
- はじめに
- 課題:assets が コンテナイメージに焼き込まれる構造的問題
- S3 Files という選択肢
- アーキテクチャ設計
- 実装: lens2(Rust)で先行検証
- ハマりどころ: EFS CSI Driver を動かしてわかったこと
- 計測結果
- lens(JavaScript)へのロールアウト
- まとめ
はじめに
こんにちは、技術部技術基盤グループで SUZURI / minne / カラーミーショップなどのインフラをサービス横断で担当している shibatch です。
SUZURI は、オリジナルグッズを手軽に作れる・購入できるサービスです。ユーザーがアップロードした画像とあらかじめ用意した商品テンプレート(assets)を合成して、Tシャツやマグカップの完成イメージを生成する「画像合成サービス」が中核を担っています。この処理を担うのが lens と lens2 という 2 つのサービスです。
- lens: JavaScript + ImageMagick 製の画像合成サービス(主力)
- lens2: Rust + ImageMagick 製の画像合成サービス(新世代、lens から段階的に移行中)
2 サービスを合わせると 1 日最大約 420 万リクエスト(月間約 1.1 億リクエスト) を本番処理しています。
今回はそのlens/lens2に、2026年4月7日にGAとなったばかりの Amazon S3 Files を本番EKSに投入した話をします。トラフィックの少ないlens2でスモールスタートし、ゴールデンウィークをまたいでレイテンシの実績を積んでからlensへ展開する、という段階的なリスク設計で進めました。その過程と計測結果をお伝えします。
課題:assets が コンテナイメージに焼き込まれる構造的問題
lens/lens2 が扱う assets とは
lens/lens2 が扱う assets は、SUZURI で販売されるすべての商品テンプレート——Tシャツ・マグカップ・トートバッグなどの型紙画像、フォントファイル、ウォーターマーク画像——の集合です。新商品が追加されるたびに増え続けます。
移行前の状況
移行前は assets がそのまま コンテナイメージに焼き込まれていました。
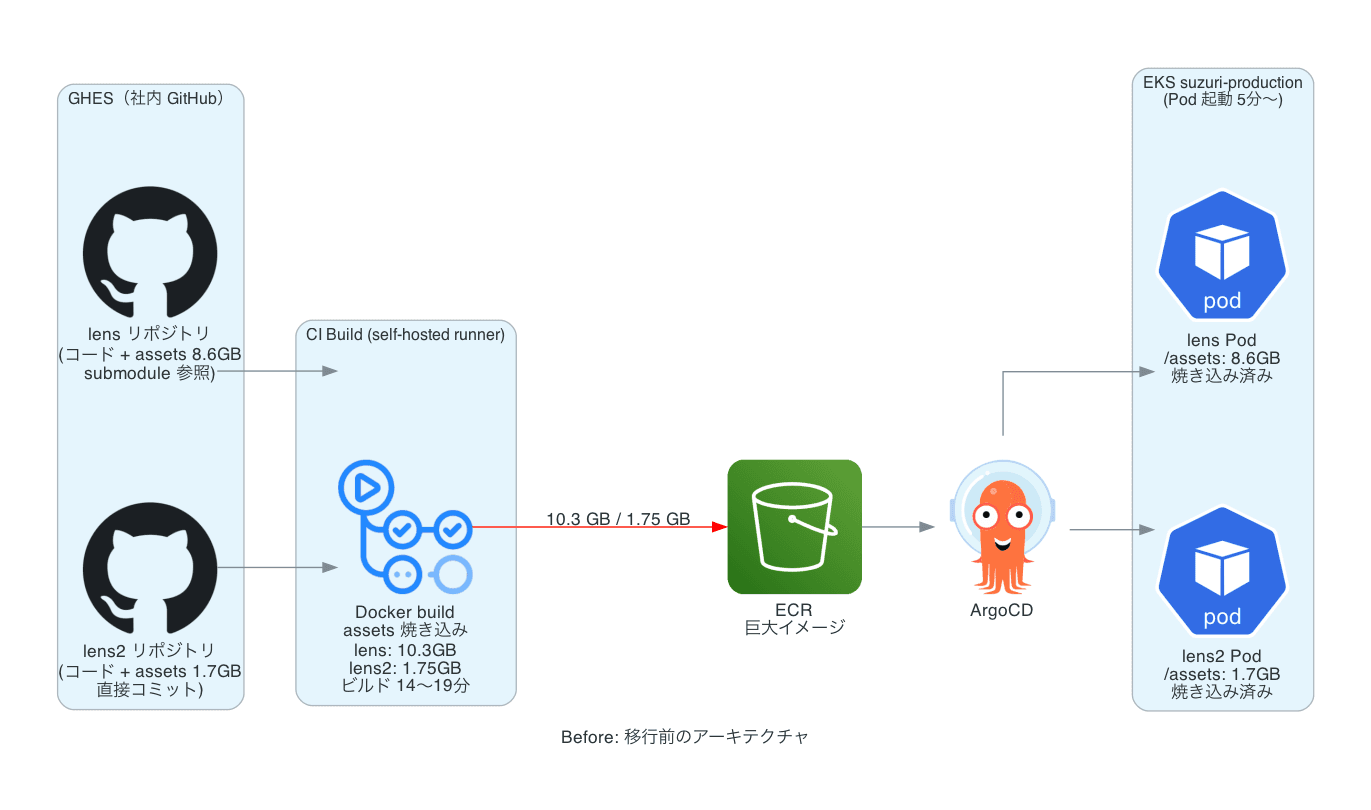
| サービス | assets サイズ | コンテナイメージ(ECR 圧縮後) |
|---|---|---|
| lens2 | 1.7 GB | 1.75 GB |
| lens | 8.6 GB | 10.3 GB |
これはビルドパイプライン全体に悪影響を与えていました。lens のビルド時間を実測すると次のような内訳です。
