょう。また普通に実行するとsendは最適化された命令が呼ばれるので置換します。
$ ruby yarv.rb | gsed 's/opt_send_without_block/send/g'
#...snip
== disasm: #<ISeq:foo@<compiled>:13 (13,0)-(17,3)> (catch: FALSE)
0000 putself ( 14)[LiCa]
0001 send <callinfo!mid:something, argc:0, FCALL|VCALL|ARGS_SIMPLE>, <callcache>
0004 pop
0005 putself ( 15)[Li]
0006 send <callinfo!mid:something_another, argc:0, FCALL|VCALL|ARGS_SIMPLE>, <callcache>
0009 pop
0010 putself ( 16)[Li]
0011 send <callinfo!mid:something_else, argc:0, FCALL|VCALL|ARGS_SIMPLE>, <callcache>
0014 leave ( 17)[Re]
このように、メソッド呼び出しをして、戻り値を利用しないのにスタックから戻り値を取り出している様子がわかると思います。
改善手法 - opt_bailoutの追加
このトークではいくつかの手順で改善を行うという提案がなされました。まずは戻り値が利用されないことをメソッドに伝えるために、 VM_FRAME_FLAG_POPPED というフラグを追加しています。これにより戻り値をしない場合は、YARV命令 opt_bailout が命令シーケンスに追加されます。
# refs: https://github.com/ruby/ruby/pull/2100
== disasm: #<ISeq:foo@<compiled>:1 (1,2)-(4,5)> (catch: FALSE)
local table (size: 2, argc: 1 [opts: 0, rest: -1, post: 0, block: -1, kw: -1@-1, kwrest: -1])
[ 2] x@0<Arg> [ 1] y@1
0000 putself ( 2)[LiCa]
0001 getlocal x@0, 0
0004 send <callinfo!mid:bar, argc:1, FCALL|ARGS_SIMPLE>, <callcache>, nil
0008 opt_bailout 1
0010 setlocal y@1, 0
0013 getlocal y@1, 0 ( 3)[Li]
0016 leave
opt_bailoutについては、実装に記載されているコメントが詳しいです。
This instruction is no-op unless the instruction sequence is called with VM_FRAME_FLAG_POPPED. With that flag on, it immediately leaves the current stack frame with scratching the topmost n stack values.The return value of the iseq for that case is always nil.
僕は実装から、opt_bailoutが呼ばれるとスタックの上位からN個の値を取り出し、代わりにnilをpushし、現状のスタックフレームを離脱すると理解しました。 これにより不要な戻り値設定の setlocal を避けることができ、これらは常にnilを返すように振る舞うようになります。
またこの手法の適用において、C言語で実装されたメソッドについては現状の提案では内包されていませんが、将来C言語のコードから利用できるようなAPIを提供するという紹介がありました。
改善手法 - pop削除
先の opt_bailout により、不要な setlocal は抑制できるようになりましたが、依然としてスタックから利用しない値を取得しようとする pop については残されたままです。最適化するために、 pop を削除するにあたり、削除してはならないケースがあります。資料中のコードを引用します。
def foo
self &. x
nil
end
このコードの命令シーケンスはこのようになります。
== disasm: #<ISeq:foo@<compiled>:1 (1,0)-(4,3)> (catch: FALSE)
0000 putself ( 2)[LiCa]
0001 dup
0002 branchnil 7
0004 send <callinfo!mid:x, argc:0, ARGS_SIMPLE>, <callcache>
0007 pop
0008 putnil
0009 leave
注目すべきは branchnil 命令です。この命令は、スタックから取り出した値が nilの場合、指定した番号にジャンプします。この場合、 self &. x で x というメソッドが存在しない場合は、 send できないので、 pop までジャンプすることになるわけです。このときに pop を消してしまうと、ジャンプ先がなくなるため、削除してはならないということになります。
これを避けるため、 VM_FRAME_FLAG_POPIT というフラグが追加されています。このフラグはpopが最適化されているか否かのフラグで、このフラグが設定されている場合、呼び出し先はpush をスキップする必要があります。呼び出し先がスキップせずに push してしまうと、 popが最適化されているため、取り出されない値がスタックに push されることになるので、以降の pop がずれてしまいます。
また、トーク中で説明された lambda のケースは、そもそも return の挙動の違いを僕自身は知らなかったのですが、この挙動を実現するためにフラグを元に大域脱出の挙動を変える実装が行われていました。僕が読んだ感じだと、大域脱出するときに、popが最適化されてない場合のみ、スタックに戻り値を積むという実装に見えます。
最後に
ここまで記述した内容の後に、ベンチマーク結果の紹介がありましたが、それらはQA含めてYouTubeで公開された後に見るのが良さそうなので、このレポートでは扱いません。
僕自身はこのトークを聞いて、自分が知らないRubyの処理系世界への興味を掻き立てられ、理解するために書籍を買って読んだり、コミッターのブログを読み漁ったり、さらに多くのインプットをすることができました。
自身が登壇する際もトークだけではなく、聞き手が本質的に興味を持てる、そんな話ができるようになりたいなと思った次第です。 それでは次の方にそろそろバトンをお渡しします。
See you next time bye bye!
