
- 開発合宿のすゝめ
- 成果発表
- ProxySQL ClusterをKubernetesで構築および運用するツール開発および技術検証 / @drumato @ressy
- ProxySQLのミラークエリの検証 / @yuchi
- rc (プロキシキャッシュ)のパフォーマンスチューニング / @k1LoW
- Kunaiの検証 / @n01e0
- カラーミーショップのPOP/IMAPサーバーをCourier-IMAP+qmail-pop3dからDovecotにする / @tnmt
- アクセスログベースでAnalysisRunを実行しCanary releaseできるようにする / @naryo @ryu-ch
- OpenDKIMでのなりすまし防止の実装 / @gurasan(Ryuichi Watanabe)
- Amazon RDSの監査ログをCloudWatch Logsを介さずにS3へ保存したい / @harukin
- EKSにおけるpreview環境の実装 / @shibatch(Kohei Shibata)
- AIにログを食わせて確率的な判断をしてもらうくん / @pochy
- ボットのアクセスを判定するAPIの開発 / @pyama
- Kubernetes Custom Controller の挙動を人間が再現できる CLI ツールの実装 / @takutaka
- まとめ
開発合宿のすゝめ
なぜ開発合宿をするのか
技術部プラットフォームグループのリューちゃんです。
GMOペパボでは多くのサービスを提供しております。技術部プラットフォームグループ(以降PFG)はSREロールとして横断的にさまざまなサービスの信頼性を担保できるように努めております。
現在PFGには遠方在住パートナーもおり、リモートをメインとして日々の業務を行っています。またPFGをチームに分割して担当しているため同じ部署ではあるものの、担当しているサービス(チーム)以外のパートナー(一緒に働く仲間のこと)との日頃の接点が少ないという状況があります。
チームを超えてサービスの信頼性についてオフラインでディスカッションしたり開発を行ったりするという場も少なく、それぞれのノウハウを共有する機会があまり多くないと感じています。
そこで横断組織としてのシナジーを活かすため開発合宿を企画いたしました。
なぜ沼津なのか
 開発合宿をする以上、リラックスした環境で挑みたいと考えました。
開発合宿をする以上、リラックスした環境で挑みたいと考えました。
まず沼津は富士山が一望でき、港の近くで美味しい新鮮な魚介類を食べることができる環境であることが挙げられます。
またリモートメインのパートナーの居住地と間をとることができるというのも大きな理由です。
成果発表

ProxySQL ClusterをKubernetesで構築および運用するツール開発および技術検証 / @drumato @ressy
ProxySQLをクラスタリングし、設定共有や管理を分散共有できる仕組みである ProxySQL Cluster を本番運用するために、 プラクティカルに管理・運用するためのツールであるproxysqlupというCLIツールを開発しました。 また、ProxySQL Clusterの挙動や設定方法、本番運用するうえで起こりうる障害ケースを想定したデモなどを実施しました。
私達はこれまでProxySQLを各アプリケーションサーバに同居させる、あるいはアプリケーションコンテナのサイドカーとして運用してきましたが、 DBインスタンスのサービスイン/アウトや、バックエンドのMySQLに対する重みの設定変更など、 運用上頻繁に起こるタスクに対しpuppetの変更→デプロイ→適用→メトリクス等をモニタリングして監視というフローを取ってきました。
これはタスクの実施スピードが出づらいという上に、 1アプリケーションインスタンスに対しProxySQLが1台という専任構造を取ってしまっていました。
これらの現状から、ProxySQL自体の可用性を高めつつ、 設定変更にかかる時間を短縮し、またアップグレード等作業も簡素化しようと、ProxySQL Clusterの導入を検討しています。
proxysqlupはProxySQL Clusterを宣言的に管理するためのCLIで、 ProxySQL自体のアップデートやClusterのスケールアウト、設定変更等をCLIの1コマンドで実施できるコンセプトを持って開発されています。 GitHub Actionsから使えるようにして、CLI自体を各自が手動実行しないようすることで運用上のトイルを軽減するように意識しています。
@ressy が調査して溜め込んだProxySQL Cluster自体の知識をもとに、 @drumato がproxysqlupに落とし込んでいく、という分担で実施しました。