| ステップ | 所要時間 | 原因 |
|---|---|---|
| assets の S3 sync(毎ビルドダウンロード) | 2m 08s | 8.6 GB を毎回取得 |
| コンテナビルド & push | 11m 43s | assets を含む巨大レイヤーの書き出し |
| 合計 (wall-clock) | 14m 31s | CI の初期化・checkout 等含む |
さらに Karpenter による新規ノード追加時(キャッシュなし)の Pod 起動には、イメージサイズが直撃します。
| サービス | Image pull(cold) | Pod Scheduled→Ready(cold) |
|---|---|---|
| lens2 | — | 86〜102 秒 |
| lens | 5 分 03 秒 | 約 5〜5.5 分 |
トラフィックスパイク時にスケールアウトが発動しても、5 分間は新規 Pod を利用できません。SUZURI ではセール開始などをきっかけにトラフィックが急増するため、このスケールアウト遅延は売上機会の取りこぼしに直結します。
さらに問題があります。lens から lens2 への移行が進むと lens2 の assets も最終的に 8.6 GB 相当まで増える見込みでした。放置すれば状況はさらに悪化します。
S3 Files という選択肢
当初の候補: EFS + DataSync
assets を コンテナイメージから切り離し、ネットワークファイルシステム経由でマウントする構成を検討していました。当初の有力候補は Amazon EFS + AWS DataSync の組み合わせです。S3 を source of truth として、DataSync で定期同期した EFS ボリュームを EKS Pod に NFS マウントする構成です。
ただし、この方式には課題がありました。S3 への push が EFS に反映されるまで同期ラグが生じるため、assets の鮮度管理が複雑になります。また DataSync パイプライン自体の構築・運用コストも無視できません。
2026 年 4 月 7 日 GA: Amazon S3 Files
アーキテクチャを検討していたタイミングで、AWS が Amazon S3 Files を GA リリースしました。
S3 バケットをバックエンドとして、NFS 4.1/4.2 でマウントできるファイルシステムを提供するサービスです。
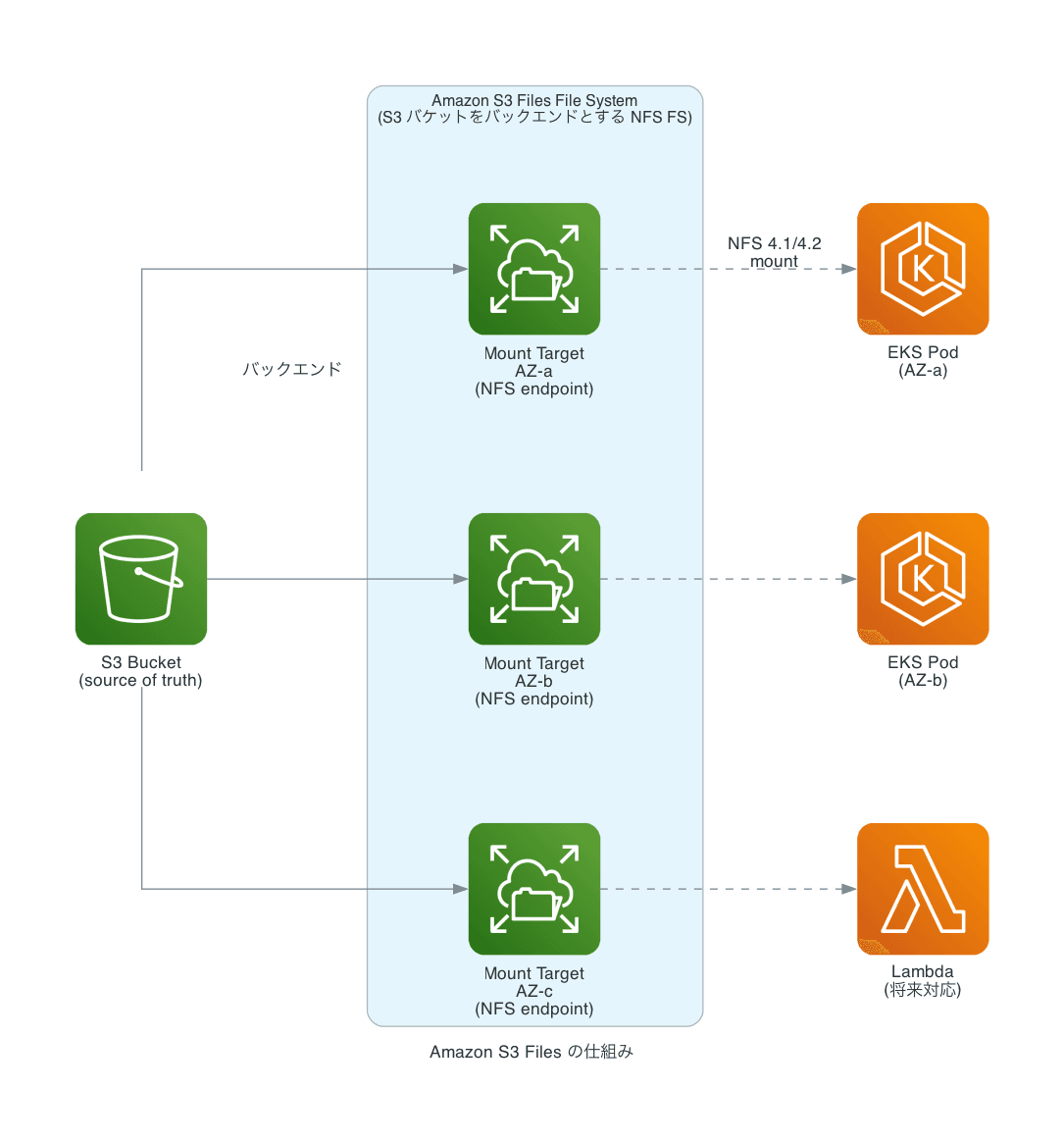
| 特性 | 値 |
|---|---|
| プロトコル | NFS 4.1 / 4.2(POSIX セマンティクス準拠 ※ハードリンク等は非対応) |