Red Chainer and Cumo: Practical Deep Learning in Ruby
こんにちは!@kurotakyです。 @sonotsさんと@hatappiさんによるRed Chainer and Cumo: Practical Deep Learning in Rubyの発表についてレポートを書きます。
Chainerについて
ChainerはPreferred Networksが開発したPython製のDeep Learningライブラリです。 Chainerの他にはTensorFlow, MXNetがあり、Ruby製だとRed Chainer, TensorFlow.rb, MXNet.rb, menoh-rubyというライブラリがあります。 この発表ではRuby製のChainerとして開発されているRed Chainerの話がありました。
Red Chainer
Rubyで楽しくDeep Learningをしたい!というのが開発をはじめたきっかけのようです。機械学習に関する処理をRubyで書きたい人にとってはとても嬉しいですね。 しかし、問題点は大きく2つあります。1つ目はスピードです。こちらは後半の@sonotsさんの発表で出てきましたが、GPUを使ってすばやく実行できるように対応しています。 もう1つは、すでにChainerを使って学習したモデルやパラメータがあったとしてもRed Chainerでは使えないという点です。 その問題を解決するために、ONNX(Open Newral Network Exchange Format)というExchange Formatの話へ続きます。
ONNX と Protocol Buffers
ONNXは開発者が自分のプロジェクトに適したツールの組み合わせを使用して、すばやく研究開発で活用できるようにするのが狙いのようです。Chainerで学習させたモデルをエクスポートして、他のフレームワークでインポートできるようになります。開発者が1つのフレームワークやエコシステムに閉じないで目的に合ったフレームワークを選択できるのは良いですね。menoh-rubyではONNXを使っているそうです。
コンテンツはProtocol Buffersで表現されています。Protocol Buffersは言語やプラットフォームに依存せずに構造化されたデータをシリアライズできるメカニズムです。2008年にGoogleによってOSSコミュニティでリリースされました。@hatappiさんはONNXファイルから学習済みパラメータとモデルをRubyのコードで出力できるONNX-Red-Chainerというライブラリも作成しています。
Cumoについて
CumoはRubyのNumoをGPU対応したものです。 高速化のためにGPUなら3000~4000コアを活用できるためRed Chainerに統合されました。MNISTのexampleでCumo使って試したら75倍速くなったそうです。
CNN と cuDNN
CNN(Convolutional Newral Network)は主に画像認識に利用される畳み込み演算を使ったニューラルネットワークです。 2012年の大規模画像認識コンテストでAlexNetと呼ばれるCNNを用いた手法が優勝し、ディープラーニングは有名になりました。 もっと詳しく知りたい方は畳み込みニューラルネットワークの最新研究動向 (〜2017)のサーベイを参考にしましょう。
cuDNNはNVIDIAが公開しているDeep Learning用のライブラリです。ChainerなどのDeep Learning用のソフトウェアの処理を高速化できます。 これは低レベルのGPUパフォーマンスチューニングに費やす時間を減らし、ニューラルネットワークのトレーニングとアプリケーションの開発に集中できるようになるので良いですね。 アルゴリズムはDirectとか、FFTとかいろいろなアルゴリズムがありますが、入力のイメージサイズによって動的に選ぶ必要があります。cuDNNはAuto tuneをサポートしているので、インプットデータに対してすべてのアルゴリズムを試して、一番速いものを選ぶことができます。
ChainerX
ChainerXはC++で書かれたNumPyのようなライブラリで、Chainerと比較するとPythonのオーバーヘッドを減らすことができてスピードアップできているようです。
- モデルの実行を高速化
- Pythonの無い環境でもデプロイ可能にする
- CPU/GPU以外への移植を容易にする
といったことが実現できています。
Pythonのバインディングと同じようにコア部分を再利用してRubyでもNumPyライクなAPIを作る可能性についてはGoogle Summer of Code 2019 Project Ideasの課題になっています。興味がある方は是非トライしてみましょう!