合宿の間に、クラスタを宣言的に構築する部分が完成し、 その後も継続して開発をつづけています! 次の画像は、proxysqlupを使ってProxySQL Clusterを構築するデモです。
ProxySQLのミラークエリの検証 / @yuchi
カラーミーショップのデータベース運用として、参照頻度が高いショップページ全体の情報をInnoDBのバッファプールへキャッシュすることで、アクセス時のレスポンスタイムの低減を行っています。
予備DBをバッファプールのキャッシュがない状態から本番システムへサービスインを行う前には、主に使用されるテーブルをSelectするスクリプトを実行し、バッファプールへキャッシュが乗った状態を作ってからサービスインしていました。
障害/メンテナンス時などはもちろんのこと、ECサイトというサービスの特性上急激なトラフィック増加が発生した場合もスケールアウトさせるために予備DBを使用する必要が出てきます。上述したスクリプトの実行完了までは数十分かかっていることで、サービス影響が発生する時間が長くなってしまう問題がありました。
ProxySQLのミラーリング機能を使用し、アプリケーションから実行されるクエリを予備DBにも実行することでバッファプールにキャッシュが乗った状態を作れると考え検証を行いました。
開発環境のDBでミラーリング設定が有効化されてクエリがミラーされるところまでを確認できたので、引き続き本番環境へ導入できるように検証を続け、@drumato @ressy チームが開発しているProxySQL ClusterをKubernetesで構築および運用するツールと合わせることで、データベースの運用を楽にしたいと考えています。
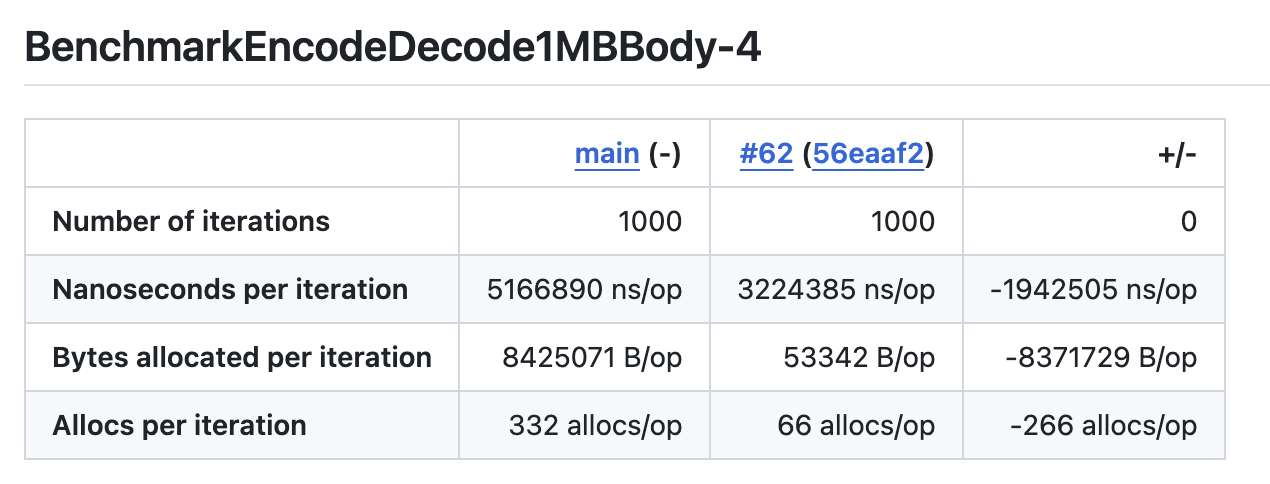
rc (プロキシキャッシュ)のパフォーマンスチューニング / @k1LoW
RFC9111にも対応できるプロキシキャッシュミドルウェアの https://github.com/2manymws/rc のパフォーマンスチューニングに取り組みました。
rcはすでに社内でも運用されているパッケージです。
重い原因はディスクキャッシュ実装である https://pkg.go.dev/github.com/2manymws/rcutil#DiskCache が一旦リクエストやレスポンスをバッファに持ってしまう設計になっていることであるのは明らかでした。
「どのようにStreamで透過的にキャッシュファイルを読み書きするか」が今回の鍵でした。
「その設計から」が合宿スタート時だったのですが、このときふと「net/http.Serverはそんなことは当然やっているはず」と思い立ち、net/httpパッケージのコードを見に行ったところ、「まさに」な https://pkg.go.dev/net/http#Request.Write や https://pkg.go.dev/net/http#Response.Write や https://pkg.go.dev/net/http#ReadRequest や https://pkg.go.dev/net/http#ReadResponse があることに気づき、そこからは実装だけでした。
結果として、ベンチマークレベルで2桁のメモリ使用率改善ができました。
Kunaiの検証 / @n01e0
こんにちは。n01e0です。バイナリかるたをするため、急遽合宿に参加しました。
KunaiはRust製のツールです。eBPFを使ってシステム上で発生するさまざまなイベントのログを取得することができます。
「Linux版のSysmonだと思って良い」とも書かれています。
通常のx86_64のLinux環境であればReleaseのバイナリをダウンロードして実行するだけで動きます。設定についてはドキュメントにかかれています。
ドキュメントを読むと取得できるイベントの種類もわかります。
Kunaiをロードしたうえで、コンテナ内でコマンドを実行してみると以下のようなログが取れます。
{
"data": {
"ancestors": "/usr/lib/systemd/systemd|/usr/bin/containerd|/usr/bin/containerd-shim-runc-v2|/usr/bin/containerd-shim-runc-v2|/usr/bin/bash",
"parent_exe": "/usr/bin/bash",
"command_line": "ls --color=auto",
"exe": {
"file": "/usr/bin/ls",
"md5": "30caea6cf2c12bbb1b626b04ab77d7cb",
"sha1": "14074fe0a2c4c45a16472dfa23dc4e05ff8177ff",
