こんにちは、新卒 13 期の @donokun です。5 月中旬から参加していた新卒技術研修が 7 月末に終了しました! ペパボの新卒技術研修では、Rails やコンテナのような Web サービスを作る上で基礎的な技術と、 機械学習やセキュリティのような近年重要性が増している技術を学びます。 この記事では新卒 13 期の 4 名で、技術研修で何を行い学んだかを紹介します。
新卒研修は、技術研修以外のコンテンツもあります。そちらも紹介記事を書いているので、よかったらご覧ください。
Rails Tutorial
ここまでに引き続き、13 期の @donokun が Rails Tutorial 研修の紹介をします! 技術研修は Rails Tutorial からスタートしました。 12 日間をかけてじっくり取り組み、今後の研修の基礎を築きます。 この研修の目標は以下の三つです。
- Rails アプリケーションのコードを読み書きできるようになること
- フレームワークを用いた開発手法を知ること
- コミュニケーションを取りながら学び、アウトプットすること
Rails Tutorial 研修を通じて、Ruby や Rails、MVC アーキテクチャの知識に加えて Web 開発の共通語彙を獲得しました。
技術研修でのコミュニケーション
この記事では三つ目の「コミュニケーションを取りながら学び、アウトプットすること」に関して 研修中のエピソードを紹介します。
研修期間中はそれぞれの新卒パートナーが自身の「分報スレッド」を毎日 Slack に作成し、 疑問や質問、Rails への賞賛や文句、お腹の空き具合など、感じたことや考えたことを共有します。 メンターとの質疑応答を含めたほとんどのコミュニケーションは分報スレッドで完結するのが技術研修の特徴です。 ほんの小さな困りごとでも気軽に共有できるので、議論が活発に起こります。
研修中に投げかけた疑問から議論が発展して Rails のソースコードを読み解くこともしばしばありました。 ちょっと不思議な Rails の挙動とその仕組みを 13 期の kromiii がブログにまとめてくれたので、よかったら覗いてみてください。
Rails Tutorial 研修では 3 人のメンターが分報スレに張り付いて僕たちをサポートしてくれました。 @yoshikoukiさん、 @yukunさん、 @yanagiさん、ありがとうございました!
AWS JumpStart
@yumuです。 AWS JumpStart では、オンラインで他の会社の新卒社員と一緒に AWS のソリューションアーキテクトの方々から講義を受けました。
内容
