はじめに
こんにちは。ロリポップ・ムームードメイン事業部でエンジニアリングリードをしています kinosuke01 といいます。
生成AIを組み込んだアプリケーションを事業として提供するとき、避けて通れないテーマが コスト です。
事業としてやっている以上、売上・利益・粗利率には当然ながら目標値があります。開発者としても「技術的に動けばOK」ではなく、その数字を前提にしたうえで、お金のことも勘案して設計や実装を進める必要があります。
ところが生成AIをAPI経由で使う場合、消費トークン数による従量課金となるため、事前にどの程度のコストになるのかを見積もるのが一筋縄ではいきません。
とくに生成AIが自律的に判断・分岐するワークフローだと、入力も出力もユーザーの指示内容に大きく依存するため、「このケースで n トークン」と簡単には言い切れません。
本記事では、AIサイトエージェント開発プロジェクトで実施した、段階的にコスト試算の精度を上げていくアプローチを紹介します。完璧な見積もりを最初から作ろうとするのではなく、プロジェクトのフェーズごとに見積もり方法を変えていく話です。
前提:AI サイトエージェントというサービス
私たちが開発している AI サイトエージェント は、「カフェのサイトを作りたい」「フリーランス向けのポートフォリオが欲しい」といった自然言語の指示を投げると、ページ構成・デザインテーマ・コンテンツまでを一括で生成してくれる Web サイト制作サービスです。生成したあとも、チャット越しに「トップのキャッチを変えて」「このセクションの写真を差し替えて」と伝えれば、AI が編集を代行してくれます。

内部のワークフローは、決定論的なワークフローをベースに、一部のステップで生成AIが自律的に判断・分岐する 構造になっています。全部を生成AIに任せるのではなく、「ここは構造が決まっている」「ここは自由度を持たせたい」をフェーズごとに使い分けることで、品質と予測可能性を両立させる狙いです。
ざっくり図にすると、このような流れです。
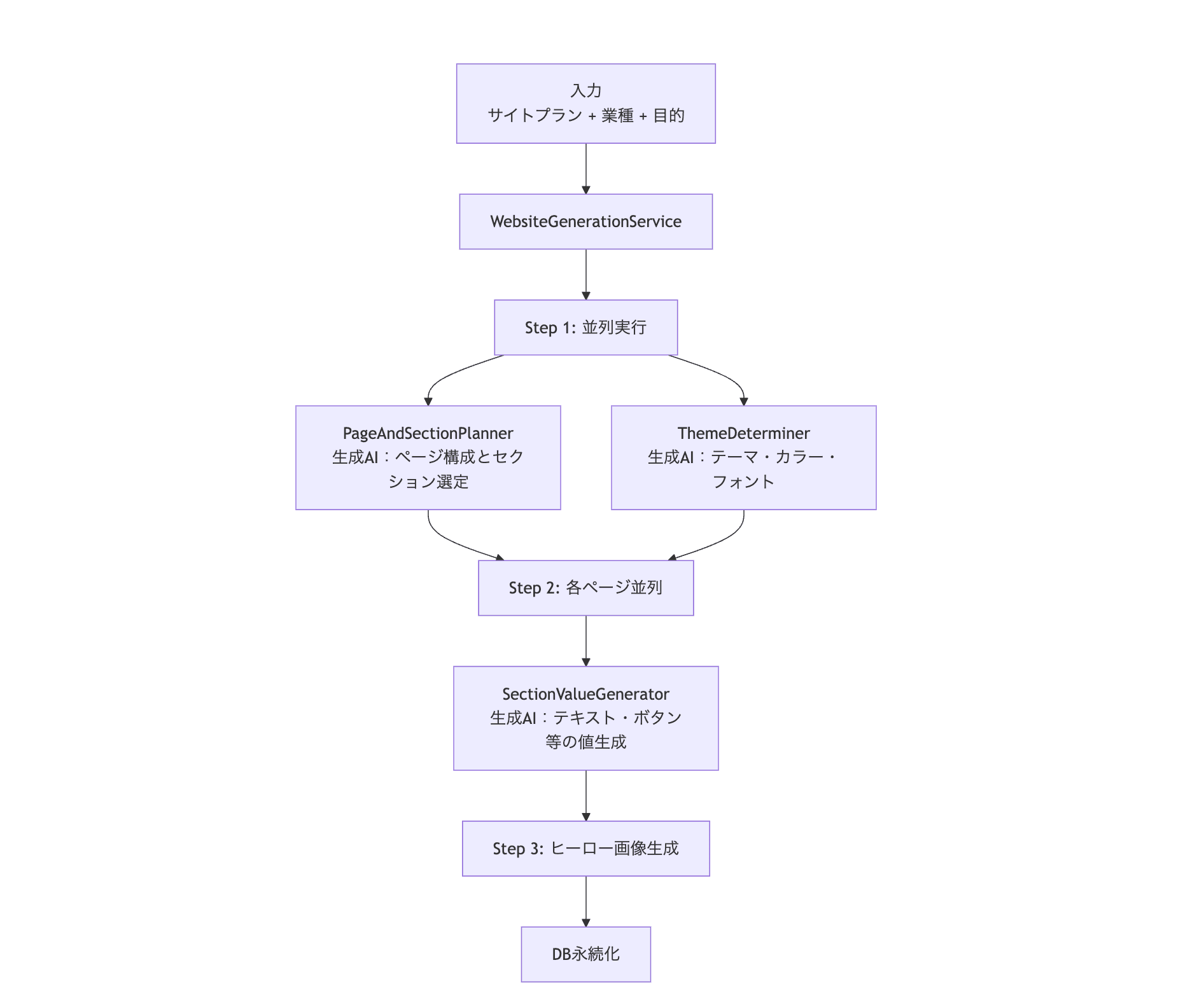
ラベルに「生成AI:」と書かれているブロックが生成AI呼び出しで、それ以外は決定論的な処理です。たとえば PageAndSectionPlanner は「ページ何枚構成にするか」「各ページにどのセクションを置くか」を、ユーザーの指示に応じて柔軟に決めます。一方で、決まったフォーマットの JSON が返ってこないと後続の処理が動かないので、Structured Output を使って構造を縛っています。
このような構造だと、単に「1 回のサイト生成で何トークン?」と問われても、ページ数・セクション数・モデルの揺らぎで大きく変わってきます。見積もりが難しいわけです。
対応方針:段階的に精度を上げる
難しいのでやらない、というわけにはいきません。かといって最初から正確な数字を出すこともできません。そこでビジネス職と以下について合意しました。
- 従量課金であり、実績に応じてコストが変動すること
- 開発の進行に合わせて、段階的に試算の精度を上げていくこと
具体的には 3 つのフェーズに分けて見積もりを更新していきます。
| フェーズ | 何を使って見積もるか | 精度 |
|---|---|---|
| 1. 設計直後 | ワークフロー骨組み + 各ステップの想定トークン数 | 概算 |
| 2. 実装後(検証環境) | 実際の呼び出しログから集計した実績値 | 中精度 |
| 3. ローンチ後 | 本番の実トラフィックに基づくモニタリング | 高精度 |
以下、それぞれのフェーズで何をやったかを見ていきます。
フェーズ 1:設計段階でざっくり見積もる
まず最初にやるべきは、ワークフロー全体の骨組みを設計することです。このとき、細部の実装よりも「どのステップで、どんなモデルを、どのくらいのトークン量で呼ぶか」を決めることに集中します。
たとえば PageAndSectionPlanner であれば、ざっくりこんな見積もりになります。
- モデル:Gemini 2.5 Flash
- 入力トークン:プロンプト(1,500)+ ユーザー指示(200)= 1,700
- 出力トークン:3 ページ分の JSON ≒ 800
(※ 上記のトークン数は説明用の仮の値です。実際の値はプロンプトの内容や出力サイズによって変わります)