"sha256": "1bea8094b78a3910345d80af3d182390fda07ae5788352651eb7773505dc39af",
"sha512": "031ed0f2c44b4ab60f9058ec7ab76f989cc59e95588897d6c31ccd1ea04a9bb8e992354838f312c18c927ee2bf2206ff8a659a7efc398c5f87c2454ccf8c6ead",
"size": 142312
}
},
"info": {
"host": {
"uuid": "598fadc5-7b8f-56fa-833a-bd88ca5c1011",
"name": "kunai-develop-n01e0",
"container": {
"name": "2fc7c5b38510",
"type": "docker"
}
},
"event": {
"source": "kunai",
"id": 1,
"name": "execve",
"uuid": "b1587708-9a21-ff39-caf5-9fffe92656d1",
"batch": 22
},
"task": {
"name": "ls",
"pid": 241988,
"tgid": 241988,
"guuid": "cec413bb-54d5-0100-6c2a-09ae44b10300",
"uid": 0,
"gid": 0,
"namespaces": {
"mnt": 4026532244
},
"flags": "0x400000"
},
"parent_task": {
"name": "bash",
"pid": 241965,
"tgid": 241965,
"guuid": "4720643e-54d5-0100-6c2a-09ae2db10300",
"uid": 0,
"gid": 0,
"namespaces": {
"mnt": 4026532244
},
"flags": "0x400100"
},
"utc_time": "2024-07-18T03:18:46.337373371Z"
}
}
良くないですか?
ちゃんと親プロセスもわかるし、コンテナの名前もnamespaceも取れてるんです。
「eBPFでイベントログを取って色々したい」という願望があっても、イベントの定義と実装がどうしても膨大な作業になりがちで面倒なんですが、Kunaiが全部いい感じにしてくれているので助かります。
あとはこれで取得したデータの活用に集中するだけです。
カラーミーショップのPOP/IMAPサーバーをCourier-IMAP+qmail-pop3dからDovecotにする / @tnmt
カラーミーショップではCourier-IMAPとqmail-pop3dでメールホスティングを行っていますが、運用上のさまざまな問題の解決と、社内の利用技術の統一を目指してDovecotへの移行を検討しています。
現行のメールサーバーの構成からのリプレース方法を探るべく、今回の合宿中で既存のIaCのコードを変更を行いました。実現できたのは以下の内容です。
- Dovecotのセットアップ
- 既存の認証方法を使ったIMAP/POP認証
以上をもって検証環境にてCourier-IMAP&qmail-pop3dとDovecotのプロセスを切り替えることで、IMAP/POPのポートの待受のミドルウェアを変更できる状態を作れました。
ここまではさほど難易度の高くない内容ではあるのですが、単純にミドルウェアを切り替えるだけではNGでミドルウェア変更の差分の解消が必要になります。注意を払わないといけないのは、ホストしているメールの連番とファイル名のリストの扱いです。これらはファイルやミドルウェアからの応答として管理されますが、特にPOPでは受信・未受信管理にも利用されるため、ミドルウェア切り替えの際にこの互換性が取れていないと、POPにてメールの再受信がされる可能性があります。
ミドルウェアを切り替えてもIMAP/POP利用クライアント側での設定変更が必要とならないよう、調査・検証する時間が残りの合宿期間中で多く占めました。そこでさらに以下が実施できました。
- Courier-IMAP/qmail-pop3dと互換性を持つためのDovecotの設定項目の把握と指定方法
- ユーザーのMaildirにあるミドルウェア固有のファイルのマイグレーション方法の調査と検証
すでに弊社内でも技術部ホスティングインフラグループの面々がCourier-IMAPからDovecotへのマイグレーションを実施していたため、社内の情報を参考にすることで大幅に時間が短縮できました。
今後は移行の計画を十分に練ったのち、プロダクションの構成の変更に臨みたいと考えています。
