こんにちは。 takutaka と申します。最近は暑くて大変ですね。熱中症には気をつけて過ごしましょう。
最近、SUZURI で負荷試験をやったので、そのことについて書いていきます。
概要
Tシャツセールを開催し、その期間に合わせてテレビCMを放映することが決まりました。
アプリケーションやビジネスなど、各領域で達成すべき課題が発生する中、インフラ領域では「最大限の努力をしてセール期間中のダウンを防ぐ」というミッションが与えられました。
パフォーマンスチューニングをやろう、インフラリソースを増強しよう、様々な対応がなされる中、そのひとつとして、負荷試験を実施して各対策の効果を検証することになりました。
僕が主担当として取り組むことになったのですが、問題が一つありました。それは、僕がまともに負荷試験に取り組んだ経験がまったくなかったということでした。
今まで負荷試験をやったことがないエンジニアが、どのように課題に取り組んでいったか、時系列に沿ってお話したいと思います。
負荷試験を実施する前に考えたこと
負荷試験を始めよう!となった当初、知識は全くのゼロでした。
ab 使ってバシッとやったらいいのか…?くらいの感覚だったので、ひとまず情報収集を行いました。
まずはググる
とりあえず Google にて「web 負荷試験」で検索しました。
使用技術や、計画作成など、様々な知見が集まっており、インターネットの集合知は素晴らしいなと感じました。
ここで、以下の知見をインストールできました。
- なぜ負荷試験を実施するのかを明確にすべき
- 負荷試験を実施するクライアントの負荷を考慮すべき
- 完全なシナリオの作成には時間がかかる
- ツールは k6 を使うのが良さそう
負荷試験完全に理解した状態になったところで、実際に SUZURI で実施する負荷試験について設計していきました。
目的の設定
まず今回の目的としては、「セール期間中のダウンを防ぐ」という大項目があります。すべての対応はこの目的を達成するために必要なもので構成されるべきです。
この目的は、「セール期間中のリクエスト数を精度高く予測し」、「予測されたリクエストを処理できることを保証する」、「一連の対策をセール開始までに実施する」という課題に分解できます。
それぞれの課題をどのように達成するか、考えていくことにしました。
一連の対策をセール開始までに実施する
いくら負荷試験を実施したところでアプリケーションのパフォーマンスは向上しません。
負荷試験の結果を確認し、アプリケーションのチューニングを行い、チューニングの結果を再度負荷試験で確認するというサイクルを回して、初めてアプリケーションのパフォーマンスは向上します。
つまり、負荷試験の実施が後続のチューニングのブロッカーとなるため、とにかく早く何かしらの結果を出す必要があります。
セール開始1週間前に、最高の負荷試験の結果が出ました!となっても、負荷対策としてやれることは限られてしまいます。
セール期間中のリクエスト数を精度高く予測する
dUU や CVR を始めとする、事業成長を確認するための指標としての KPI は、インフラ領域ではサービスのリクエスト数に変換されます。
そのため、リクエスト数の予測は事業の需要予測とだいたい一致します。
セール期間中のリクエスト数を予測することは、負荷を予測するための第一歩となります。
予測されたリクエストを処理できることを保証する
上記で予測できたリクエストを、現システムで処理できるかどうか確かめます。
処理できない場合、正常に処理できるようにパフォーマンスチューニングやリソース増強などの施策を投入します。
これらを繰り返し、最終的に予測されたリクエストを処理できるようになることを確認します。
また、リクエストを処理できることを保証するためには、想定外のリクエストが発生した際 (予測が大幅に下振れた際) にどうするのか、予め定めておく必要があります。
DoS 攻撃を食らって全然駄目でした、では「ダウンを防ぐ」ことができているとは言えませんね。
対応を始める
だいたいやるべきことはわかってきました。どうやるのかはあんまりわかっていませんが、時間は待ってくれません。
できることからやっていきます。
負荷試験環境構築
まず、これから何回も実施するであろう、負荷試験を実施するための足回りを最初に整えました。
あらかじめ試験の実行コストをゼロにすれば、色々な検証をシュッと実施できるためです。これは後々の工数削減に寄与しました。