研修は三日間行われました。 1 日目は AWS に関する基礎的な内容の講義から始まり、その後は ALB+ECS+RDS を使用したハンズオンに移りました。
2 日目は EC2 を中心とした構成でハンズオンが行われました。加えてアーキテクチャの検討も行われ、与えられたお題に基づいたアーキテクチャを個人やグループで設計しました。このアーキテクチャ検討の際に、他の会社の新卒社員との交流ができる機会もあり、有意義な時間となりました。
そして、最終日の 3 日目は Lambda を用いてサーバレスなアーキテクチャのハンズオンを体験しました。また、2 日目に考えた構成を更にアップデートするという形で、アーキテクチャ検討も行いました。
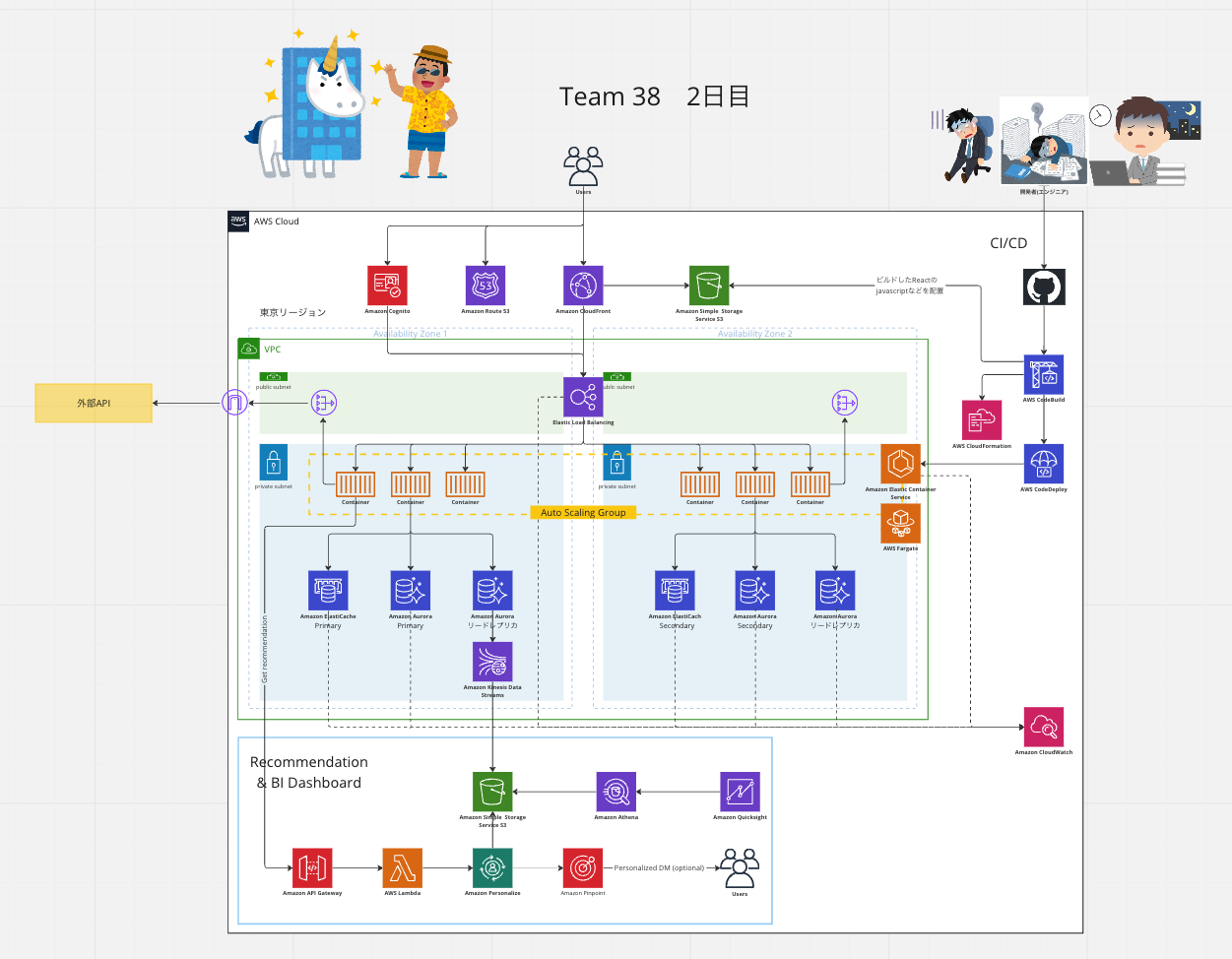
学んだこと
私は AWS に触れるのがほぼ初めてでしたが、研修を通じて多くの知識を身につけることができました。 特に、さまざまな状況や要件に応じた構成図を自分で描けるようになったことは大きな成果と感じています。 以前は理解が難しかった AWS 特有の略語や専門用語に対する恐怖感もなくなりました。 さらに、リファレンスアーキテクチャの理解と応用ができるようになったことで、より具体的なシステム設計や問題解決に役立てることができる自信がつきました。
感想
研修の内容自体は比較的簡単で理解しやすかったのですが、同時に、掘り下げようと思えば深く掘り下げることができる複雑さも感じました。 全体を通して学びが多く、とても満足感のある研修となりました。
データエンジニアリング・機械学習
新卒 13 期の @kromiiiです。私からはデータエンジニアリング研修と機械学習研修について紹介します。
データエンジニアリング研修
データエンジニアリング研修では Web サービスから得られるデータを分析するための基礎となる技術を学びました
技術要素としては大きく分けて3つあります。
一つめは BigQuery です。BigQuery はいわゆるデータウェアハウスと呼ばれるものの一つで、列指向でデータを格納することで高速にデータを処理できるようになっています。大規模な Web サービスを提供する会社では自ずとログデータの数も膨大になるため通常のリレーショナルデータベースでは処理が追いつかなくなってしまうことがありますが、そういった場合に BigQuery のようなデータウェアハウスを使うことでデータの分析を高速に行うことができるということを実際にクエリを書きながら学びました。