アクセスログベースでAnalysisRunを実行しCanary releaseできるようにする / @naryo @ryu-ch
現在、minneではArgo Rolloutsを用いてCanary Releaseを実施しています。
これまでは、Prometheusに収集されたIstioのメトリクスを使ってCanaryの状態を計測していましたが、いくつかの課題がありました。
Istioのメトリクス(istio_requests_totalを使用)では、どのエンドポイントで Bad Request(500エラー等)が増えているかを判断できず、開発者がArgoRolloutsによってロールバックされた原因を掴むまでに時間がかかってしまうといった問題がありました。また、Shardingを行っているPrometheusサーバーが一台でも落ちると、正常にリクエストレートの集計ができなくなり、リリースに影響が出てしまう問題もありました。
これらの課題に対して、私たちはCanaryの状態の計測にアクセスログを集計したデータを用いることを検討しました。具体的には、BigQueryやGrafana Lokiを使用してアクセスログを集計し、Canaryの状態を評価するアプローチを考えました。しかし、BigQueryは一回あたりの集計コストが高いため今回は見送り、Grafana Lokiを用いたアクセスログの集計を行うことにしました。
今回の合宿では、Grafana Lokiでアクセスログを集計するにあたって、既存のアクセスログの収集方法を見直す必要がありました。そのため、Fluentdの検証や、Grafana LokiのLogQLでの集計方法の調査・検証をメインで行いました。
合宿中に現状のArgo Rolloutsの基盤にこれらの機能を取り入れることはできませんでしたが、引き続き検証を進めて、さらなるデプロイフローの改善に取り組んでいきたいと考えています。
OpenDKIMでのなりすまし防止の実装 / @gurasan(Ryuichi Watanabe)
仙台在住の初静岡だった渡部(gurasan)です。東北の民なので富士山が見たくて見たくて仕方なかったのですが当日は山頂部が雲で隠れていて見れなくて残念でした。また絶対行こうと思います。
私は今回の合宿でOpenDKIMが持っているなりすましに関する調査と対策の実装を行いました。この課題は細かく書くと以下のようなものです。
課題
- SigningTableの設定が、認証されたユーザーが他人の署名設定を適用することを可能にしている
- 悪意のあるユーザーが、OpenDKIMシステム上で他人の秘密署名鍵を使ってメッセージに署名することができてしまう
- Xというユーザーがメールサーバの認証を突破した上でYというユーザーのメールアドレスをFromヘッダーに設定してメールを送信すると、Yというユーザーとして正しく認証してしまう
この課題は以下のissueにも記載されており現在もOpenDKIM自体では現在も対応がされていません。
issue: Signing table allows cross-user signing
この相乗りしてるドメイン間のなりすましを防ぐ仕組みはOpenDKIM本体では機能としては備わっていないがLuaで拡張を行う機能は備わっていますopendkim-lua。そちらを利用することでなりすましを防ぎ署名をしないという仕組みは実装することができます。以下は実装のサンプルとなっています。Luaで認証されたユーザー名やFromヘッダーの値を取得できることがわかります。これらの値を元に署名をするかどうかを判定するということができるようになっています。
local logging_enabled = 1
local function logger(logwhat)
if logging_enabled == 1 then
odkim.log(ctx, "LUA-SETUP "..logwhat)
end
end
local function signer(domain)
if odkim.sign(ctx, domain) == 1 then
logger("Signing requested")
else
logger("Signing failed")
end
end
local author = odkim.get_mtasymbol(ctx, "{auth_authen}")
if author == nil then
odkim.verify(ctx)
return nil
end
local mailfromdomain = odkim.get_fromdomain(ctx)
local mailfrom = odkim.get_mtasymbol(ctx, "{mail_addr}")
local headerfromaddr = odkim.get_header(ctx, "From", 0)