負荷試験ツールは k6 を選びました。理由は以下によるものです。
- マルチコアで効果的に負荷をかけやすい
- ヘッダ改変やトークン取得など、比較的複雑なシナリオが書きやすい
- 実行環境に必要な依存が少ないので、ローカルのシナリオ作成環境と実際の試験を実施するクライアントの環境差分がシナリオ作成に影響しづらい
実際に負荷をかける環境として、GitHub Actions + オンプレ Self Hosted Runner を選択しました。理由は以下によるものです。
- データセンタのエンタープライズグレードな安定したインターネット回線を利用できる
- 実行手順をコード化することで、手順ミスによる手戻りを防ぐことができる
- Actions のログとして実行結果を出力することで、実行結果を他者と共有しやすい
- ジョブの並列実行に対応しているので、実行環境をスケールさせることができる
実行結果の共有がしやすいことが、チームで負荷に取り組む上で非常に有効に働きました。
また、Actions を使うことにより、タスク実行や結果の管理を行う UI が予め整っていたことで、ダッシュボードの整備や結果の収集など、本質ではないことをやる必要がなかったことも大きかったです。
とりあえず k6 をいじってみる
k6 何もわからない状態なので、とりあえず負荷の高そうなエンドポイントに対して負荷を掛けてみることをやってみました。
SUZURI では、インフラの監視やパフォーマンス測定全般を DataDog で行っており、負荷の傾向に関しては DataDog APM を利用してすでに把握できていました。
DataDog APM はめちゃくちゃ便利で、DataDog の中で一番好きなプロダクトになりました。
単一エンドポイントに対して負荷試験を実施することで、APM の出力を得ることができ、第一弾パフォーマンスチューニングを行うことができました。
ここまでで、やると決めてから3営業日が経過しています。「セール開始までにできるだけ早くチューニング箇所を洗い出さなければならない」という課題に対して、いい感じにアプローチできています。
どうやってシナリオを組むか決める
負荷試験環境はできたので、実際に負荷としてかけるリクエスト量の見積もりをします。
シナリオを決定する際に、取りうる選択がまずふたつ思いつきました。
- 本番のユーザーの行動を観察し、人間のように振る舞うユーザーシナリオを作成して、登場する割合に応じて倍率を乗じてリクエストする
- 全体のリクエストからエンドポイントごとのリクエスト割合を算出し、倍率を乗じてリクエストする
1 は、ユーザーの状態を保持して負荷を与えられるため理想的ではあるのですが、シナリオの作成と実装が大変であることと、SUZURI という EC サービスの特性上、ユーザーの状態が負荷を上げる要因にはなりづらいため、今回は 2 の作戦を取ることとしました。
とりあえずそれっぽいシナリオを組んでみる
最初、どうやろうか考えあぐねているときに、上司の @hsbt が「去年のセールって今のコードで耐えられるんでしたっけ?」といったことを言っており、
たしかに〜と思ったので、まず去年のセール情報をもとにシナリオを組むことにしました。
以下のアプローチで、シナリオを作成しました。
- DataDog より去年のセール(2021年05月)の負荷状況を確認する
- リクエストの多いトップ10のエンドポイントに対して、ピーク時の rps(request per sec, 秒間リクエスト数) とエンドポイントのマッピングを作成する
- マッピングをもとに、k6 で rps を再現するシナリオを作成する
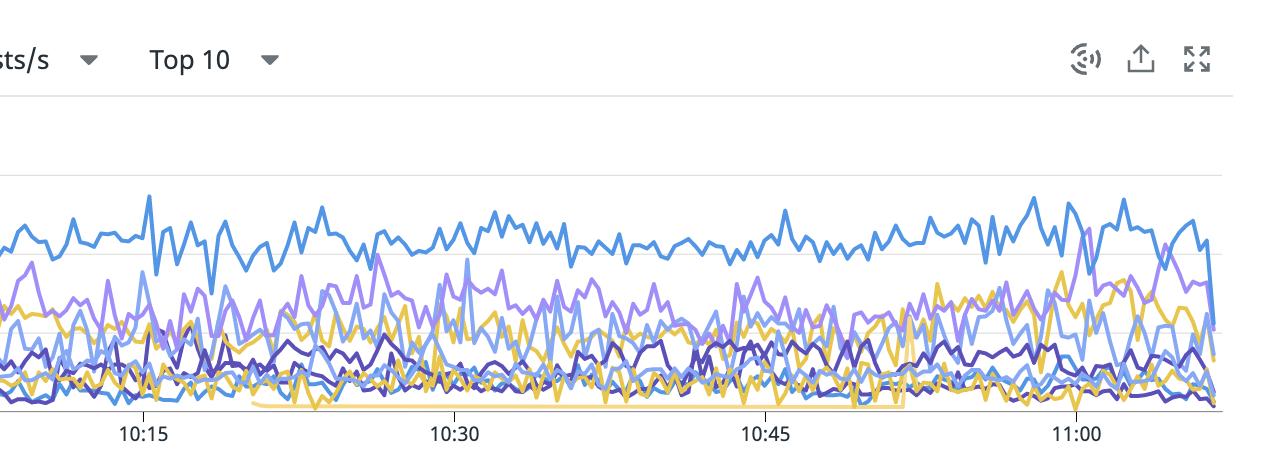
上記の図は、DataDog APM でトップ10のエンドポイントのリクエスト数を表示している様子です。
最初は、VUs (並列数を表す k6 用語) を指定して、どのくらいまで問題なく処理できそうか?という調整を、あたたかみを利用して行っていました。
ある程度いい感じに負荷が掛けられそうとわかった段階で、k6 には、Constant arrival rate という、指定した request rate を再現する機能があることを知り、それを利用しました。非常に便利なので皆さん使うと良いと思います。
こうして、2021年セールの負荷を再現することができるようになりました。
だいたいここまでで、やると決めてから5営業日くらいが経過しています。