これを全ステップで行い、1 サイト生成あたりの概算を出します。そこに想定利用数(例:月間 n ユーザー × 平均 m 回/人)を掛けて、ざっくりとした月額コストを算出し、ビジネス職に第一報として共有します。
この段階では精度は荒いものの、
- 「桁が合っているか」の感覚を関係者で揃える
- 「粗利率が破綻するオーダーではないか」の早期チェック
という観点で十分に価値があります。桁が想定を超えていれば、そもそもワークフロー設計を見直すべきというシグナルになります。
フェーズ 2:実装してから実データで見積もる
2 回目の見積もりに入ります。このフェーズの流れは大きく 3 ステップです。
- エッジケースは後回しにして、まず正常系が一通り動く状態まで実装する
- 生成AI呼び出しのトークン数を自動で DB に記録できるようにする
- 検証環境で実データを溜め、集計結果をもとに再見積もりする
順に見ていきます。なお 2 の実装詳細は、記事末尾の「付録:トークン数を DB に記録する仕組み」に切り出しています。
正常系を一通り動かす
このフェーズで大事なのは、エッジケースの対応は後回しにして、まず「とにかく一通り動く」ものを作ること です。
ここで言うエッジケース対応とは、たとえば以下のようなものです。
- 生成AIが Structured Output のスキーマを逸脱した JSON を返したときのサニタイズや再試行
- タイムアウトやレート制限にかかったときのリトライ制御
- 出力内容が明らかに破綻している(空文字、文字化け等)ときのフォールバック
これらは本番運用では欠かせませんが、最初から詰め始めると、実データが溜まるのがずるずる先延ばしになります。正常系さえ動けば検証環境で大半のケースは実測できるので、まずはそちらを優先します。
トークン数を自動で DB に記録する
次に、生成AI呼び出し時の「使用モデル」「入力/出力トークン数」「所要時間」などを自動で DB に記録する仕組みを入れます。PageAndSectionPlanner、ThemeDeterminer、SectionValueGenerator 等のすべてのステップで、呼び出すたびに 1 レコードが残る状態を作ります。
ポイントは、アプリケーションコード側に計測ロジックを足さずに済む形で組み込むことと、プロンプト・レスポンス本文も併せて保存しておくこと(後からプロンプト改善の材料になるため)です。具体的な実装は付録を参照してください。
実績データから見積もる
ここまで仕込めたら、あとは実データを溜めるフェーズです。検証環境にデプロイし、動作検証がてらサイト生成をひたすら回します。同じ指示文でも、モデルの揺らぎで消費トークン数は変わるため、数を回せば回すほどばらつきが見えてきます。
実績データが溜まったら、stepType ごと・モデルごとの平均トークン数を集計し、それに想定利用数を掛けて月額コストを再計算します。実際の運用では、検証環境のデータに安全係数(今回は 2 倍程度)を掛けておきました。本番では、検証環境では出なかった長いユーザー入力や、エッジケースの追加プロンプトなどが入り込むことを想定しています。
この段階で出てきた数字と粗利率の目標値を突き合わせ、ビジネス職と「このまま進められるか」「料金プランの調整が必要か」を議論します。
フェーズ 3:ローンチ後のモニタリング
ここまで来ると、ローンチして実際のユーザーの利用状況を見るだけです。フェーズ 2 で仕込んだトークン数のログを定期的に集計し、
- 1 サイト生成あたりの平均トークン数は想定どおりか
- 粗利率の目標値を脅かす動きはないか
- 特定のステップだけ異常に消費量が大きくなっていないか
をモニタリングします。想定から外れた動きがあれば、プロンプトの見直し、モデルの選定変更、もしくは料金プラン側での調整を検討します。
本番の実データという最も精度の高い情報源を持っている状態なので、このフェーズの見積もりは「見積もり」というより「実測値のトラッキング」です。ここに至って初めて、生成AIのコストは見積もりの対象ではなく、モニタリングし続ける運用指標 に変わります。
まとめ
生成AI のコストは、事前に一発で正確に見積もることは困難です。だからといって「わかりません」では済まないので、段階的に精度を上げていく という方針で進めるのが現実的でした。
- フェーズ 1(設計直後):ワークフローの骨組みとざっくりトークン数で桁を合わせる