if mailfromdomain == mailfrom then
signer(mailfromdomain)
return nil
end
odkim.set_result(ctx, SMFIS_ACCEPT)
return nil
またGitHubのリポジトリにも他のサンプルがあるのですがMySQLに問い合わせた結果をもとに署名を行うこともできるようです。OpenDKIMのバックエンドとしてMySQLなどのバックエンドを使っている場合でも対応が可能となっていました。
authheaders-check-setup-hook.lua
その他
(宣伝)合宿の様子や感想などは別途個人のブログの方にも書いてあるのでぜひ読んでいただければなと思います
Amazon RDSの監査ログをCloudWatch Logsを介さずにS3へ保存したい / @harukin
はじめて「こだま」に乗りました、harukinです。
カラーミーショップのAmazon RDSの監査ログはCloudWatch Logsにエクスポートされ、Data Firehose(旧Kinesis Firehose)を経由してS3に保存されています。最終的に監査ログがS3に保存されていれば良いため、CloudWatch Logsを介する必要はありません。CloudWatchのコスト増加が課題となっていたため、監査ログを直接S3に保存する仕組みを検討し、今回の合宿をきっかけに実装に着手しました。
ざっくりと以下のような流れを想定しています。
- Amazon RDSの監査ログをS3へ保存するLambda関数を作成
- Amazon EventBridgeが定期的にLambda関数をトリガー
- Lambda関数が監査ログのローテーションを確認し、S3に保存する
監査ログをS3へ保存する部分まで実装が完了していますが、Lambdaが監査ログをS3に保存できなかった場合の通知やリトライ機能など、実際の運用に向けて追加の対応が必要です。これらの課題に対応しつつ、引き続き実装を進めていきます。
EKSにおけるpreview環境の実装 / @shibatch(Kohei Shibata)
こんにちは。shibatchといいます。先月、なぜSUZURIはHerokuから「EKS」へ移設する決定をしたのかと題して、SUZURIをHerokuからEKSへの移設を決定した経緯についてお話ししました。
実はこの記事が出るのとほぼ同じくらいの時期に、EKSへの移設が完了したんですよね🎉 そこでKubernetesに移設したことを活かし、GitHubへPull Requestを作成すると自動で専用の環境をKubernetesクラスタ上に作ってくれる仕組みの作成に、この合宿で着手してみました。
実績は以下の通りで、branchの更新をサイドカーコンテナが検知してsyncするところまではこぎつけました。
- preview用にnamespace切って環境をととのえ、Webのpod立ち上げ
- サイドカーコンテナでgit-syncを使い、
- GitHub Appを定義して周期的にトークンをEKSで更新し、
- git-syncサイドカーコンテナでPod内でリポジトリのsyncができた
「こうすればできるだろう」というイメージは事前に固めて着手したものの、トークンの更新作業は当初あまり想定していませんでした。ただそれでも他合宿メンバーから助言いただいたおかげで実装できてよかったです。一人だとこうもいかなかったので合宿という環境に感謝ですね。
今後はさらに実装を進めて、ちゃんとPull Requestが立ったらGitHub Actionsで起動するようにしていく予定です。
AIにログを食わせて確率的な判断をしてもらうくん / @pochy
沼津の伊豆・三津シーパラダイスにはゴマフアザラシがいます。pochyです。この合宿には「AIをやるぞ」と決めて臨みました。
ペパボの連結企業であるGMOクリエイターズネットワークにおいて、定型タスクとして特定種類のログの解析を人間が目視で行っているという課題がありました。例えばWAF(Web Application Firewall)のブロックログを眺めて、偽陽性ブロックが出ていないかどうかなどを判断する作業です。
このような、テキストで与えられた情報をもとに確率的な判断をするという作業は昨今のAIが得意とするところです。そのため、トイル削減を目的として、人間ではなくAIが判断することを目指しました。
- Datadogにクエリして目的のログ(過去n日間の間にWAFがブロックしたアクセスログ)を取得する
- そのログをOpen AIのAPIにプロンプトとともに送信する
- 返ってきた結果をパースする
- パースした結果から、対応の要否を0, 1で出力する
