
こんにちは。デザイン戦略チームのデータサイエンティスト @zaimy です。
「デザインのチームにデータサイエンティスト?」と思われるかもしれませんが、デザイン戦略チームは「ペパボのデザイン思考を確立し、パートナー(社員)のマインドセットのひとつとして定着させ、日々の仕事で実践できるようにすること」をミッションに掲げており、具体的な活動内容の一つに各サービスに関わる数値の可視化や分析を通してその効果的な活用を支援することがあります。
このような活動を進めるために、2018年からエンジニアの @gyugyu と私がデザイン戦略チームにジョインしました。この記事では、2018年を振り返ってデータサイエンティストの主な活動内容をお伝えします。
KPI 管理基盤「Pepalytics」の開発
「Pepalytics」は、KPI の分析を補助するためにペパボで開発したツールです。サービスにおいてどのような施策を実施するべきかは、様々なデータソースと様々な切り口から人間が思考判断する必要がありますが、従来の KPI 管理には次のような課題がありました。
- KPI 同士の関係性の把握が難しい
- KPI の定義や管理方法が担当者によって異なる場合がある
- SQL によるデータ抽出や集計に工数が掛かる
そこで、指標となる KGI と KPI を定義した上で自動的に収集し、GUI で指標をディメンションごとに集計したり、KPI ごとの KGI に対する影響や見通しを自動的に計算したりできるツールとして「Pepalytics」を @gyugyu と開発しました。主な機能は次のようなものです。
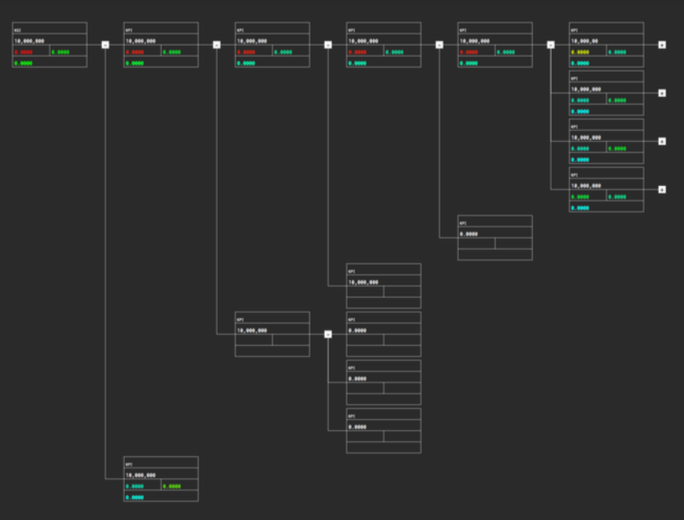
機能1: KPI ツリーの表示
KPI ツリーでは、KPI 同士の関係性と値は勿論、その変動のしやすさや、KGI に対する影響度が表示されます。これによって、これまで人が行っていた値の調査やレポートの作成を自動的に行うことができるようになったほか、KGI に対する影響が大きい KPI を示すことで、サービスの担当者が効果の高い施策に注力できるようになりました。
例として、ハンドメイドマーケット「minne」の KPI ツリーは、KGI から KGI を生み出す各セッションの流入元までを遡ることができ、すべて展開すると約400ノードに上る詳細なデータを確認することが可能です。
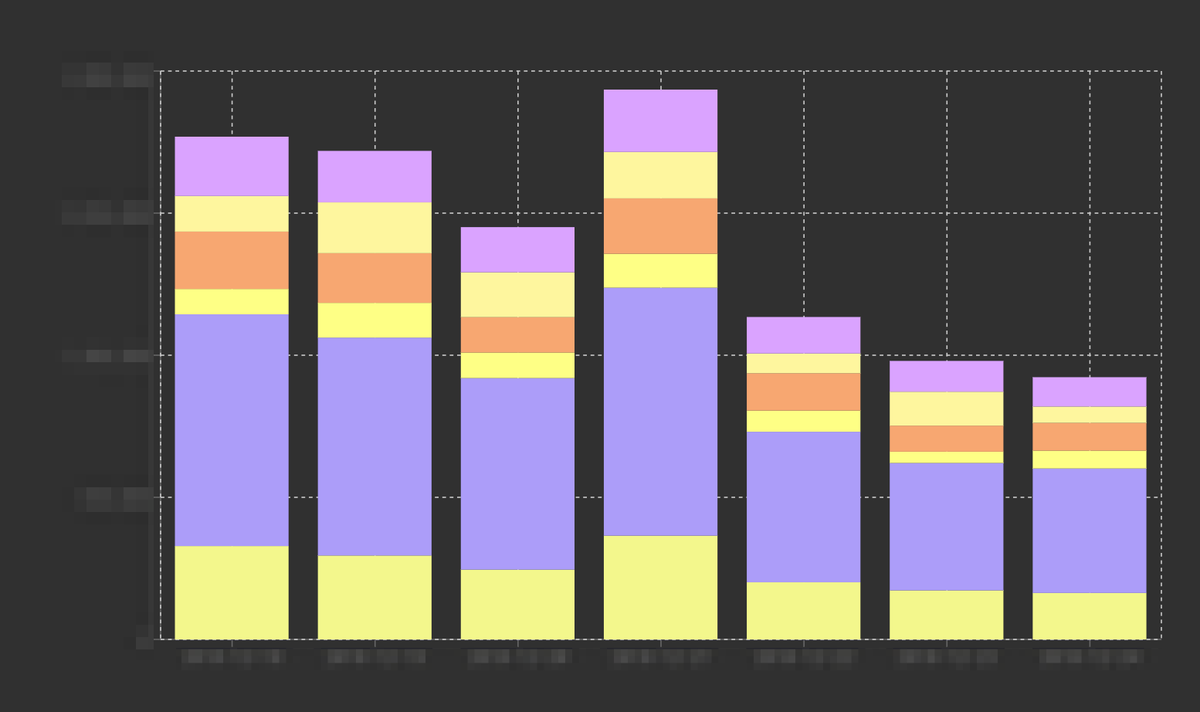
機能2: ディメンションや単位時間を指定して指標を集計
ディメンションとサブディメンション、またはディメンションと単位時間を指定して指標を集計し、グラフやクロス表にできます。サービスのデータベースや、ペパボの行動ログ基盤「Bigfoot」のデータを統合することで、ユーザーの属性情報など、サードパーティのアクセス解析ツールでは利用できないディメンションを活用できるようになりました。
また、広告予算の配分や SNS 運用の参考にできるようにアシストコンバージョンの概念を導入しており、コンバージョンまでに複数の流入元を経由した場合にそれぞれの貢献度を指定できるようになっています。
Pepalytics は既にハンドメイドマーケット「minne」で活用されており、現在はレンタルサーバー「ロリポップ!」にも導入を進めています。
行動ログ基盤におけるデータフローの改善
ペパボではマネージドの Hadoop サービスである Treasure Data をバックエンドとして、行動ログ基盤「Bigfoot」を構築し、2015年から運用しています。行動ログ分析に必要となるクエリは Treasure Data の Scheduled Query (cron) として登録・実行しており、弊社の @monochromegane が開発した OSS 「pendulum」 でコード管理を行っていました。