| 小ファイルの読み取り(キャッシュ済み) | 数 ms 以下 |
| キャッシュの読み取りスループット | 4.7 GB/s |
| 大ファイル(≥ 128 KB) | S3 から直接ストリーム(サービス全体の集約スループット テラバイト/秒) |
| 対応コンピュート | EC2 / EKS / ECS / Lambda |
決め手は DataSync が不要になる点でした。 S3 が source of truth を維持したまま NFS マウントできるため、同期ラグも余分なパイプラインも生じません。また Lambda でも S3 Files マウントが使えるため、将来的な Lambda 化の道筋も確保されます。
これならやろうとしていたことがスマートに実現できる、作り込もうとしていたDataSync部分をまるごと捨てて、S3 Filesへの切り替えを決めました。
アーキテクチャ設計
移行後の全体像
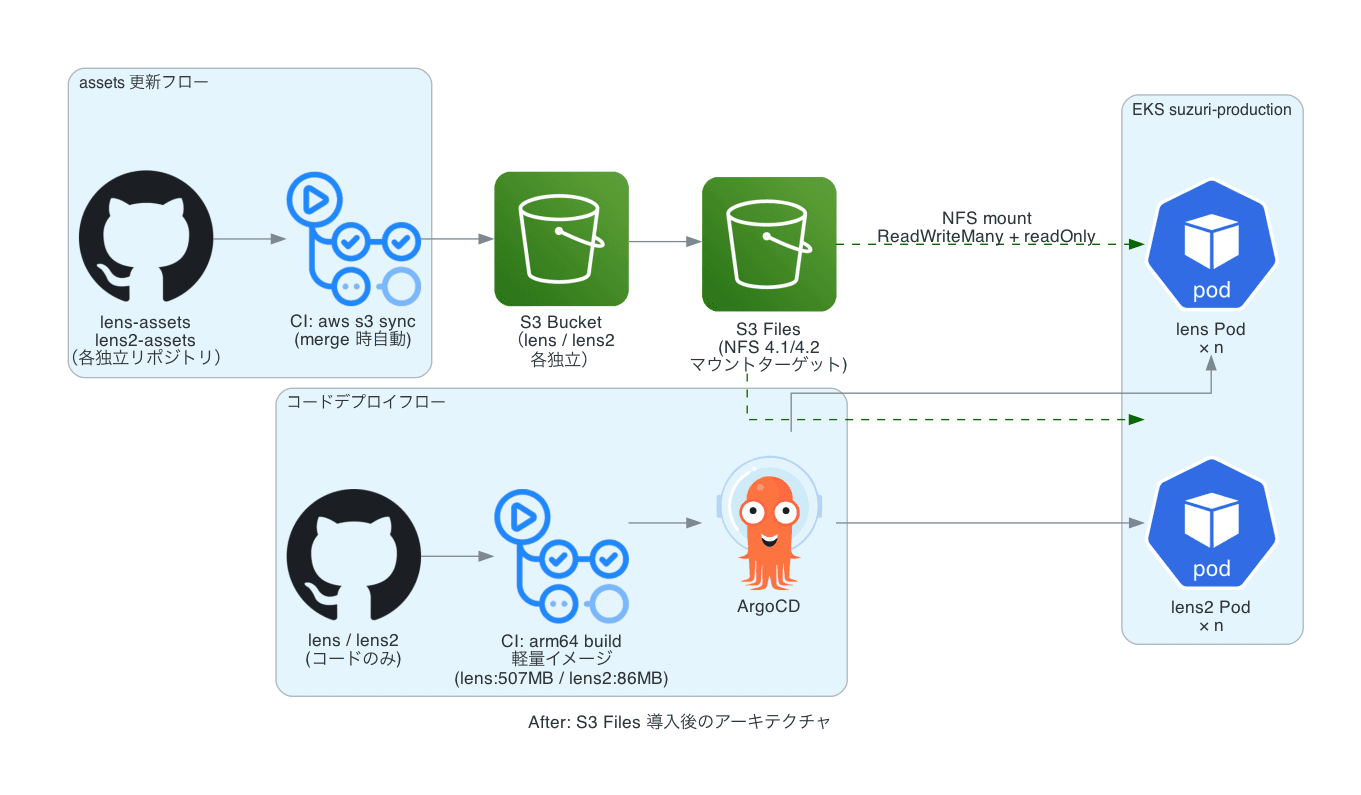
設計のポイント
assets をコードリポジトリから完全分離する
lens は以前から assets 専用のリポジトリが分離されており、デザイナーはそこに PR を出す運用でした。lens2 では assets がコードリポジトリに直接コミットされていたため、専用の assets リポジトリを新設してデザイナーの PR 先を切り替えました。
どちらも assets リポジトリへのマージ時に CI が aws s3 sync を実行し S3 に同期します。S3 Files 経由で Pod への反映はほぼリアルタイムです。
ゼロダウンタイムの段階的移行
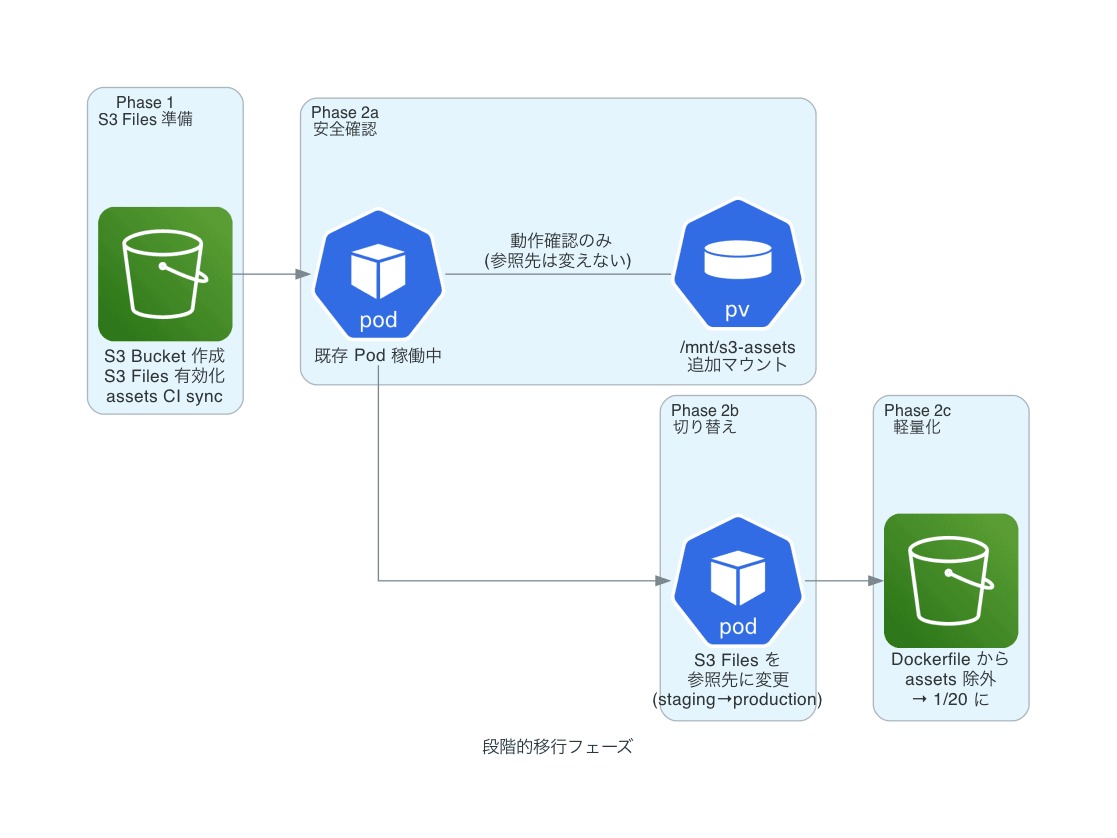
Phase 1: S3 バケット作成 + S3 Files 有効化
Phase 2a: 既存 Pod に S3 Files を追加マウントして動作確認
Phase 2b: assets の参照先を S3 Files に切り替え
Phase 2c: Dockerfile から assets を除外 → イメージ軽量化
Phase 2a がこの設計の安全弁です。既存イメージを稼働させたまま別パスに S3 Files をマウントし、ファイルの内容とレイテンシを確認します。マウントに失敗しても Kubernetes の rolling update により旧 ReplicaSet がそのまま動き続けるため、本番トラフィックへの影響はゼロです。なお Phase 2c 以降はイメージから assets が除去されるため、fat image への即時ロールバックは現実的ではありません。S3 Files の可用性に依存した設計となる点は後述します。