二つ目は Locker Studio です。Locker Studio は BigQuery で取得したデータを可視化するためのダッシュボードで、リアルタイムにクエリを発行して最新のデータを可視化することができます。研修では BigQuery で取得したデータを Locker Studio で可視化することで、データの分析をより効率的に行う方法を学びました。
三つ目は Embulk です。Embulk はデータ分析の基礎である ELT (Extract-Load-Transform) の Extract と Load に当たる部分を効率化するツールです。データを取得する部分はこれまであまり意識してこなかったのですが、Embulk のようなツールを使うことでデータの取得を効率化できるということを学びました。
機械学習研修
機械学習研修では機械学習モデルの基礎と大規模言語モデルの基礎を学びました。基礎的な事項については Google の Machine Learning Handson を使って勉強しましたが、最近のトレンドである大規模言語モデルについてはペパボ研究所の @watasan から直々に講義を受けて学びました。
当日の資料はこちらに公開されているので、興味のある方はぜひご覧ください。
私が一番印象的だったのは ChatGPT に代表される大規模言語モデルでは単にデータを学習するだけでなく、人間にとって好ましい回答を生成するように人力のチューニングが行われているというところで、LLM も意外と泥臭い作業が積み重なってできているんだなということを学びました。
LLM についてはまだまだ研究が進んでいる段階なので、今後も引き続き注目していきたいと思います。
コンテナ・DC 見学
新卒 13 期生の@n01e0です。コンテナ研修の真実をお話します。
コンテナ研修は 6/13 ~ 6/23 の日程で行いました。
期間中にはデータセンターの見学にも行きました。
DC 見学
具体的な場所は書くことができませんが、コンテナ研修の一環としてデータセンターへ行き、私たちが普段触っているコンテナや VM が実際に動いているサーバーを見てきました。データセンターへ行くのは初めての経験です。クラウドネイティブな Z 世代である私たちにとって、サーバーの排熱を肌で感じるのはなかなかできることではありません。普段、ソフトウェアの冗長性について考えたり学んだりすることはありますが、ハードウェア・電気のレベルで冗長化された設備の説明は圧巻でした。
サーバーを担ぐという貴重な体験もさせて頂きました。自分は 1/4U より大きいサーバーを持ち上げるのは初めてだったので緊張したものの、腰もサーバーも無事でした。
コンテナ研修のゴール
- コンテナ関連技術に触れることができる
- 自分でコンテナをやってみたい!と思ったときに何をやればいいかが分かる