MNISTを実行してみた
ここまでRed ChainerとCumoに関する発表のレポートでした。ここからは実際に筆者が2つのライブラリを試した結果を載せていきます。 Red ChainerとCumoを使ってMNISTの手書き数字認識の速度を比較するためにGoogle Colaboratoryを使ってCPUとGPU上で実行してみました。
CPUを使って実行した場合
Cumoを使わずに以下のコマンドで実行しました。
!bundle exec ruby examples/mnist/mnist.rb
実行した結果を以下に記載します。
GPU: -1
# unit: 1000
# Minibatch-size: 100
# epoch: 20
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
total [..................................................] 0.83%
this epoch [########..........................................] 16.67%
100 iter, 0 epoch / 20 epochs
Inf iters/sec. Estimated time to finish: 00:01:00.
total [..................................................] 1.67%
this epoch [################..................................] 33.33%
200 iter, 0 epoch / 20 epochs
1.9403 iters/sec. Estimated time to finish: 01:01:21.
total [#.................................................] 2.50%
this epoch [#########################.........................] 50.00%
300 iter, 0 epoch / 20 epochs
1.9652 iters/sec. Estimated time to finish: 01:01:13.
total [#.................................................] 3.33%
this epoch [#################################.................] 66.67%
400 iter, 0 epoch / 20 epochs
1.957 iters/sec. Estimated time to finish: 01:01:47.
total [##................................................] 4.17%
this epoch [#########################################.........] 83.33%
500 iter, 0 epoch / 20 epochs
1.9388 iters/sec. Estimated time to finish: 01:01:51.
1 0.19515 0.0909134 0.940017 0.9714 329.256
total [##................................................] 5.00%
this epoch [..................................................] 0.00%
600 iter, 1 epoch / 20 epochs
1.8036 iters/sec. Estimated time to finish: 01:01:20.
total [##................................................] 5.83%
this epoch [########..........................................] 16.67%
700 iter, 1 epoch / 20 epochs
1.8277 iters/sec. Estimated time to finish: 01:01:02.
total [###...............................................] 6.67%
this epoch [################..................................] 33.33%
800 iter, 1 epoch / 20 epochs
1.8406 iters/sec. Estimated time to finish: 01:01:24.
total [###...............................................] 7.50%
this epoch [#########################.........................] 50.00%
900 iter, 1 epoch / 20 epochs
1.8543 iters/sec. Estimated time to finish: 01:01:46.
total [####..............................................] 8.33%
this epoch [#################################.................] 66.67%
1000 iter, 1 epoch / 20 epochs
1.8579 iters/sec. Estimated time to finish: 01:01:40.
total [####..............................................] 9.17%
this epoch [#########################################.........] 83.33%
1100 iter, 1 epoch / 20 epochs
1.8641 iters/sec. Estimated time to finish: 01:01:27.
2 0.0739598 0.0755575 0.976966 0.9774 660.461
時間がかかりそうなので、この辺で終了しました。1epochあたり約330秒かかりました。
GPUを使って実行した場合
ランタイム > ランタイムのタイプを変更からハードウェア アクセラレータをGPUに選択して以下のコマンドで実行しました。
!bundle exec ruby examples/mnist/mnist.rb --gpu 0
実行結果を以下に記載します。
1epoch
GPU: 0
# unit: 1000
# Minibatch-size: 100
# epoch: 20
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
total [..................................................] 0.83%
this epoch [########..........................................] 16.67%
100 iter, 0 epoch / 20 epochs
Inf iters/sec. Estimated time to finish: 00:01:00.
total [..................................................] 1.67%
this epoch [################..................................] 33.33%
200 iter, 0 epoch / 20 epochs
123.88 iters/sec. Estimated time to finish: 00:01:35.
total [#.................................................] 2.50%
this epoch [#########################.........................] 50.00%
300 iter, 0 epoch / 20 epochs
126.02 iters/sec. Estimated time to finish: 00:01:32.
total [#.................................................] 3.33%
this epoch [#################################.................] 66.67%
400 iter, 0 epoch / 20 epochs
124.87 iters/sec. Estimated time to finish: 00:01:32.
total [##................................................] 4.17%
this epoch [#########################################.........] 83.33%
500 iter, 0 epoch / 20 epochs
123.07 iters/sec. Estimated time to finish: 00:01:33.
1 0.192718 0.104356 0.941734 0.9686 6.10886
total [##................................................] 5.00%
20epochまで実行した結果
this epoch [########..........................................] 16.67%
11500 iter, 19 epoch / 20 epochs
107.8 iters/sec. Estimated time to finish: 00:01:04.
total [################################################..] 96.67%
this epoch [################..................................] 33.33%
11600 iter, 19 epoch / 20 epochs
107.83 iters/sec. Estimated time to finish: 00:01:03.
total [################################################..] 97.50%
this epoch [#########################.........................] 50.00%
11700 iter, 19 epoch / 20 epochs
107.9 iters/sec. Estimated time to finish: 00:01:02.
total [#################################################.] 98.33%
this epoch [#################################.................] 66.67%
11800 iter, 19 epoch / 20 epochs
108.34 iters/sec. Estimated time to finish: 00:01:01.
total [#################################################.] 99.17%
this epoch [#########################################.........] 83.33%
11900 iter, 19 epoch / 20 epochs
108.39 iters/sec. Estimated time to finish: 00:01:00.