「ダウンする」 を定量的に評価できる指標に変換する
また、負荷試験結果を評価する上で、「ダウンする」という定性指標を、定量指標にする必要がありました。
そのため、「95パーセンタイルレイテンシが1.0sを超える」ことを、「ダウンする」と定義しました。
実際には、少し遅くても完全にサイトが落ちていなければ大丈夫と判断することもあるので、 レイテンシは厳密に 1.0s を切らなければいけないということにはしませんでした。
想定リクエスト量を見積もる
まず、今回のセールがどのくらいの規模を想定しているのかを知る必要があります。
そのために、事業としての SUZURI セールの計画資料と、前回のセールの実績が残っている Google Analytics を参考にしました。
GA の中では、購入が発生した単位として「トランザクション」、ユーザー全体の行動単位として「セッション」が使われています。
1セッションあたりに必要になるリクエスト数はおおよそ一定であるため、今回のセールで発生するセッション数が、前回のセールのそれの何倍であるかを推定できれば良さそうです。
計画資料から、見込み売上を取り出します。これを N とします。
次に、Google Analytics の数値を見ました。見た数値は、トランザクションあたりの購入単価, CVR です。それぞれ単価を P, CVR を C とします。
ユーザーの行動傾向は一年前と大きく変わっている可能性があるので、単価、CVR は最新の値を参照します。
そして、以下の計算式で推定トランザクション数(T)をベースに, 推定セッション数(S) を算出します。
T = N / P
T = S * (C/100) であるので
S * (C/100)= N/P
S = (N/P) * (100/C)
= 100N/(P*C)
仮にトランザクションあたりの購入単価を100円、CVRを1%とします。売上見込みが1万円とすると、推定セッション数は、以下のようになります。
S = 100 * 10,000 / (100 * 0.01)
= 10,000 / 0.01
= 1,000,000
よって、1万円の売上を出すためには100万セッションが必要になる計算になります。
さて、前回のセールでは、50万セッションが発生したことにします。
今回のセールは、前回のセールの2倍のセッションを生む必要がある = おおよそ2倍のリクエストが発生すると推定できます。
この計算を、会員登録済みユーザー、ゲストユーザーの次元でそれぞれ行い、それぞれの属性においてリクエスト倍率を推定しました。
また、今回は CM の放映が同時に行われるため、社内に蓄積された独自の情報による係数を掛けて、最終的なリクエスト倍率を算出し、エンドポイントごとの目標 rps という形で負荷試験のパラメータとして設定しました。
だいたいここまでで、やると決めてから10~12営業日が経過していました。
見積もった段階で発生した課題
Google Analytics を見ると、設定した負荷試験にいくつか問題点があることがわかりました。これらは以下の方法で対応しました。
- ログインユーザーとゲストユーザーで CVR や購入単価が異なるため一緒にできない
- ログインセッションを抽出して Cookie に仕込むことでログインユーザーのリクエストを行えるようにして、推定した割合に応じてリクエストを分割した
- 2021年5月時点で使用されていないエンドポイント(ex: GraphQL)があった
- 現時点での全体のリクエスト数と、前回のセールのリクエスト数を比較して、前回のセールで実装されていた場合のリクエスト数を出し、それに推定リクエスト倍率を掛け目標の rps を設定した
GraphQL の負荷試験をするために、クエリを作る必要がありましたが、全部 @shimoju が対応してくれました。
バリバリとパフォーマンスチューニング
ここまで来たら後はチューニング、負荷試験、結果からチューニング結果の評価、ボトルネックを見つけて更にチューニングの繰り返しです。
パフォーマンスチューニングは、@pyama が中心となり、SUZURI のプロダクト開発エンジニアのみなさんが取り組んでくれました。僕は何もやってないです。アプリケーション開発に強くなるぞ。。。という気持ちを新たにしました。
どのようなことをやっていたのかは、SUZURIのテレビCMとTシャツセールを乗り切るためにやったことで @pyama が記事を書いているのでそちらを参照ください。