実装: lens2(Rust)で先行検証
EKS への S3 Files マウント
EFS CSI Driver v3.0 以降が S3 Files に対応しています。通常の EFS ボリュームと同じ CSI ドライバーを使いますが、設定にいくつか注意点があります(後述の「ハマりどころ」を参照)。
# PersistentVolume
apiVersion: v1
kind: PersistentVolume
metadata:
name: lens2-assets
spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteMany
mountOptions:
- iam
csi:
driver: efs.csi.aws.com
volumeHandle: "s3files:fs-xxxxxxxxxxxxxxxxx" # s3files: プレフィックス必須
readOnly: true
# Deployment への追加
volumeMounts:
- name: s3-assets
mountPath: /mnt/s3-assets
readOnly: true
volumes:
- name: s3-assets
persistentVolumeClaim:
claimName: lens2-assets
readOnly: true
Phase 2a: 動作確認(並列マウント)
Phase 2a では mountPath: /mnt/s3-assets に S3 Files を追加マウントするだけです。アプリの参照先(ASSETS_DIR)はまだ変更しません。Pod に入って find /mnt/s3-assets | wc -l でファイル数を確認し、イメージ内の assets とファイル数が一致することを確かめます。
Phase 2b: ASSETS_DIR 切り替え
動作確認が取れたら、ConfigMap で ASSETS_DIR=/mnt/s3-assets に切り替えます。staging → production の順に適用し、各ステップで Datadog APM のレイテンシに異常がないことを確認します。
Phase 2c: Dockerfile から assets を除外
ASSETS_DIR の参照先が S3 Files に切り替わったことを確認してから、Dockerfile を変更します。
# Before(削除する行)
COPY ./assets ./assets
COPY --from=builder /lens2/assets /lens2/assets