20 0.0101987 0.112854 0.996899 0.9828 111.404
total [##################################################] 100.00%
this epoch [..................................................] 0.00%
12000 iter, 20 epoch / 20 epochs
108.03 iters/sec. Estimated time to finish: 00:01:00.
1epochは約6秒で、20epochが約111秒で終了できました。速い!!!私の実験環境では約55倍速くなりました。 動かしたときのサンプルはこちらに置いておきます。
まとめ
今まで機械学習系のライブラリは他の言語が強いイメージがありましたが、現在はRed Data ToolsというRuby用のデータ処理ツールを提供するプロジェクトによって色々なライブラリが作られてメンテナンスされています。Red ChainerとCumoを使ってRubyでも楽しくDeep Learningしていきましょう!
Better CSV processing with Ruby 2.6
こんにちは。@mao_sum ことtositeです。
好きなマクロスのキャラはランカちゃんです。
私は2日目の @ktou さんと @284km さんのセッション、 Better CSV processing with Ruby 2.6 についてレポートさせていただきたいと思います。
資料はこちらです。
https://slide.rabbit-shocker.org/authors/kou/rubykaigi-2019/
概要
こちらのセッションでは、Ruby2.6へのアップデートに際しCSVライブラリがどのようにして高速化に至ったのか、その経緯などを対話形式で面白くご紹介されていました。
どの程度高速化できたのか
先に結論からお伝えします。
読み込み
| 項目 | Ruby2.5 | Ruby2.6 | 対比 |
|---|---|---|---|
| A. クォートなし | 432.0 i/s | 764.9 i/s | 1.77倍 |
| B. クォートあり | 274.1 i/s | 534.4 i/s | 1.95倍 |
| C. 区切り文字クォート-1 | 211.0 i/s | 330.0 i/s | 1.56倍 |
| D. 区切り文字クォート-2 | 118.7 i/s | 325.6 i.s | 2.74倍 |
| E. マルチバイト | 371.2 i/s | 626.6 i.s | 1.69倍 |
使用したデータ
と、このように 約1.5倍〜2.7倍 程度の高速化が図られています。
その中でも特筆すべきは、区切り文字が入るなどCSVデータが複雑化した場合の速度が変わっていない点です。
なお、2.6のスコアでも B. クォートあり の場合のみ 534.3 i/s と、他と比べ1.6倍ほど速いですが、こちらは単純なクォートありのデータ用にロジックを最適化した結果だそうです。
書き出し
| 項目 | Ruby2.5 | Ruby2.6 | 対比 |
|---|---|---|---|
| a. CSV.generate_line | 284.4 i/s | 684.2 i/s | 2.41倍 |
| b. CSV#« | 2891.4 i/s | 4824.1 i/s | 1.67倍 |
サンプルコード
このように書き出し処理も 約1.7〜2.4倍 の高速化が図られましたが、特に b. CSV#<< の速度に注目していただきたいです。
この差異は複数行の書き出しを行う際に顕著に現れてます。
複数行を書き出す場合、 << を使うことによってRubyのバージョンによらず高速化が図れるとのことです。
参考:KEN_ALL.csv
皆さん、 KEN_ALL.csv はご存知でしょうか?