パフォーマンスチューニングの他にも、負荷試験環境の DB スペックやコンピュートリソースの数などが本番と異なるため、数値が伸びないことが発生しました。
Heroku のジャンボプロファイル申請を行いスケールの最大数の上限突破をしたり、DB のスケールアップ→負荷試験実施→スケールダウンを自動化する GitHub Actions を作成したりして、可能な限り負荷試験環境のリソースを本番環境に近づける工夫をしました。
今回の試験の目的を達成するためには、本番環境に近づける必要がありましたが、例えばシステムが捌ける最大リクエスト数を知りたいと言った目的であれば、固定リソースに負荷試験を実施し、それを N 倍して算出するといった方法を取ることができます。ケースバイケースで使い分けると良いでしょう。
本番環境への負荷試験実施
上記負荷試験は、ステージング環境で実施していました。
しかし、本番環境とのデータ量の差分や、検証できていない未知のエンドポイントがトリガとなって想定外の負荷が発生するのでは、という懸念が生じてきました。
SUZURI のエンジニアリングをまとめている @kurotaky に相談し、本番環境での負荷試験を提案してもらったので、よさそう〜と思って実施しました。
極力ユーザーに影響の出ない早朝において、SUZURI のプロダクト開発を行っているエンジニア同席のもと、負荷試験を実施しました。
これにより、いくつかの課題を発見でき、事前に対処を行うことができました。
目標数値達成と仕上げ
そして、セール開始10日前の 6/2 に、目標としていたリクエスト倍率を達成しました。上記画像は、本番環境で初めて目標を大体クリアできた記念すべき瞬間です。
仕上げとして、想定外のリクエストが発生した際のスロットルを @pyama が実装してくれました。
これで、おそらくは負荷に耐えられるだろう、という状態まで持っていけました。
セールはどうだったか
負荷対策を実施したおかげで、負荷が原因となるような障害は発生しませんでした。
駆け込み需要で負荷が高まりがちな最終日も、比較的安心して迎えることができました。
今回発生したトレードオフ
今回、主に時間による制約により、様々なトレードオフが発生したと考えています。この記事で言及すべきトレードオフは、負荷試験の方法と、リクエスト量の推定方法、そして、負荷試験結果の妥当性の評価でした。
負荷試験方法
負荷試験は、一般的に、ボトルネックを発見するために実施します。
今回もその目的は一致していましたが、今回のような「ブラックボックス的にシステムに負荷を与える」といった試験方法だと、試験結果としてシステム全体の処理能力が出力されるため、ボトルネックを発見することが困難になります。
試験結果の出力は、試験ごとの相対評価をするための指標にとどめ、システムの負荷は DataDog APM を参照することで、ボトルネックの抽出を行いました。
リクエスト量の推定方法
今回、売上の見込みという、狭義の意味では外部となる場所で算出された指標をベースに利用しました。
本来、生データから理論を組み立て最終的な推定を行うことがベストです。
自身が行った推定に対して、根拠として外部の推定値を用いたのであれば、その推定値に関してどのくらいの誤差を許容したのか、という点に関してはきちんと把握をしておく必要があります。
負荷試験結果の妥当性
僕の持ち合わせる知見では、試験結果について定量的に評価することができませんでした。
また、キャッシュヒット率やデータ量、アクセスされるエンドポイントの分散など、本番のリクエストと比較して考慮できていない点が多くありました。
そのため、今回の負荷試験のやり方では、本番でうまくいくかどうかは本番になってみないとわからない。。。という状態までしか原理的に持っていくことはできませんでした。
定量的に妥当性を評価できるような負荷試験を実施するためにはどのようにすればいいんでしょうね。知見をお持ちの方はぜひ教えていただきたく思います。。。
まとめ
負荷試験をやったことのない人間が、短時間で比較的いい感じの負荷試験を実施するためにやったことを述べました。
GMO ペパボには、負荷に対する知見がたくさん溜まっており、また、その知見を持ってしても解決できない課題が沢山存在します。
プロフェッショナルのもとで働いてみたい!または、俺が課題解決をやってやるぜ!!!と思った方は、積極採用中ですので、応募をお待ちしております。
僕に負荷試験の知見を教えてください!よろしくお願いします。



