
技術部データ基盤チームの @zaimy です。今回は、Google Cloud のベクトル近似近傍探索サービスである Vertex AI Matching Engine と、自然言語と画像のマルチモーダルモデルである CLIP による特徴量変換を使った、EC サービス「SUZURI」の類似画像推薦機能をご紹介します。
- できるようになったこと
- 構成
- Batch での画像のダウンロードと特徴量変換
- Matching Engine の index への新規登録と更新
- Matching Engine のレイテンシ
- コスト
- まとめと今後について
できるようになったこと
SUZURI を訪れた方が閲覧中のアイテムに類似するアイテムを画像をもとに推薦できるようになりました。以下の例では、「UFO」や「植物」という類似性を持つアイテムを推薦できていることがわかります。
今回は、構成の検討や試行錯誤を含めて、開発開始から 2 週間で推薦機能のリリースを行うことができました。
| 閲覧アイテム | 推薦アイテムの例 |
|---|---|
 キャトルハム / みぞぐちともや ( tomoya_mizo )のスタンダードTシャツ - https://suzuri.jp/tomoya_mizo/2721053/t-shirt/s/white キャトルハム / みぞぐちともや ( tomoya_mizo )のスタンダードTシャツ - https://suzuri.jp/tomoya_mizo/2721053/t-shirt/s/white |
 仙台弁こけし(んでまず) / 仙台弁こけし ( kokesu )のビッグシルエットTシャツ - https://suzuri.jp/kokesu/3150177/big-t-shirt/l/white 仙台弁こけし(んでまず) / 仙台弁こけし ( kokesu )のビッグシルエットTシャツ - https://suzuri.jp/kokesu/3150177/big-t-shirt/l/white |
 Flower ロンT / kamitamoのロングスリーブTシャツ - https://suzuri.jp/kamitamo/8453720/long-sleeve-t-shirt/s/white Flower ロンT / kamitamoのロングスリーブTシャツ - https://suzuri.jp/kamitamo/8453720/long-sleeve-t-shirt/s/white |
 りんごの花 / shirokumasaanのスタンダードTシャツ - https://suzuri.jp/shirokumasaan/645888/t-shirt/s/white りんごの花 / shirokumasaanのスタンダードTシャツ - https://suzuri.jp/shirokumasaan/645888/t-shirt/s/white |
構成
推薦候補の index はバッチ処理で作成/更新しており、構成は以下の通りです。
Google Cloud の Batch を使って、SUZURI から画像をダウンロードした上で、同じく Batch を使って GPU をマウントしたコンテナで CLIP モデルを使って画像を特徴量(ベクトル)へ変換し、結果を Matching Engine の index に登録しています。現在は SUZURI の一部カテゴリの商品のみ index に登録しており、特徴量数は数百万のオーダーです。
SUZURI は Matching Engine の endpoint, index, データポイント(アイテムに紐づく画像)の id を指定してリクエストを行い、リクエストしたデータポイントの id に対応するベクトルと近似近傍であったベクトルに対応するデータポイントの id 群を Matching Engine から受け取ります。
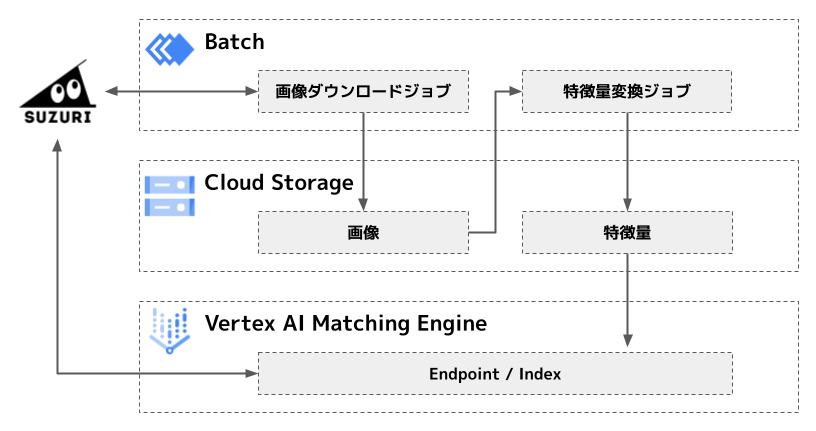
Batch での画像のダウンロードと特徴量変換
画像のダウンロードと特徴量変換の処理はそれぞれコンテナイメージに実装しており、Batch のコンテナジョブとして実行しています。特徴量変換に用いるモデルは、商用利用可能なモデルとして公開されている、事前学習済の CLIP モデル rinna/japanese-clip-vit-b-16 を利用しています。
Batch を選択した理由
ペパボのデータ基盤ではワークフローエンジンとして Cloud Composer 2 を利用しており、Cloud Composer が動作している GKE クラスタで任意のコンテナを実行する KubernetesPodOperator の利用実績があるため、当初は KubernetesPodOperator を使って GKE での実行を試みました。しかし、Cloud Composer 2 が動作している GKE Autopilot では GPU を利用するワークロードをサポートしていないことと、使用するリソースが多い場合に Cloud Composer の worker pod の再配置を招いて動作が不安定になることから、GPU を利用できてリソースが独立している Batch を選択しました。
また Batch では、Cloud Storage のバケットをストレージボリュームとしてコンテナにマウントできるため、ダウンロードした画像や生成した特徴量を改めてアップロードするような処理を書かなくても、生成物をローカルストレージに保存する実装のままバケットに保存できます。
Batch で複数のタスクに処理を振り分ける
Batch では各ジョブで行う処理を複数のタスク(VM とその上のコンテナ)に振り分けることができます。ジョブの設定としてタスク数と並列数を指定すると、実行されたジョブ中で環境変数として BATCH_TASK_COUNT (総タスク数)と BATCH_TASK_INDEX (実行中のタスクのインデックス)を利用できます。これらを用いると、全体の処理対象のリストを元にタスクごとの処理対象をコンテナ内で決定でき、ワークフローエンジン側で振り分けを行う必要がないため、実装を簡素にできます。
Batch で GPU とストレージボリュームのマウントを併用する際の注意点
前述の通り Batch では GPU を利用できますが、GCS バケットなどストレージボリュームのマウントと併用する場合は(少なくとも2023年5月23日時点では)Batch の job config に注意が必要です。
GPU を利用する場合、taskGroups > taskSpec > runnables > container > volumes で GPU マウントの設定を行います。一方、GCS バケットをストレージボリュームとしてマウントする場合、taskGroups > taskSpec > volumes で設定を行いますが、このとき VM からコンテナへのマウント(taskSpec > runnables > container > volumes 相当の設定)は自動的に行われています。
GPU と GCS バケットのマウントを併用する場合は、以下のように taskGroups > taskSpec > runnables > container > volumes にストレージボリュームの設定を明示的に書かないと、GPU の設定により上書きされてストレージボリュームがマウントされません。
{
"taskGroups": [{
"taskSpec": {
"runnables": [{
"container": {
...