そう、日本郵便株式会社のページからダウンロードできる、住所データですね。
ref: https://www.post.japanpost.jp/zipcode/download.html
| データサイズ | 列数 | 行数 |
|---|---|---|
| 11.7 MiB | 15 | 124,259 |
こちらのデータをパースしてみたところ、以下の結果となったようです。
| Ruby2.5 | Ruby2.6 | 対比 |
|---|---|---|
| 1.17 s | 0.79 s | 1.48倍 |
この結果からも高速化されていることが分かりますね。
どのようにして高速化したのか
複雑なクォートに対しての処理
| 項目 | Ruby2.5 |
|---|---|
| A. クォートなし | 432.0 i/s |
| B. クォートあり | 274.1 i/s |
| C. 区切り文字クォート-1 | 211.0 i/s |
| D. 区切り文字クォート-2 | 118.7 i/s |
この表からもお分かりかと思いますが、Ruby2.5ではCSVのクォートが複雑になればなるほど速度が低下していました。
その問題を解決するべく、Ruby2.5まではCSVのパースに String#split のみを利用していましたが、Ruby2.6からは StringScanner も使用するようにしたとのことです。
それぞれのメリット・デメリット
String#split
- 単純なデータの場合、高速に処理ができる
- データが複雑になればなるほど処理速度は低下する
- 複雑なデータの場合、コードはより複雑になる
StringScanner
- 複雑なデータでも処理速度の低下がほぼ見られない
- コードが見やすく、保守性が上がる
- 反対に単純なデータの場合、
String#splitほどの速度は出ない
ということで、単純なデータの場合は今までどおり String#split を使用してパースを行い、複雑なデータの場合は StringScanner を使用してパースすることで処理速度の向上を図ったとのことでした。
ロジック的には 1.最適化したバージョンのパースを試し 、複雑なCSVであると判断した場合は 2.現行のバージョンにフォールバック することで対応しているそうです。
遅延読み込み
Ruby2.5ではインスタンス生成時に、利用する・しないに関わらず読み込み・書き込みの初期化処理を行っていたそうです。
しかしながらRuby2.6では読み込みの場合は読み込みの、書き込みの場合は書き込みの初期化処理のみを行うことで高速化を図っています。
今後の展望
以上、速くするためにさまざまな取り組みを行われていますが、文字コードのエンコーディング変換処理に高速化の余地があること、シンプルなケースの場合のパース処理をC言語で実装して高速化したいことなど、今後改善していきたいことなどを挙げられていました。
まとめ
セッションを聞く中で、特に印象的だったのが ベンチマークを計測することで性能劣化バグを防ぐ というものでした。
私も普段から、他のエンジニアの方が仕様を理解しやすいよう、バグを混入させないようテストは書いていますが 性能劣化バグ という観点はありませんでした。
また、ベンチマークの導入により実際に遅い処理が可視化できるため、今後の機能改善にも役立ちそうだなという印象です。
RubyKaigiへの参加は初めてでしたが、セッションが主に英語であることを始め、たくさんの刺激を受けました。
と同時に来年のRubyKaigiまでにはもっとRubyへの理解を深めるとともに英語力を高め、もっと楽しみたいと思いました。
それでは次の方、よろしくお願いいたします!
How to use OpenAPI 3 for API developer
こんにちは、SUZURIでアプリケーション開発を行っているtokkyです。私からはDay1の太田さん(@ota42y)のセッション How to use OpenAPI 3 for API developerについてレポートします。
発表資料のリンクはこちらです。 How to use OpenAPI 3 for API developer
昨今ではWebアプリとモバイルアプリで同等の機能を提供したり、Single Page Application(SPA)を作ったり、サービスをマイクロサービス化させていくために、多くのREST APIを開発することを求められるようになってきました。 このセッションでは、OpenAPI 3を使ってスキーマを定義し効率よく開発を行う方法、そしてOpenAPI 3をうまく扱うために太田さんが貢献した内容についての説明がありました。
OpenAPI 3
OpenAPI 3とはOpenAPI Specification ver 3.0.0とも呼ばれる、REST APIを記述するための規格です。
OpenAPI 3の特徴としては、
- 記述できるルールは、マシンリーダブルである
- YAML/JSON形式で定義を記述できる
といったものが挙げられ、その定義ファイルを使ってドキュメントを生成したり、モックサーバを作ったりできます。
OpenAPI 3以外にも、スキーマを定義する手段としては、