- フェーズ 2(実装後):生成AI呼び出しをラップして実データを集め、安全係数を掛けて再見積もり
- フェーズ 3(ローンチ後):本番データで継続モニタリング、粗利率への影響をチェック
このうち効果が大きかったのは、フェーズ 2 で踏んだ次の 2 点です。
- エッジケース対応を後回しにして、一通り動くものを先に作る:実データを早く集めるには、検証環境で回せる状態に到達するのが最優先です。
- 生成AI呼び出しをラッパー化して、全ステップ自動でログ化する:計測を仕組み化しておけば、フェーズ 2 以降の意思決定が実データベースでできるようになります。
どちらか片方だけでは成立しません。動くものがあってもログが取れなければ実績はわからないし、ログの仕組みだけ整えても呼び出されなければデータは溜まらない。この 2 つを揃えることで、実データを武器に意思決定できる状態に早く到達できました。
生成AI を使うプロダクトを作る方にとって、同じ悩みを抱えている方の参考になれば幸いです。
付録:トークン数を DB に記録する仕組み
フェーズ 2 で触れた「生成AI呼び出しのトークン数を自動で DB に記録する」の実装詳細です。本筋を読み進める上では読み飛ばしても構いません。
どこに永続化するか:RDB を選んだ理由
トークン数の永続化先は、いくつか選択肢がありました。
最終的には RDB に保存する方針を選びました。理由は以下です。
- SaaS は便利だが、ベンダーロックイン を避けたい
- Langfuse OSS は魅力的だが、この時点では運用対象を増やしたくない
- RDB なら既に運用しているので追加コストが相対的に低い
将来的に実データが溜まってきたら BigQuery 等のデータウェアハウスに流す、という拡張余地は残しています。「あとで捨てられる」「あとで移行できる」選択肢を選ぶことで、意思決定のコストを下げています。
Prisma スキーマ
スキーマは必要最小限。どのステップで、どのモデルを、何トークン使ったかが後から辿れれば十分です。
model AiGenerationLog {
id String @id @default(uuid())
userId String? @map("user_id")
websiteId String? @map("website_id")
stepType String @map("step_type") // "page_and_section_plan" 等
model String @map("model") // "gemini-2.5-flash"
prompt String @db.MediumText @map("prompt")
response String @db.MediumText @map("response")
inputTokens Int? @map("input_tokens")
outputTokens Int? @map("output_tokens")
durationMs Int? @map("duration_ms")
isError Boolean @default(false) @map("is_error")
errorMessage String? @db.Text @map("error_message")
createdAt DateTime @default(now()) @map("created_at")
@@map("ai_generation_log")
}
プロンプトとレスポンスも併せて保存しています。これは、後から「このトークン数のときはこういう出力が返っていた」と振り返って、プロンプトをチューニングする材料にできるためです。
ログの書き込み処理
ログの書き込みは、ビジネスロジックに影響させたくありません。そのため、保存失敗はエラーログに残すだけで呼び出し元には伝播させない、という方針にしています。
// ai-generation-logger.ts(抜粋)
async saveLog(input: AiGenerationLogCreateInput): Promise<void> {
try {
await this.repository.save(input);
} catch (error) {
logger.error({ err: error }, "Failed to save AI generation log");
