こんにちは。 技術部プラットフォームグループの rsym1290 です。
技術部プラットフォームグループではペパボが提供するサービスのインフラ部分を横断的に支えており、SREにも力を入れています。 本稿では私が取り組んだ「プライベートなオブジェクトストレージBayt(ベイト)からS3へ移設するプロジェクト」と、それを遂行した際に直面した2つの課題を含めて紹介いたします。 本記事を通じて、技術部プラットフォームグループの取り組みに興味を持っていただけると幸いです。
Bayt(ベイト)について
Baytとは、S3と互換性のあるAPIを提供しているプライベートなオブジェクトストレージです。 弊社ではカラーミーショップやGoope(グーぺ)などのさまざまなサービスを提供しており、商品画像やホームページ用の各種コンテンツを保管するためのストレージとしてBaytを利用しています。 また、Baytは独自のエンドポイントを公開しており、このエンドポイントを指定することで各サービスのアプリケーションからS3関連のSDKを用いて、S3と同じ要領でBaytを利用できます。
Baytについて詳細を知りたい方は過去に投稿した記事をご参照ください。
- S3のAPIと互換性を持ったオブジェクトストレージの運用についてお話します - Pepabo Tech Portal
- 4ペタバイトの巨大ストレージを支える運用について紹介します - Pepabo Tech Portal
ペパボではカラーミーショップやGoopeなどのサービスでBaytを利用していましたが、後述する経緯でBayt上のオブジェクトを全てS3へ移設する方針になりました。 2022/8/4にGoope分のオブジェクト移設が完了したので、本稿ではGoope分のオブジェクトをどのようにして移設したのか取り上げます。
なぜS3への移設に踏み切ったのか
弊社ではBaytとS3を使い分けています。 BaytはS3と比較すると、コスト面で優位性がある一方で、機能面・耐久性で及ばない部分があるため、サービス事業部ごとの判断で採用するオブジェクトストレージを決めていました。 具体的な機能面の差として、BaytがサポートしているAPIが一部だけであることや、オブジェクトのバージョニング・ライフサイクルを設定できないなどの制約が挙げられます。 また、S3はLambdaをはじめとしたAWSのさまざまなサービスとの連携がより柔軟で、この点もS3の優位性として挙げられます。
これまでは各サービスともコスト面を重視してBaytを採用していました。 しかしサービスの成長に伴い、より質の高いプロダクトを提供するために機能面・耐久性を重視するようになったため、S3への移設に踏み切りました。
本プロジェクトの遂行にあたって
本プロジェクトは、GMOグローバルサイン・ホールディングス株式会社のサービスCloudCREW に支援していただきました。 CloudCREWとは、クラウドに関するさまざまな課題を解決することを目的とした運用支援のサービスです。 本プロジェクトでは、S3に関連する課題の解決・検証で協力いただきました。 本稿では、CloudCREWの助力で解決した課題を含めて取り上げます。
移設にあたって直面した課題
S3へオブジェクトを一斉に移設する場合、まず思いつくのがAWS CLIのsyncコマンドの利用です。 syncコマンドとは、バケットとローカルディレクトリの内容、または2つのバケット同士の内容を同期するコマンドです。
例えば以下のようなコマンドを実行すると、ローカルディレクトリ./path/to/local/contents配下にある全てのファイルをS3のs3://<bucket>/contents配下へ同期できます。
aws s3 sync ./path/to/local/contents s3://<bucket>/contents
通常のコピーだと指定したディレクトリ配下を全てコピーしますが、syncコマンドの場合は同期元・同期先の差分に基づいて、新規作成・更新されたファイルに絞り込んで同期先へコピーできます。
本プロジェクトでもこれを利用しての移設を想定していました。 しかし、以下のような課題に直面したためただ同期すればよいというわけには行きませんでした。
課題1. エンドポイントが異なるためにBaytからS3へ直接同期できない
早速ですが、本課題はCloudCREWの助力を受けて解決した課題です。
S3ではs3.<リージョン>.amazonaws.comという形式のエンドポイントに対して各APIを実行することで、S3へのオブジェクトの配置や取得ができます。