# After: 上記 2 行を削除するだけ
これでイメージから assets が消え、ビルドと pull が劇的に速くなります。
ハマりどころ: EFS CSI Driver を動かしてわかったこと
ドキュメントに記載のない制約が複数ありました。同じ問題に直面した方の参考になれば幸いです。
1. inline (Ephemeral) CSI volume は非対応
Error: volume mode 'Ephemeral' not supported by driver efs.csi.aws.com
S3 Files のマウントには PersistentVolume / PersistentVolumeClaim が必要です。Pod spec へのインライン定義(Ephemeral volume)はサポートされていません。
2. accessModes: ReadOnlyMany が非対応
ReadOnlyMany と書くとマウントに失敗します。ReadWriteMany で宣言し、PV の csi セクション・PVC 参照(volumes セクション)・volumeMount の3か所すべてに readOnly: true を設定するのが実際に動作した方法です。上のコード例ではすべての箇所に記載されています。
3. volumeHandle に s3files: プレフィックスが必須
通常の EFS では fs-xxxxxxxxxxxxxxxxx のみ指定しますが、S3 Files では必ず s3files:fs-xxxxxxxxxxxxxxxxx の形式にしなければなりません。プレフィックスがないと通常の EFS ボリュームとして解釈されてマウントに失敗します。
4. mountOptions: [iam] の明示指定が必要
mountOptions への iam の明示指定は省略できません。 ドキュメント(docs/parameters.md)では optional な mountOption の一例として列挙されているだけで、デフォルト適用はされません。省略すると mount 時に access denied by server が返ります。
5. controller SA と node SA に別々の IAM ロールが必要
EFS CSI Driver の controller pod と node plugin pod はそれぞれ異なる ServiceAccount を使います。両方に S3 Files へのアクセス権を持つ IAM ロールを割り当てる必要があります。Pod Identity を使う場合も同様です。片方だけ設定してもマウントが通りません。
補足: S3 Files 障害時の挙動と監視