- 自分でアプリケーションをコンテナを用いて動かすことができる
- コンテナを使う利点と欠点を理解できる
- クラウド関連技術に触れることができる
- デプロイ関連技術に触れることができる
- コードを用いてデプロイを自動化できる
- デプロイ自動化の利点を手を動かして理解できる
- 標準化、抽象化について実践で使える理解を得られる
- 標準化を実際のプロダクトに適用できる素養を養う
- 抽象化を実際のプロダクトに適用できる素養を養う
研修の内容
- Docker Hands on
- Infrastructure as a Code Hands on
- GitHub Actions Hands on
- Kubernetes を利用したアプリケーション公開
具体的な研修の内容については公開されている資料をご覧ください。
コンテナ(物理)の歴史から始まった研修は、各セクションが演習と追加課題で構成されており、時間内に演習を終えた後は追加課題に取り組むことができる構成でした。
Dockerfile を記述してコンテナをビルド、起動する演習から「コンテナランタイムを使わずにコンテナを立てる」追加課題まで走り切ることができました。
Kubernetes を利用したアプリケーション公開では、AWS JumpStart で学んだ知識も活用し、Rails Tutorial で作成したアプリケーションを EKS 上にデプロイしました。
セキュリティ
セキュリティ研修では Flatt Security のサービスである KENRO を使って、脆弱性への攻撃および修正の仕方を学びました。
また、それ以外にも社内のセキュリティ対策組織やインシデントレスポンスの流れについても講義を受けました。
KENRO
KENRO では、6 つの言語で作成されたアプリケーションの脆弱性に対して、実際に攻撃を行った後、ソースコードを読んで修正を行う演習にも取り組みます。
せっかくなので普段触らない言語にも取り組もうと思い、すべてのソースコードに目を通しましたが、基本的に修正は「フレームワークの機能を正しく使う」という対応が多く、あえて道を外れるならば相当な覚悟が必要になることがわかりました。
Web アプリケーションの脆弱性に関する知識に乏しい自分でも、テキストを読みながら攻撃を行い、ソースコードの修正まで体験できる非常に良い教材でした。
ISUCON