"volumes": [
"/var/lib/nvidia/lib64:/usr/local/nvidia/lib64",
"/var/lib/nvidia/bin:/usr/local/nvidia/bin",
"/some/path:/some/path:rw", # この行の追加が必要
],
},
...
}],
"volumes": [{
"gcs": {"remotePath": "gs://some-bucket/"},
"mountPath": "/some/path",
}],
},
...
}],
"allocationPolicy": {
"instances": [{
"installGpuDrivers": True,
"policy": {
"machineType": "n1-standard-2",
"accelerators": [{"type": "nvidia-tesla-t4", "count": 1}],
},
}],
...
},
...
}
Matching Engine の index への新規登録と更新
Cloud Storage のバケットに特徴量を用意したら、以下のようなメタデータを用意して gcloud ai indexes create コマンドを実行するか REST でリクエストすることで index に登録できます。
特徴量のオブジェクトが 5,000 個を超える場合は、Cloud Storage で 複合オブジェクト を作成してオブジェクトの数を減らすことができます。
{
"contentsDeltaUri": "gs://your_bucket/embeddings",
"config": {
"dimensions": 512,
"approximateNeighborsCount": 150,
"distanceMeasureType": "DOT_PRODUCT_DISTANCE",
"featureNormType": "UNIT_L2_NORM",
"algorithm_config": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"leafNodesToSearchPercent": 10
}
}
}
}
また、gcloud ai indexes update コマンドか REST でリクエストすることで index を更新できます。注意点として、ドキュメント で指定を促されている isCompleteOverwrite は、個別の特徴量の id が衝突した際の overwrite ではなく index に対する overwrite なので、contentsDeltaUri に指定した特徴量を差分追加する際は false に、index を置き換える際は true に設定します。
なお、ペパボのデータ基盤ではほとんどのリソースを Terraform で管理していますが、Matching Engine の index も Terraform の google provider で管理できます。
Matching Engine のレイテンシ
稼働中のエンドポイントにおいて、クエリに対するレイテンシは 50 パーセンタイルで 2.0~2.5ms、95 パーセンタイルで 7.2~7.6ms となっており、十分に高速と言えそうです。
なお、ペパボで提供しているウェブサービスの実装には Ruby が多く使われていますが、2023年6月9日現在 Google Cloud の Ruby クライアントは Matching Engine のエンドポイントにまだ対応していません。ペパボでは、データ基盤に接続するために社内提供している Ruby クライアントに Matching Engine にリクエストする実装を追加しています。
コスト
数百万件の画像のダウンロードと特徴量変換のための Batch のコストは数千円程度、Matching Engine のエンドポイントのサービングのコストはインスタンスサイズにより約 10 万円/月〜という費用感です。高性能かつ簡単に使えるベクトル近似近傍探索サービスとして、これらの費用に対して十分にペイするプロダクトを作っていける可能性を感じています。
(2023年6月15日追記) Matching Engine のエンドポイントのサービングのコストについて、2023年3月以降はより安価なマシンタイプである E2 シリーズを利用することで約1万円/月〜で導入できるようになっています。ペパボでも index のシャーディングとマシンタイプの見直しを行い、費用を当初の3分の2程度にすることができました。また、レイテンシが見直し前と変わらない水準であることも確認できています。
まとめと今後について
Vertex AI Matching Engine と CLIP を使った EC サービスの類似画像推薦機能についてご紹介しました。
今回、もともとペパボで構築・運用しているデータ基盤の仕組みや、Google Cloud のサービスによって開発スピードを上げられたことに加えて、データ基盤チームだけでなくペパボ研究所の @monochromegane @watasan や、SUZURI 事業部の @__hamadaVR @giraffate @tsubasa のパワーで、開発開始から 2 週間で推薦機能のリリースを行うことができました。
現在はバッチによる index の更新を行っていますが、今後は Feature Store との組み合わせや、特徴量のリアルタイムのストリーミング取り込み(Streaming Ingestion)などによる改善を重ねていく予定です。また、SUZURI 以外のさまざまなサービスで推薦などの機能提供に活用していきたいと考えています。