Phase 2c 以降、コンテナイメージから assets が除去されるため、S3 Files が停止すると lens/lens2 の画像合成機能が利用不可になります。fat image への即時ロールバックは assets をリポジトリから削除済みのため現実的ではなく、S3 Files の可用性に依存した設計です。
この点への対策を整理します。
- 可用性: S3 Files は EFS の基盤上に構築されており、データは S3 に保存されます。S3 の SLA は月次稼働率 99.9% で、複数 AZ に冗長化されています。S3 Files が停止しても S3 バケット内のデータは保全されるため、S3 Files の復旧後に自動復旧します
- 監視: Datadog APM・外形監視・レイテンシ監視により異常を検知できる体制を整えています
- NFS オプション: soft マウントやタイムアウト設定で NFS I/O ブロック時の挙動を調整することもできますが、lens2 での本番運用で pod 起動やレイテンシに支障がなかったため、今回はデフォルト設定のまま運用しています。詳細は AWS 公式ドキュメント を参照してください
計測結果
lens2(Rust)本番実測
Before の値は assets をイメージに焼き込んでいた移行前の実測値です。
| 指標 | Before | After | 改善 |
|---|---|---|---|
| ECR image size(圧縮後) | 1.75 GB | 86 MB | 約 1/20 |
| Build wall-clock | 19m 19s | 3m 43s | 約 80% 削減 |
| Pod Scheduled→Ready(cold) | 86〜102 s | ~39s | 約 60% 削減 |
| レンダリングレイテンシ(avg) | 158.4 ms | 153.8 ms | 劣化なし(微改善) |
lens(JavaScript)本番実測
Before の値は S3 Files 導入前の実測値です。
| 指標 | Before | After | 改善 |
|---|---|---|---|
| ECR image size(圧縮後) | 10.3 GB | 507 MB | 約 1/20 |
| Build wall-clock | 14m 31s | 1m 48s | 約 88% 削減 |
| Image pull(cold) | 5m 03s | 11〜34s | 約 1/9〜1/27 |
| Pod Scheduled→Ready(cold) | 5〜5.5 分 | ~45s | 約 85% 削減 |
| レンダリングレイテンシ(avg) | ~5.1s | ~4.9s | 劣化なし |