AWS CLIでコマンドを実行する時は、標準でこの形式のエンドポイントに対してAPIを実行しています。
一方でBaytは独自のエンドポイントを持っているため、Baytに対してAPIを実行する時はコマンドのオプションでBaytのエンドポイントを明示する必要があります。
しかし、ここで一つの問題が発生しました。 AWS CLIで指定できるエンドポイントは一つだけで、「ローカルから指定したエンドポイント」「指定したエンドポイントからローカル」「同一エンドポイントの異なるバケット同士」での同期は可能ですが、同期元のエンドポイントと同期先のエンドポイントを個別に指定しての同期はできませんでした。 そのためBaytからS3へ直接同期することはできませんでした。
解決策
結論として以下のような方式を取りました。
- EBSボリュームをマウントしたEC2インスタンスを複数台並べて、Bayt→ EC2(EBS)→ S3の2段階でsyncコマンドを実行する
- EC2インスタンスを複数台並べてインスタンスごとに同期を担当するフォルダを固定して、一斉にsyncコマンドを実行する
先述のとおり「ローカルから指定したエンドポイント」「指定したエンドポイントからローカル」という同期は可能なため、EC2インスタンスを用意して、EC2インスタンス上でsyncコマンドを実行することにしました。 また、Bayt上にある移設対象となるオブジェクトは約2.7TBあり、それをEC2インスタンス上で保持するための領域を確保するため、EBSボリュームをマウントすることにしました。
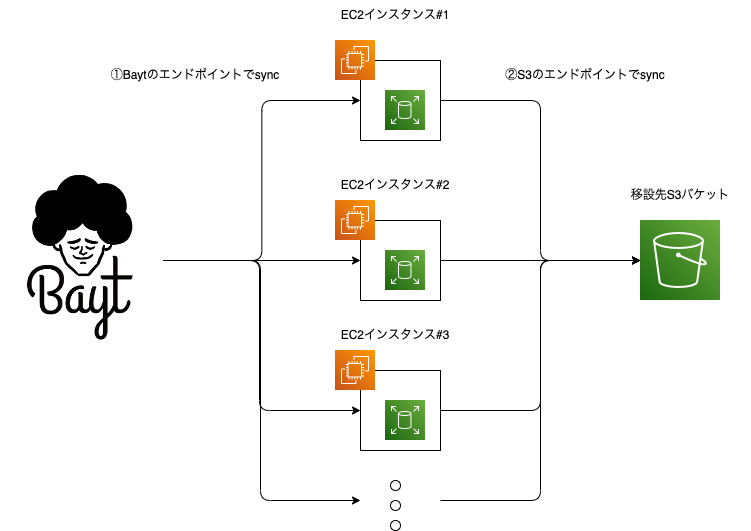
この方式でBaytからS3へ同期することはできますが、syncコマンドを2段階で実行するためその分だけ全てのオブジェクトを同期し終えるまでの時間も単純計算で2倍程度まで長くなってしまいます。 また、syncコマンドを実行している間はBaytを利用するサービスをメンテナンス状態にして、オブジェクトの更新がかかるリクエストを停止する必要があります。 これは、BaytからEC2インスタンスへ同期し終えた後にEC2インスタンスからS3へ同期している間に、Baytにオブジェクトがアップロードや削除が実行されると、一部のオブジェクトでBaytもしくはS3にしか存在しないという不整合が起きてBaytを利用するサービスに影響にでてしまうからです。
少しでもサービスの停止時間を短縮するために、大部分のオブジェクトの同期は前日までに終わらせておき、メンテナンス中は前日からの差分のみを同期するようにしました。
S3にオブジェクトが一切配置されていない状態で2段階で同期した時は、全体で30時間程度かかりました。
さらに、数日おいてBayt上のオブジェクトに更新がかかった状態で、再度同期にかかる時間を計測しました。
計測結果は下表の通りです。
Goopeでは約1800万件のオブジェクトをBaytに保管しており、全てのキーは ユーザーID/path/to/コンテンツと言うように、1つ目のフォルダにユーザーIDが含まれています。
1インスタンスあたり10,000件分のユーザーIDを対象に一斉にsyncコマンドを実行した結果、BaytからEC2への同期、EC2からS3への同期にそれぞれ2時間程度かかり、合計4時間程度かかる結果となりました。
| EC2インスタンス | ユーザーID数 | sync(Bayt → EC2) | sync(EC2 → S3) |
|---|---|---|---|
| 1号機 | 10,000 | 95m39.251s | 84m48.290s |
| 2号機 | 10,000 | 99m58.234s | 87m42.846s |
| 3号機 | 10,000 | 99m30.141s | 88m26.307s |
| 4号機 | 10,000 | 85m21.555s | 89m09.917s |
| 5号機 | 10,000 | 84m56.980s | 86m58.762s |
| 6号機 | 10,000 | 123m41.946s | 117m41.140s |
| 7号機 | 10,000 | 110m44.137s | 105m50.795s |
| 8号機 | 2,166 | 31m26.193s | 26m52.068s |
EBSボリュームを利用する方式以外にも、goofysを用いてEC2インスタンスに移設先バケットをマウントしてsyncを実行する方式も検討しておりました。 しかし計測結果よりEBSボリュームを採用した方がパフォーマンス面で優れていることが分かったため、EBSボリュームを用いる方式を採用しました。
