こんにちは、先日SREを引退しました、pyama です。 今日は、自分自身がペパボのデータ基盤チームに参入して、2週間ほど経ったので、やったことと、どういう技術を利用しているのか紹介します。なお、所属は技術基盤チームのままで、データエンジニアリングに興味が出てきたので勝手にやっている、そういう立ち位置です。
OpenStackのDBのCDC実装
ペパボではNyahと呼ばれるOpenStackのプライベートクラウドを運用しています。ペパボで利用しているOpenStackのバージョンではポート削除時に情報が物理削除であるがゆえに、IPが再利用されたときにある時点のIPとインスタンスの紐付けが取得できないという課題がありました。それを解決するために Debezium と Apache Kafka を利用して、Change Data Capture(CDC) アーキテクチャに変更しました。構成図は下記のとおりです。
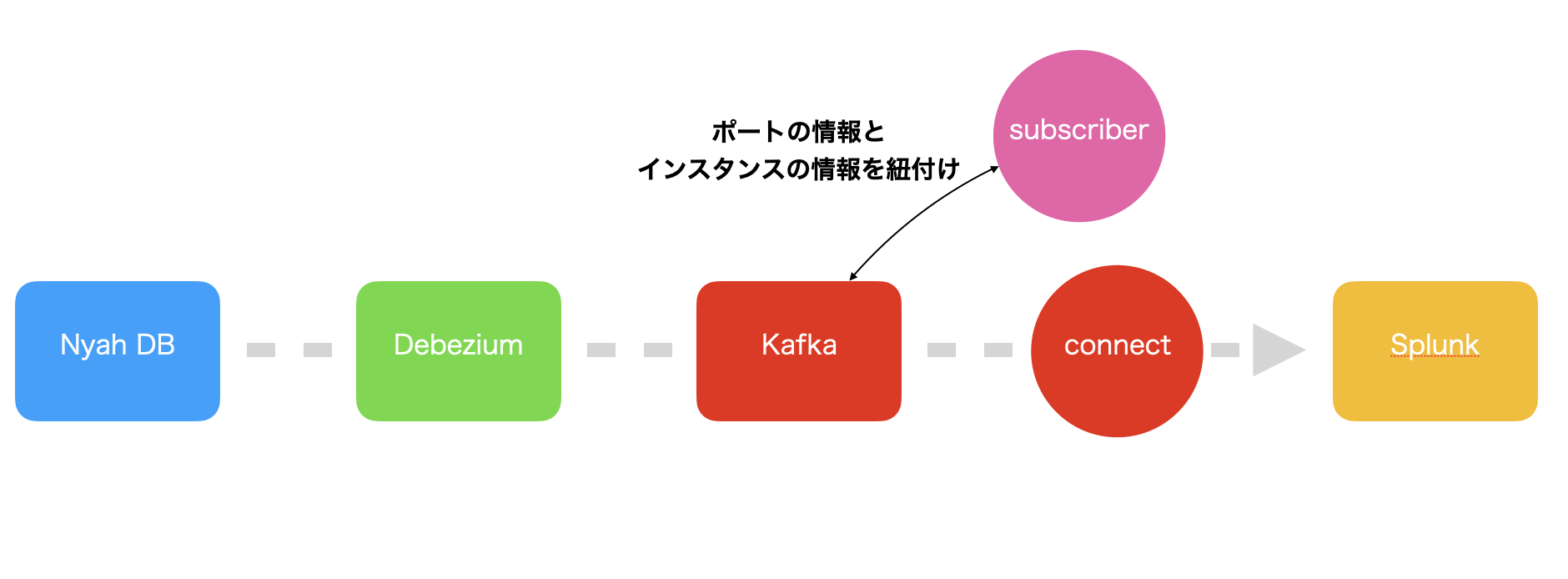
まず、NyahのDBとDebeziumを接続し、DebeziumはDBから取得したOpenStackのポートテーブルの変更情報をApache Kafkaのトピックに出力します。Apache Kafkaに取り込まれたポートの情報を、Rubyで実装されたデーモンがトピックから読み出し、ポートの情報にインスタンスの情報を付加して、別のトピックに書き出します。
次に、ポート+インスタンスの情報が格納されているトピックをKafka Connectを利用して読み出し、Splunk に出力しています。
このようにすることで、物理削除された情報もSplunkに全て保全されるので、ある時点のIPを利用していたインスタンスを特定可能になりました。
ユーザー行動ログの収集経路の変更
ペパボにはBigfootと呼ばれる、ユーザーの行動ログなどを集約して、利活用するデータ基盤があります。詳細は以前の記事 をご確認ください。以前はBigfootにログなどを送信するのはembulkやtd-agentを利用して、BigQueryに直接送信していました。それをGoogle Cloudの Pub/Sub へ送信するように経路変更をしました。
経路変更の理由は、これまでInput、DataStoreの関係が1:1だったのに対して、一度Pub/Subにデータを入れることで、1:Nの関係にすることでより拡張性のあるデータ基盤にすることができるからです。
今回の作業ではPub/SubからBigQueryのデータ連携はDataFlowのテンプレート を利用しました。テンプレートを利用することで、Kafka Connectと同じような間隔で、トピックと出力先のテーブルを指定するだけで、BigQueryのテーブルにデータを挿入できます。
作業中、1つだけはまってしまったのが、Pub/Subから取り出したJSONのカラムと、BigQueryのテーブルのカラムが一致している必要があるという仕様です。行動ログのJSONには含まれているが、BigQueryのテーブルには存在しないカラムがあったため、不要なカラムを削除する必要がありました。このようなエラーについては、テンプレートのパラメーターである outputDeadletterTable で指定したテーブルに詳細なエラーが出力されるので、そのテーブルの情報を元にトラブルシューティングする必要があります。
Apache Airflowのタスクの定義漏れをCIで検知する
Bigfootではワークフロー管理にCloud Composerを利用しています。
それぞれのワークフロー内のDAGの前後の依存関係を管理するのに、上流のDAGが特定のタスクを登録し、下流のDAGがそのタスクを待つことで、依存管理を行っています。詳細については@zaimyのブログを見てください。