合宿内で、以上の流れを実行するスクリプトが実装できました。人間が普段おこなっている常識的な判断は、現代のAIサービスでも十分に代替できそうだと分かりました。 精度の評価と、データソースやプロンプトの拡張性などが今後の課題として残っています。
ボットのアクセスを判定するAPIの開発 / @pyama
この世で一番キライな食べ物は夏です。こんにちは、P山 です。今回の合宿では、WEBサービスにアクセスしてくるクライアントの中からボットのアクセスを判定するための高度な分類器をPythonとXGBoostを用いて実装しました。その結果、非常に高い精度を達成することができました。
precision recall f1-score support
0 0.98 0.96 0.97 213900
1 0.90 0.95 0.93 86100
accuracy 0.96 300000
macro avg 0.94 0.96 0.95 300000
weighted avg 0.96 0.96 0.96 300000
この分類器は、実際の運用環境でも高い信頼性をもってボットと人間のアクセスを区別する能力を発揮しています。特に、ボットの検出率が95%と高いため、悪意のあるアクセスや転売目的のクローリングを効果的に防ぐことができます。
最近では、攻撃目的のアクセスに加え、転売目的で大量にクローリングするボットも増加しています。これらのボットはWEBサービスのリソースを無駄に消費し、我々のサービスを利用するお客様の満足度を低下させる要因となります。こうした問題を解決するために、ボット判定の精度向上に努めました。
今回の実装では、WEBサーバのログに出力される一般的な特徴量を利用し、ユーザーエージェントやWEBアクセスログの周期性、ステータスコードの割合に基づいて特徴量を設定しました。この分類器は自社開発のWEBプロキシサーバから呼び出し、リアルタイムでボットを判定し、必要に応じてアクセスを制限することができます。
今後の展望として、本番環境での適用後に詳細な結果を公開し、さらなる改善を続けていきたいと考えています。これからもお楽しみにお待ちください。
Kubernetes Custom Controller の挙動を人間が再現できる CLI ツールの実装 / @takutaka
takutaka と申します。ペパボでは、ArgoCD をベースにいくつか機能を拡張したデプロイツールとしてShopSetというものを開発しています
拡張の手法として、Kubernetes の Custom Controller を実装しているのですが、利用が進んだため Reconciliation の待ちが発生し、本番のデプロイがなかなか始まらないという課題が発生していました。
そのため、 Custom Controller 内で利用している処理を切り出し、CLI ツールとして実行できるようにパッケージングしました。
以下のようなコマンドを実行することで、コントローラが行う処理と全く同じことを即時実行できます。
% shopctl manager --resource-name my-shopset --resource-namespace default --resource-kind shopset --once
このコマンドの実装により、ユーザーが任意のタイミングで処理を実行できるという当初の目的を達成したと同時に、コントローラが使う処理の e2e テストが指定のリソースのみを対象に行えるようになるなど、想定していなかった副次的な効果がありました。
社内のユーザーに対しツールを公開することと、今後はこのコマンドをコントローラのワークフローと統合し、CLI コマンドを実行するジョブを並列に動かすことによる処理のスケールアウトを実装しようと考えています。
まとめ
 通常業務では同じチームといえどなかなか会話しないパートナーとコミュニケーションを図ったり、相談し合いながら夜通し開発できる機会というのは弊社を含めてなかなか難しいように思います。
そこに対して開発合宿は私たちが大切にしている3つのことのみんなと仲良くすること、ファンを増やすこと、アウトプットすることの全てを合宿・ブログ・開発で満たせることができて大成功でした。
通常業務では同じチームといえどなかなか会話しないパートナーとコミュニケーションを図ったり、相談し合いながら夜通し開発できる機会というのは弊社を含めてなかなか難しいように思います。
そこに対して開発合宿は私たちが大切にしている3つのことのみんなと仲良くすること、ファンを増やすこと、アウトプットすることの全てを合宿・ブログ・開発で満たせることができて大成功でした。
私個人としてもさまざまな技術背景を持つパートナーたちが互いに尊重し合いながら開発でき、本当に良い仲間に恵まれたと感じております。 この場をお借りして感謝したいと思います。本当にありがとうございました!!!
最後に、開発合宿はいいぞ!!!