S3 Files の読み取りレイテンシ(lens 本番実測)
| ファイル | サイズ | 初回アクセス | warm(2 回目以降) |
|---|---|---|---|
| NotoSansJP-Medium.otf | 4.6 MB | 272 ms | ~2.7 ms |
| watermark.png | 15 KB | 3.7 ms | ~1.9 ms |
| checkerboard.png | 14 KB | 10.4 ms | ~2.0 ms |
| item 画像(1.2 MB) | 1.2 MB | 247 ms | ~2.4 ms |
| item 画像(15.4 MB) | 15.4 MB | 343 ms | ~3.4 ms |
初回アクセスはファイルサイズに比例して数 ms〜数百 ms かかります。2 回目以降はキャッシュに乗り 2〜3 ms 台に収まります。
アプリレイヤーへの影響はほぼゼロです。 lens のレンダリング処理は ImageMagick の CPU 処理がボトルネックで 1 リクエストあたり平均 5 秒程度かかります。warm 状態での 2〜3 ms という読み取りレイテンシは、処理時間全体に対して誤差の範囲です。Datadog APM でも本番レンダリングレイテンシに劣化は確認されませんでした。
lens(JavaScript)へのロールアウト
lens2 での実装・検証を経て、lens への展開は設計の差分を埋めるだけで済みました。
lens ならではの差異: 上書きマウント方式
lens2 では ASSETS_DIR 環境変数で assets パスを切り替えられましたが、lens は path.resolve('assets/...') + PM2 の cwd: '/suzuri-lens' でパスがハードコードされているため、環境変数による切り替えができません。
そこで S3 Files を /suzuri-lens/assets に直接マウント(既存パスを shadow するボリュームマウント) する方式を採用しました。アプリ側のコード変更は一切不要で、Kubernetes マニフェストの mountPath をアプリの参照パスに合わせるだけです。
# lens の場合: アプリの参照パスに直接マウントして shadow
volumeMounts:
- name: s3-assets
mountPath: /suzuri-lens/assets # アプリの参照先パスと一致させる
readOnly: true
Phase 2b では「既存イメージ(assets 焼き込み)+ S3 Files の上書きマウント」の並存状態になります。どちらのソースから読んでも内容は同一なので、切り替えは透過的です。Phase 2c で軽量イメージに更新すると、S3 Files が唯一の assets ソースになります。