}
}
logGeneration(params: { /* ... */ }): void {
const context = getAiLogContext();
this.saveLog({
userId: context.userId,
websiteId: context.siteId,
stepType: params.stepType,
model: params.model,
prompt: params.prompt,
response: params.response,
inputTokens: params.inputTokens,
outputTokens: params.outputTokens,
durationMs: params.durationMs,
isError: params.isError,
errorMessage: params.errorMessage,
}).catch(() => {});
}
ログの保存が原因でサイト生成が失敗したら本末転倒なので、ここは割り切ります。
生成AI呼び出しをラップする
あとは、生成AIクライアント側から上記のLoggerを呼ぶだけです。モデルの呼び出し箇所に毎回 await insertLog(...) を書くのは現実的ではないので、生成AIクライアントをラップする層を 1 枚挟みます。ラッパー側で usageMetadata からトークン数を取り出し、DB 保存用のLoggerに流します。成功時だけでなくエラー時も記録したいので、try/catch の両方でログ化します。
// db-logging-model.ts(抜粋)
export class DbLoggingGenerativeModel implements GenerativeModel {
get modelName(): string {
return this.inner.modelName;
}
constructor(
private readonly inner: GenerativeModel,
private readonly stepType: string,
private readonly genLogger: AiGenerationLogger,
) {}
async generateContent(prompt: string) {
const startTime = Date.now();
try {
const result = await this.inner.generateContent(prompt);
const text = result.response.text();
this.genLogger.logGeneration({
stepType: this.stepType,
model: this.modelName,
prompt,
response: text,
inputTokens: result.usageMetadata?.promptTokenCount,
outputTokens: result.usageMetadata?.candidatesTokenCount,
durationMs: Date.now() - startTime,
});
return result;
} catch (error) {
this.genLogger.logGeneration({
stepType: this.stepType,
model: this.modelName,
prompt,
response: "",
durationMs: Date.now() - startTime,
isError: true,
errorMessage: error instanceof Error ? error.message : String(error),
});
throw error;
}
}
}
このデコレータを挟むことで、すべてのステップ(PageAndSectionPlanner、ThemeDeterminer、SectionValueGenerator 等)のアプリケーションコード側に特別な計測ロジックを足さずに、全呼び出しのトークン数を DB に記録できます。stepType をコンストラクタで受け取っているのは、「どのステップの呼び出しか」をあとから集計できるようにするためです。