@kromiiiです。ISUCON 研修では本番の ISUCON を模した設定でパフォーマンスチューニングの基礎を学びました。ISUCON とはコンテスト形式で Web サービスのパフォーマンス改善スキルを競うものです。研修では仮想の写真投稿サービスを対象に、サイトのレスポンスタイムを短くするためのチューニングを行いました。具体的には Web サーバーの設定を変更したり、データベースのインデックスを追加したり、アプリケーションのコードを書き換えたりすることでレスポンスタイムを短くするなどです。
2人 1 組でチームを組んで参加するのですが、私は @homirun さんとペアを組んで「古代インデックス神社」という名前で参加しました。
研修で @homirun さんから学んだことは ISUCON の真髄とも言える「推測するな、計測せよ」ということです。研修中は htop や alp を使ってボトルネックになっていそうな箇所を特定して、そこを優先的に改善することでサイト全体のパフォーマンスを上げていくというアプローチをとりました。このアプローチが功を奏し、古代インデックス神社は最終的に全体の中で 6 位に入賞することができました。スコアが上がるたびに二人で歓喜したのはいい思い出です。
フロントエンド
@yumuです。 フロントエンド研修は、@tascriptさん、@kazuhi-raさん、@sangunさんのご指導のもと、6 日間ほど行われました。
内容
JavaScript や TypeScript、宣言的 UI の概要を学んだ後、「自由にフロントエンド技術を使用して何かを作成する」というテーマで開発を行いました。
私は「不動産投資のキャッシュフロー(CF)シミュレータ」を作りました。 このシミュレータには、物件価格や家賃を入力すると CF をシミュレーションする機能や、シミュレーション条件を保存・再呼び出しする機能が含まれています。 フロントエンドは React×TypeScript、バックエンドは express と prisma を使用しました。 Jest と React Testing Library を使ったテストも書きました。
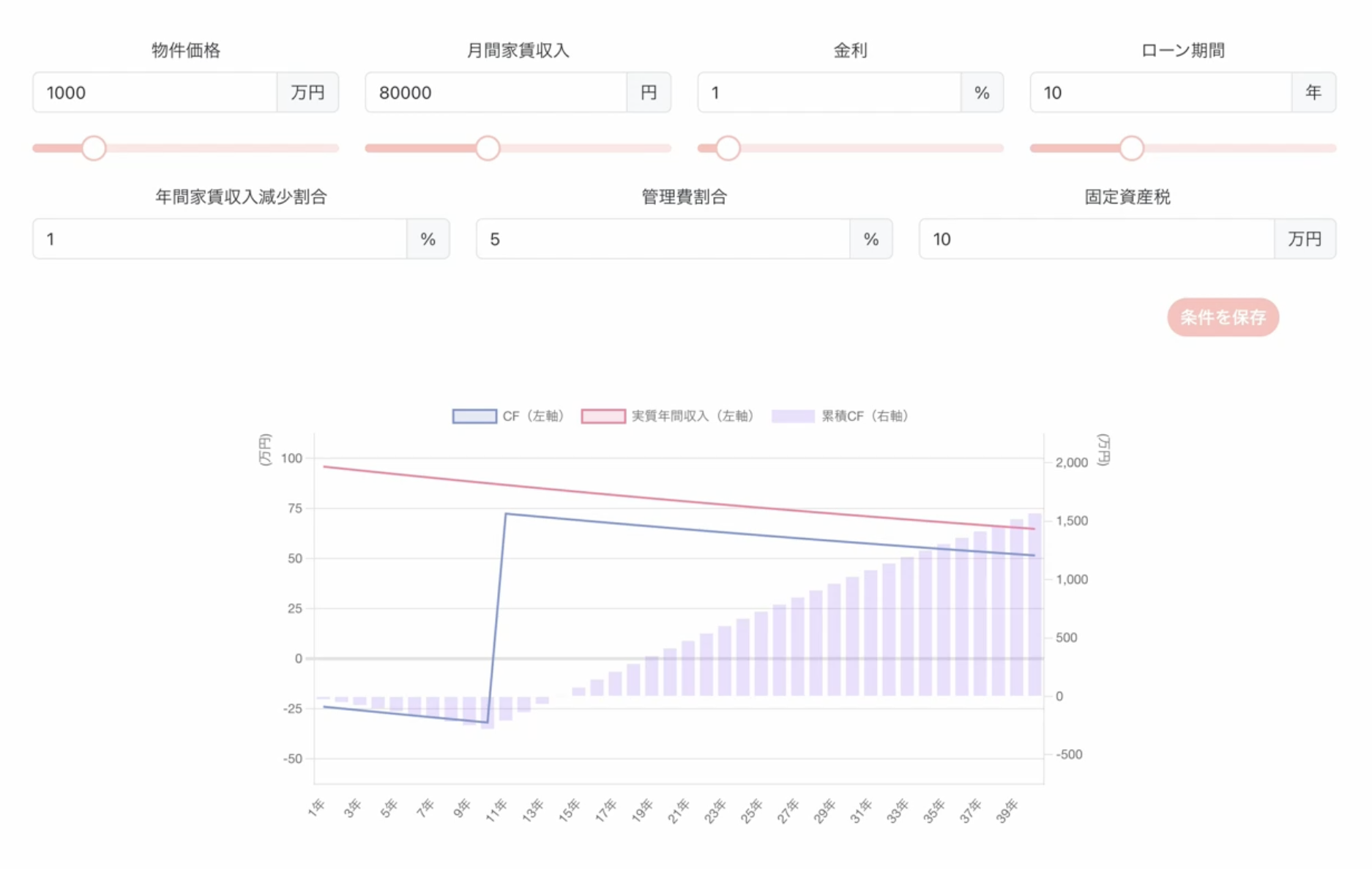
学んだこと
静的型付けになじみがなかったため、TypeScript の「型」というのが最初は難しく感じましたが、慣れてくると型を定義するメリットが感じられるようになりました。 また、適切な技術の選択、データベースとの連携、ディレクトリ構成、コンポーネントの分割など、多くの学びを得ることができました。
感想
以前はフロントエンド技術に慣れておらず、少し抵抗感がありましたが、この研修を経て、その魅力を存分に感じることができました。 特に、TypeScript の型の恩恵を受けて、コードの可読性が向上したのは大きな収穫でした。
AI わいわい