運用開始時は単一のクエリで完了する分析がほとんどであり、リソース的にもかなり余裕があったため、Scheduled Query でも特に問題はありませんでしたが、クエリの数が数十を超え、複雑な依存関係のあるクエリ群が出てくるようになると、各クエリの実行時間を見越してスケジュールを立てる必要が出てきました。
しかし、アドホックなクエリの実行によって一時的にリソースが圧迫されることで実行時間が延びたり、前段のクエリが何らかの理由で失敗したりしても後段のクエリはお構いなしに実行されるため、実行結果が壊れたり、クエリのジョブキューが詰まったりすることが散発的に発生していました。また、それらトラブルが発生した際に、どのような順番でデータ操作やクエリの再実行を行えばリカバリできるのかの知見が、クエリの実装者や pendulum で管理しているリポジトリを熟知している一部のパートナーに属人化している問題がありました。
そこで、2018年に入って @monochromegane @gyugyu と、ワークフローエンジンの Digdag (Treasure Workflow) にすべてのクエリを移植しました。クエリの前後関係やワークフロー同士の依存関係を定義することで、実装者はリソースが空いている時間を考えたり、クエリの実行順序が壊れる心配をする必要が無くなったほか、データフローがコードで表現されているため、属人性を排することができました。
ワークフローは Scheduled Query を利用していた頃と同様に GitHub Enterprise でコード管理を行っていますが、従来は無かった CI でのワークフローの実行やテストも導入しています。これらは別記事でもご紹介する予定です。
今後は、データフローの前段にあたるサービスのデータベースから Bigfoot へのレコードのインポートや、後段にあたるサービスアプリケーションからのクエリ結果の取得についてもワークフローの制御下におけるよう開発を行っていきます。
機械学習を用いたユーザーの体験向上
ハンドメイドマーケット「minne」の行動ログを用いて複数の機械学習モデルを開発し、その活用によってユーザーの体験向上を図っています。
- 作品名から作品カテゴリを分類するモデル(作品の検索時や登録時の利便性向上)
- 大量生産品の出品者を検出するモデル(大量生産品の排除)
- クレジットカードの不正利用を検出するモデル(不正な決済の排除)
特に大量生産品の出品は minne の根本的なブランドイメージや信頼性の毀損に繋がるため、本年の早い時期から取り組んできました。研究成果は情報処理学会の研究会予稿としてまとめ、第41回インターネットと運用技術研究会 (IOT41) で発表を行っています。テストデータにおいて90%以上の精度で検出を行えており、目視で全商品を検査する場合に比べて、サービス運用の時間的なコストを従来の5分の1から8分の1程度に削減することが可能になりました。
ユーザーのみなさんに、サービスを通してより良い体験をしていただけるよう、今後も継続して開発を行っていきます。
まとめ
この記事では、2018年のペパボのデータサイエンティストの取り組みのうち3つを振り返りました。
デザイン戦略チームでは、エンジニアの @gyugyu によるツール開発(ペパボで利用されているデザイン力を可視化するツール「UXボード」を公開しました)や、チーム全体の振り返り(デザイン戦略チームの大ふりかえり2017〜2018)についてもこのブログでご紹介しています。ぜひご覧ください。