- JSON Hyper-Schema
- GraphQL
- gPRC
などがあります。
The OpenAPI 3 specification
例えば、以下のようなAPIを実装することを考えます。
これはSinatraのルーティング定義です。
/appsにGETメソッドでリクエストをすると、JSONを返す簡単なAPIです。
このAPIはpageという名前のIntegerパラメータを要求し、レスポンスはstringの配列を含みます。
get "/apps" do
content_Type :json
# page should be Integer
page = params["page"].to_i
[page, (page*10)].map(&:to_s).to_json
end
これをOpenAPI 3で記述すると、以下のようになります。
openapi: 3.0.0
info:
title: Sample API
version: 0.1.0
paths:
"/apps":
get:
parameters:
- name: page
in: query
required: true
schema:
type: integer
responses:
'200':
description: example
content:
'appliation/json':
schema:
type: array
items:
type: string
OpenAPI 3はinfoとpathsという、2つの要素を必須とします。
infoにはAPIに関するメタデータなどを記述します。
pathsはAPIの定義が記述される重要なセクションです。
pathsは、複数のPath stringとPath Item Objectのペアから構成されます。
Path stringとはそのAPIのパス名を表し、Path Item ObjectとはそのAPIのリクエスト/レスポンスパラメータをHTTPメソッド単位で記述します。
上記の例では/appsというパスにGETメソッドでリクエストを送信した時に必要なパラメータやレスポンスのコード、返り値のスキーマ定義が記述されています。
この二つ以外にも、いくつかの要素を記述できます。
servers
記述されているスキーマに基づいて動作するサーバの情報を記述できます。 StagingとProductionでURLが違うような場合などに使用します。
components
スキーマファイル内で再利用可能なオブジェクトを記述できます。
複数のpathsで同一のオブジェクトを受け渡ししている場合などに使用します。
security
どのようなセキュリティ設定を利用するかを記述できます。 OAuth2などをAPIに設定する場合に使用します。
tags
スキーマファイル内で利用されるタグ情報を一括で記述できます。
ここで記述したタグは、paths内で記述されるAPIのグルーピングに使用できます。
tags要素に記述しなくても問題はないのですが、このセクションに記述しておくことで一括管理できるメリットがあります。
externalDocs
外部リソースへの参照情報を記述できます。 APIのより詳細なドキュメントへのURLを記述することが多いでしょう。
OpenAPI is definition
OpenAPI 3はAPIの定義を記述した単なるYAML/JSONファイルであり、ファイル単体で何かを行うことはできません。 しかし、マシンリーダブルであるこのスキーマ定義ファイルを特定のツールと組み合わせて使うことで、API開発の効率を大幅に高めることができます。
OpenAPI 3でスキーマを記述することで、下記のような機能を持ったツール群を利用できるようになります。
- リクエスト/レスポンスのバリデーション
- APIドキュメントの生成
- モックサーバの起動
- クライアントライブラリ
特に、スキーマのバリデーションは、定義と実装のズレがないことを確認するためには大変重要な機能です。 そこで利用されるのが、committeeというRuby gemです。
committeeは、Rackミドルウェアとして動作し、リクエストされたURLがスキーマ定義に存在していれば、バリデーションを実行します。
例えば、リクエストに必要なパラメータが存在しなかったら、committeeはエラーを返します。 さらに、APIサーバが返すレスポンスがスキーマに記述されているレスポンス定義と一致しない場合もエラーを返してくれます。 committeeを使うことで、すでに用意されているスキーマに沿って円滑に開発を進めることができますね。
How to implement request/response validator using OpenAPI 3
このように、committeeは強力なバリデーション機能を提供してくれますが、元々はJSON Hyper-SchemaとOpenAPI 2のバリデーションにしか対応していませんでした。 そのため、太田さんがOpenAPI 3を使った新しいバリデーション機能をcommitteeに追加しました。