AI わいわいでは研修の総仕上げとして、事業部に分かれて OpenAI API を用いたサービスの開発を行いました。 研修で身につけた技術をもとに実際にサービスを開発することで、サービス開発の難しさを体感するとともに、研修の成果を確認しました。
yumu @SUZURI 事業部
@yumuです。 私は SUZURI 事業部で開発を行いました。
取り組んだ内容
SUZURI のキャラクターであるスリスリくんと対話可能な web アプリケーション、スリスリ AI チャット(以下、スリチャ)の改良を行いました。 スリチャの内部では、LangChain という LLM の機能を拡張できるライブラリを利用し、OpenAI API を利用して各種処理を行っています。 ここでは、今回開発した機能の中で代表的なものをご紹介します。
-
キーワード検索機能:「花柄のスマホケースが欲しい!」といった入力に対し、「花々」「花束」などのキーワードを表示します。キーワードをクリックすると、チャット上にそのキーワードに関連するアイテムが展開され、よりスムーズに商品を検索できるようになりました。
-
類似画像検索機能:SUZURI の Web アプリに元々存在していた T シャツの類似画像検索機能を API 化しました。これにより、スリチャで T シャツの類似画像検索が可能になり、お目当ての商品に素早くたどり着くことができます。
-
ベクターサーチ:LangChain の Vector Stores 機能を導入し、アイテムに関する質問に答えられるようになりました。アイテム情報をベクトルデータに変換し、質問が入力されたときに、その質問に近いデータをベクトルデータの中から引き出すことで回答しています。
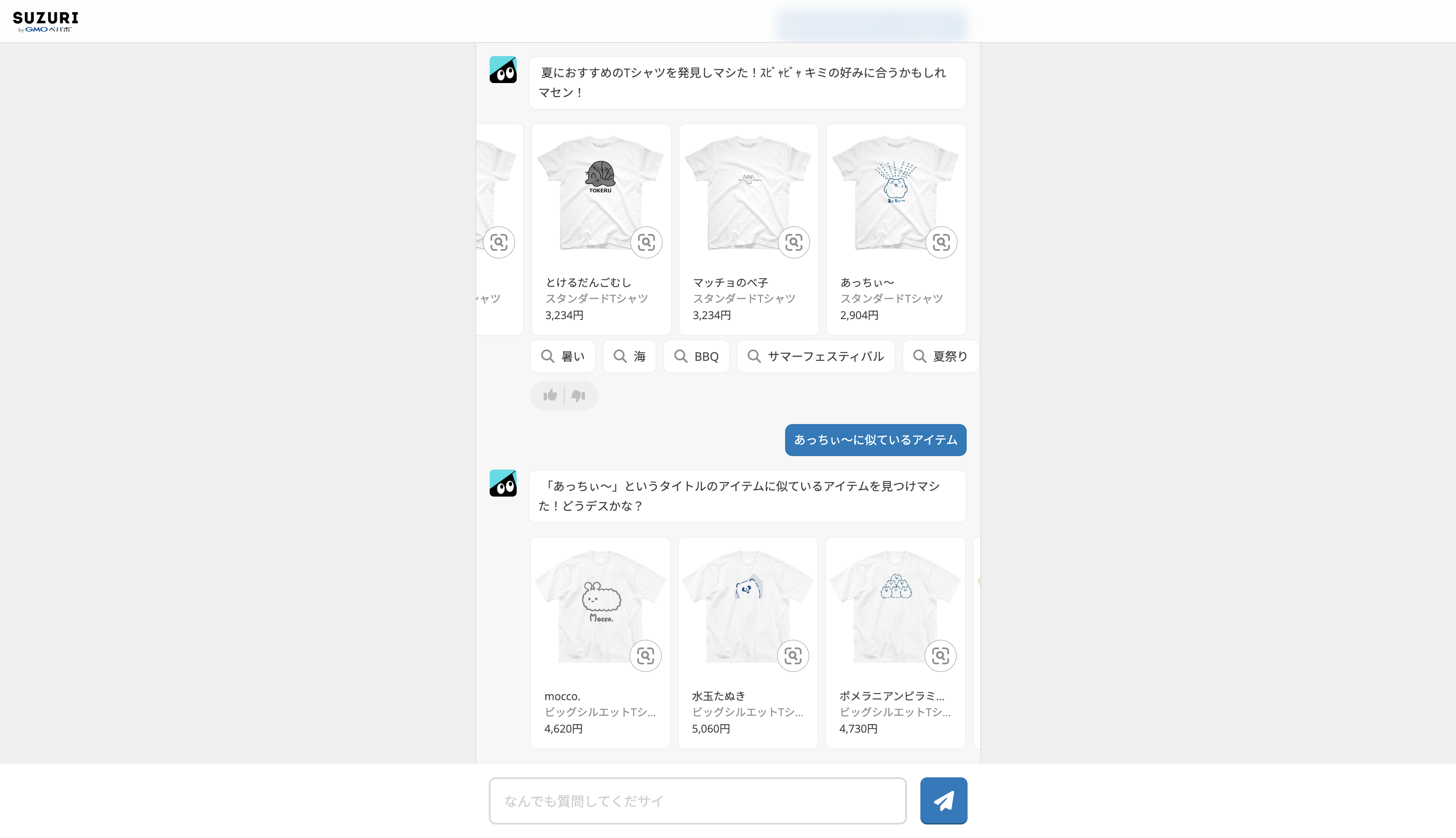
難しかった点
開発中、特に難しかったのはプロンプトの調整と Agents の設定です。 プロンプトは、言い回しを変えただけで出力が全く変わるなど、思わぬ動きをすることが多かったため、さまざまな表現を試して適切なプロンプトを模索しました。 また、ユーザーの入力に応じて最適なツールを選択する LangChain の機能である Agents の扱いも大変でした。 ツールの選択の判断基準となる description を過不足なく記述するのが難しかったです。
感想
AI わいわい開発を通して、12 日間で 12 個のリリースを行い、スリチャを大きく進化させることができました。 中にはささいなアップデートも含まれていましたが、限られた時間の中で最大の成果を追求することができたと思っています。 これから始まる OJT でもスピード感を持って開発に取り組んでいきます!