lens2 のノウハウがそのまま活きた
EFS CSI Driver の制約はすべて lens2 の試行錯誤で解決済みでした。PV/PVC 設定・IAM ロール構成・マウントオプションを lens2 のマニフェストからほぼそのまま流用できたため、lens の展開は短期間で完了しました。
まとめ
成果サマリ
| 指標 | lens2 | lens |
|---|---|---|
| コンテナイメージ(ECR 圧縮後) | 1.75 GB → 86 MB(約 1/20) | 10.3 GB → 507 MB(約 1/20) |
| Build time | 19m 19s → 3m 43s(80% 削減) | 14m 31s → 1m 48s(88% 削減) |
| Pod 起動(cold) | 86〜102s → ~39s(60% 削減) | 5〜5.5 分 → ~45s(85% 削減) |
| レンダリングレイテンシ | 劣化なし | 劣化なし |
上記はすべて 月間 1.1 億リクエストを処理する本番サービスでの実測値です。
S3 Files を選んでよかった点
- DataSync が不要: S3 が source of truth を維持したまま NFS マウントができる。同期ラグの問題が根本的に存在しない
- assets が増えてもイメージサイズが変わらない: 今後 lens2 の assets が増えても コンテナイメージは変わらない
- EKS / ECS / Lambda に横展開できる: 将来の Lambda 化へのパスが確保されている
- GA 直後でも実用レベルに達している: 2026 年 4 月 7 日 GA、5 月 7 日には lens/lens2 両方で本番稼働中
さいごに
正直、GA直後のサービスを本番に入れることにはリスクがありました。GA当日は2026年4月7日で、lens/lens2両方がそろったのがゴールデンウィークを挟んだ5月7日です。実質3週間ほどでここまでできたのは、lens2でスモールスタートしてからlensへ展開するという段階的な設計が効いていたと思います。lens2のほうがトラフィックが少ないため、仮に問題が起きてもロールバックできる状態で実績を積み、ゴールデンウィーク中にレイテンシの計測実績を蓄積してからlensへ投入するという順序があったからこそ、自信を持って進められました。「新しいものを本番に入れることにリスクがある」のは、裏を返せば計測と段階的な設計で解決できる問題でした。この取り組みがどなたかの背中を押せたら嬉しいです。