committeeはOpenAPI 2をいったんJSON Hyper-Schemaに変換した上でバリデーションを実行していたため、バリデーターはJSON Hyper-Schemaに密結合している状態でした。 具体的には太田さんの発表資料もしくはこちらの記事を見ていただくのが良いと思いますが、この場で大まかに説明すると、JSON Hyper-Schemaに依存していた部分を、抽象化されたスキーマクラスに依存するように変更することで「どのスキーマで記述されているか」をcommittee側で意識する必要がない状態にしたそうです。
Other OpenAPI 3 Tools
OpenAPI 3そのものの紹介以外にも、OpenAPI 3を用いてWebアプリケーション開発を行う上で便利なツールの紹介がいくつかありました。
その中で紹介されたSwagger Editorは、OpenAPI 3を記述するためのエディタです。
記述しているYAMLにエラーがないかどうかをチェックしてくれるだけではなく、OpenAPI 3のスキーマ定義を記述するとブラウザ上に自動でドキュメントを生成してくれ、その場でスキーマ定義のテストや、記述したAPIに対してcurlでテストを行う場合のコマンドを生成する機能を提供してくれます。
例えば、以下のようなスキーマを記述すると、
openapi: 3.0.1
info:
title: Sample API
version: 0.1.0
paths:
"/api/v1/users":
get:
responses:
'200':
description: example
content:
'appliation/json':
schema:
type: array
items:
type: string
"/api/v1/users/{id}":
get:
parameters:
- name: id
in: path
required: true
schema:
type: integer
responses:
'200':
description: example
content:
'appliation/json':
schema:
type: array
items:
type: string
このようなドキュメントを自動生成してくれます。
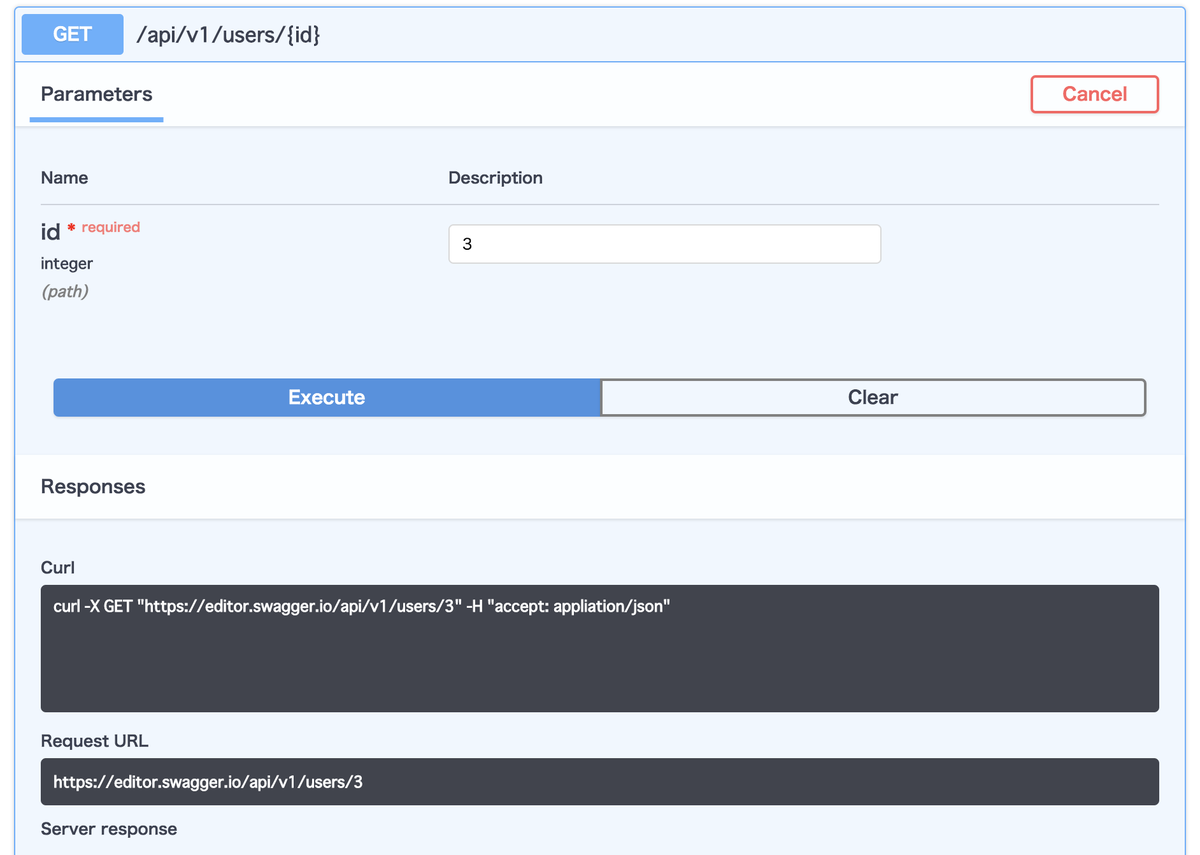
テストを行う際にはcurlを頻繁に使うので、このようなコマンド自動生成機能があるとAPI開発もスムーズに進むと感じました。
おわりに
OpenAPI 3は定義と実装の乖離を防ぎ、様々な便利なツールと組み合わせることでAPI開発の効率を高めてくれることがこのセッションで分かりました。
また、太田さんがcommitteeをJSON Hyper-Schemaへの密結合から解消するアプローチや、OpenAPI 3のスキーマをパースするopenapi_parserの内部実装に関する説明がとても面白く、見所の多いセッションでした。
私からのレポートは以上です。次の方にバトンを回したいと思います。
Pragmatic Monadic Programming in Ruby
こんにちは、ryoma123 です。私からは Day1 の @joker1007 さんのセッション Pragmatic Monadic Programming in Ruby についてレポートします。
発表資料はこちらです。
こちらのセッションでは、関数型言語の特徴であるモナドを Ruby で実装するというチャレンジングなトークを聞くことができました。「黒魔術」の一つの手法として、TracePoint と AST を利用した技巧的な実装方法についても丁寧に解説されています。
それでは発表内容をふりかえっていきます。
Ruby と関数型言語
はじめに、Ruby の持っている関数型プログラミングの特徴を紹介しています。
今回の実装で利用する RubyVM::AST.of と TracePoint#enable は引数に Proc を受け取ることができます。手続きオブジェクトである Proc はクロージャーの性質を持っており、メソッドはブロックを Proc オブジェクトとして受け取ることができます。関数オブジェクトとも言い換えられますね。
以下の Ruby の特徴を踏まえると、関数型プログラミングの要素も持ち合わせています。
- 第一級オブジェクトに関数オブジェクトを持つ
- 戻り値として関数を受け取る
- メソッド引数に関数を渡す
モナド
つぎに、関数型言語の特徴の一つであるモナドの紹介です。関連する抽象概念として Functor と Applicative Functor を取り上げています。
Functor は箱であり、目的のための文脈を持っています。そして、関数をマッピングできるオブジェクトです。利便性としては、あらゆるメソッドと連携できる点にあります。 Applicative Functor は関数を含むことができます。しかし、複数の依存を扱うことができません。モナドは前の計算の結果が次の計算に影響をおよぼす場合など、文脈をうまく扱いたい場合に便利です。
以下のコードは Haskell におけるモナドの実装例です。モナドを関数に渡す bind 演算子が特に重要であると伝えています。
class Monad m where
(>>=) :: m a -> (a -> m b) -> m b
...