donokun & kromiii @EC 事業部
@donokun と @kromiii は EC 事業部で開発を行いました。
取り組んだ内容
私たちが取り組んだ内容は AI による商品宣伝文の生成です。カラーミーショップではこれまで iOS アプリで AI による商品宣伝文の生成を行ってきましたが、今回は Web アプリケーションでの実装を行いました。
アーキテクチャとしてはこのような感じです。
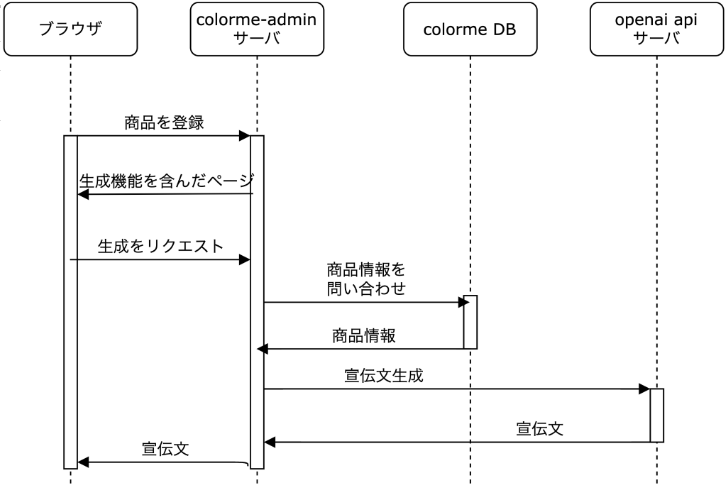
商品の説明文をもとに Open AI API に独自のプロンプトを含むリクエストを行うことによって SNS での拡散に最適な商品の宣伝文を生成します。
具体的な機能の詳細についてはこちらのプレスリリースをご覧ください。
【7/25 更新】商品の宣伝文を自動生成!「カラーミー AI アシスタント(β)」の提供を開始しました
難しかった点
- 文字コード(どのくん): カラーミーショップは 長年に渡り開発されているサービスで、アプリケーションの開発やデータのエンコードに EUC-JP と UTF-8 が併用されています。そのため機能追加をする際には、単に文字列として認識するのではなく、その文字コードを意識したコードを書く必要があります。OpenAI API への入力となる文字列を加工する処理で、文字コード起因のバグを作ってしまい、AI が予期せぬ結果を返す不具合に悩みました。不具合の原因自体は単純なのですが、当初は AI に渡すプロンプトが悪いのだろうと思い込んでしまったことが事態を難しくした原因です。問題解決に取り組む前に、問題の切り分けを正確に完了すべきだったと、身をもって学びました。
- 工数の見積もり(くろみー): カラーミーショップのような大規模なアプリではボタンを一つ追加するにしても影響範囲の調査も含めて個人開発と比較して工数を多めに見積もる必要があると感じました。私はフロントエンド側を担当しましたが、既存のコードと一貫性があるように実装することが難しかったです。
感想
- くろみー:カラーミーショップのような膨大なユーザーを抱えるアプリケーションで、実際に自分の書いたコードが動いているという事実に感動するとともにやりがいを感じました。LLM を利用したチャット型のサービスは今後の EC サービスにおいて必須になると思うので、今後この機能がどのように進化していくのか楽しみです。
- どのくん:サポートしていただいたメンターをはじめ、事業部の皆さんの力を借りて、サービスに初めて貢献しました。 仕事の進め方や質問するとなんでも答えてくれるさまを目の当たりにして先輩はすごいんだと改めて実感しています。 仕事をする上で目指す像がより具体的になりました。 EC 事業部の皆さん、ありがとうございました!
n01e0 @minne 事業部
minne 事業部で開発を行った@n01e0です。
取り組んだ内容
どのような箇所で OpenAI API を活用できるか、どこでどう使うべきか。という段階から考え、実装まで行いました。
また、検証時には形態素解析などの自然言語処理を用いてトークンの消費を抑える方法についても考察しました。
今回は作品についたレビューからアドバイスを作成し、作家に送信するような機能を開発しました。
難しかった点
まずは環境構築が大変でした。
minneはマイクロサービスで、複数のリポジトリに依存しています。セットアップ用のスクリプトがあるとはいえ、ローカルで環境が立ち上がるまでにかなりの時間を要します。
また、GraphQLなどの今までほとんど触れてこなかった技術が使われている点も難しかったです。とはいえそこは楽しく学ぶことができました。
感想
リリースに至らなかった機能もいくつかありますが、要件定義から実装までの流れを実感できて楽しかったです。
おわりに
この記事では 2023 年度のペパボ新卒エンジニア研修の様子を紹介しました。
研修を終えた私たち 13 期はサイクル OJT という形で社内の部署を周り仕事に取り組んでいます。 研修での学びが生きていると感じる毎日です。
研修に携わってくれた皆さん、ここまで読んでくれた皆さん、ありがとうございました!!