この方式では、上流のDAGに必ず特定のタスクが登録されていることを何かしらで担保しないといけないのですが、これまではそれをレビュワーがレビュー時に確認するよう、PRテンプレートにチェックボックスを入れていました。しかし、我々人類はときに抜け、漏れを発生させてしまいます。
そこで、PythonのコードをASTに変換して、特定のタスクが登録されていることを確認するようにしました。
まず下記のコードで、指定ファイルに存在する、TasksForWaitingUpstreamDags というクラスのインスタンス時の引数を取得します。 引数を取得するのは、先に述べた上流のDAGが登録すべきタスクの名前を、TasksForWaitingUpstreamDags のインスタンス化の引数に持つためです。
def find_constructor_call(node, class_name):
if isinstance(node, ast.Call) and isinstance(node.func, ast.Name):
if node.func.id == class_name:
return node
for child_node in ast.iter_child_nodes(node):
result = find_constructor_call(child_node, class_name)
if result is not None:
return result
return None
def node_for_waiting_upstream_dags(filename):
with open(filename, "r") as file:
file_contents = file.read()
parsed_ast = ast.parse(file_contents)
constructor_call_node = find_constructor_call(
parsed_ast, "TasksForWaitingUpstreamDags"
)
return constructor_call_node
次に、取得したタスクの名前を用いて、タスクが登録されているかを下記の関数で確認します。
def is_registered_with_task_id(filename, task_id):
with open(filename, "r") as file:
file_contents = file.read()
parsed_ast = ast.parse(file_contents)
constructor_call_node = find_constructor_call(parsed_ast, "DummyOperator")
if constructor_call_node is not None:
for arg in constructor_call_node.keywords:
if arg.arg == "task_id":
if arg.value.value == task_id:
return True
return False
このようにASTを利用して静的解析をすることで、人が見るしかないと思いがちなことでも、スクリプトでチェックできます。
これから
ここまで書いたこと以外にも、GrafanaとGCPを連携したダッシュボードの作成など着手しています。今後についてはペパボのデータ基盤の仕事をしながら、可用性の管理についてもアプローチしていきたいと思っています。
昨今GPTの躍進により、より熱いこの領域において、ペパボで一緒に活躍してくれる仲間を熱く募集しています。