これは、配列における flat_map を意味します。各要素を受け取り、新しい配列を出力する関数を受け取ります。
["foo", "bar"].flat_map { |s| s.split(//) }
# => ["f", "o", "o", "b", "a", "r"]
Scala においても内部では flat_map 形式に変換していることを紹介し、今回の実装においても同様のアイデアを採用しています。
糖衣構文
関数型言語にはモナドの糖衣構文を持っているものがあり、Haskell の do 構文、Scala の for 構文がそれに当たります。文脈計算の連鎖であるモナドでは、糖衣構文を利用するとより簡単に実装できます。それに、flatMap をネストしたコードはリーダブルではありませんよね。
a <<= <statement>transform toflat_map do |a| <statement>It’s all.
そこで、Scala のコード変換を参考にしました。 <<= は演算子による代入なので Ruby の構文として有効です。警告もありません。
先に紹介した Ruby 2.6 の新機能である RubyVM::AST.of を利用することで、AST 処理を実装することができます。
実装
具体的な実装方法を紹介します。
RubyVM::AST.ofを利用してブロックから AST を抽出a <<= fooのようなパターンを検出- ソースコードの断片を抽出
- ソースコードを再構築
- 新しい proc にラップする
instance_evalの新しいソースコード
ここで、ローカル変数の持ち回りに課題がありました。再構築したコードは元のブロックに含まれていた環境が失われてしまうため束縛が必要になったのです。
先に紹介した TracePoint を利用して、与えられたブロックの束縛を得るテクニックを発見しました。これにより、proc の束縛が得られたので、生成された proc にローカル変数をコピーすることができます。
モナド構文
主要なモナド構文の実装を紹介しています。Maybe、Either、Future、State、ParserCombinator の実装例を取り上げ、最後に算術演算のパーサを動作させるデモがありました。
余談になりますが、私 ryoma123 の手元で Monar::Maybe モジュールを利用してみたところ Just と Nothing の返り値を確認することができました。便利ですね!
...
calc = ->(val) do
Just(val).monadic_eval do |x|
a = x
y <<= pure(a + 14)
z <<= case y
when :prime?.to_proc
Just.new(y)
when 20
Just.new(y)
else
Nothing.new
end
pure z
end
end
p calc.call(3) #<Monar::Maybe::Just:0x00007ff5838528b8 @value=17>
p calc.call(6) #<Monar::Maybe::Just:0x00007ff583852458 @value=20>
p calc.call(2) #<Monar::Maybe::Nothing:0x00007ff583852110>
※ 使い方は変更される可能性があるため、Gem の本番利用はまだ推奨されていないようです。
最後に
TracePoint と AST を利用した実装方法の紹介、「闇」プログラミングの楽しさを伝えるセッションとして締めくくられています。
let’s enjoy darkness programming!!
レポートは以上です!
感想
Ruby の奥深さを感じたセッションでした。「黒魔術」には高度で驚くようなテクニックが数多く登場しますが、技術的な挑戦だけではなく、Ruby 2.6 の新機能を活用したいという動機など、純粋に Ruby というプログラミング言語を楽しんでいるような印象を強く受けました。
自分も引き続き Gem を作るなどして Ruby を楽しみ、何かしらの形でコミュニティに貢献できるようになっていきたいと思いました。ありがとうございました!
Vol.2の終わりに
以上、ペパボのRubyKaigi 2019レポートの第2弾をお届けしました。
たくさんのセッションを聞いたことで今まで知らなかった技術の情報に触れることができ、たくさんの刺激を受けました!社外のRubyistとの交流もあり、貴重な経験になったと感じています。
前回の参加レポートも含め計12名がレポートしましたが、今回25名のエンジニアが参加しました。今後もどんどんイベントに参加し、たくさんのレポートをお届けできればと思います。
またRubyKaigiへの参加だけではなく、ペパボではRubyを利用した開発が積極的に行われています。RubyKaigi 2019で刺激を受けたそこのあなた、ぜひ一緒に働きましょう。そして来年は一緒にRubyKaigiに参加しましょう。
それではまた来年お会いしましょう!最後までお読みいただきありがとうございました!