課題2. URLエンコードの影響で同期対象のファイルを取得できない
Baytを同期元としてEC2インスタンスへsyncを実行する時に別の問題が発生しました。 syncの実行中に、いくつかのオブジェクトで以下のようなエラーメッセージが表示されました。
download failed: s3://goope/99999/%E3%82%B5%E3%83%B3%E3%83%97%E3%83%AB.pdf to ebs/99999/%E3%82%B5%E3%83%B3%E3%83%97%E3%83%AB.pdf An error occurred (NoSuchKey) when calling the GetObject operation: The specified key does not exist.
このエラーは、syncコマンドの内部でGetObject APIを利用してオブジェクトを取得する際に、該当のオブジェクトが存在しない場合に起きるものです。 Baytではデータベースでオブジェクトのキーなどの情報を保持しているのですが、そこを確認する限り該当オブジェクトは確かに存在していました。 にもかかわらずこのようなエラーが発生してsyncコマンドの実行に失敗しました。
なぜこのようなことが起きたのかと言うと、「BaytはS3では推奨されていないURLエンコードされたオブジェクトをサポートしている」ことが関係しています。
Baytが存在していなかった当時、ペパボのサービスの中には独自にストレージサーバを保有しており、ファイル名にはEUC-JPなどの文字コードが利用されていました。
これらのオブジェクトをBaytを利用できるようにするためにURLエンコードをサポートしたという経緯がありました。
そのため、S3ではオブジェクトキー名での利用が非推奨とされている%を含んだキーを持つオブジェクトを利用できる前提で運用していました。
しかし、URLエンコードをサポートしている影響で、BaytからEC2インスタンスへ同期するためのsyncコマンドの実行に失敗してしまいました。
AWS CLIのsyncコマンドでは以下の流れで同期する対象となるオブジェクトを同期元からダウンロードしています。
- オブジェクトの一覧を取得するAPI
ListObjectsで同期の対象となるオブジェクトの一覧を取得 - 一覧より同期の対象となるオブジェクトをAPI
GetObjectで同期先にダウンロードする
1.のときにURLエンコードされたままのパスが返されてしまい、URLエンコードされたままのパスに対して GetObject を発行してもオブジェクトが取得できないということが分かりました。
解決策
結論として、Goopeが利用するバケットに対するListObjectsに限定して、URLデコードしたものを返すようにBaytのAPIを改修しました。
BaytのAPIはRuby on Railsで実装されており、データベースに保存されているキーの情報をもとに各リクエストに対するレスポンスボディを作成しています。 データベースにはURLエンコードされたままの文字列でキーが保存されているので、データベースからキーを取り出した後にURLデコードを実行してレスポンスボディを作成すれば先述のようなエラーは回避できます。
ここで注意点があります。 先述の通りBaytを利用しているサービスの中にはURLエンコードを必要としているサービスもあります。 そのため、APIを闇雲に改修してURLデコードを有効にしてしまうとBaytを利用している全てのサービスに影響が出てしまいます。 幸いGoopeはListObjectsを利用していないサービスだったため、「Goopeバケットに対するListObjectsに限定してURLデコードする」という実装によって本問題を解決できました。
以下は先述したエラーメッセージを解消したことで得られたListObjectsのレスポンスです。
{
"Contents": [
...
{
"Key": "99999/サンプル.pdf",
"LastModified": "2019-11-22T02:00:07Z",
"ETag": "\"e3e224dd828a91538c0b95b0d7ca5a25\"",
"Size": 1276594,
"StorageClass": "STANDARD",
"Owner": {
"ID": "goope"
}
},
...
メンテナンス当日の対応
本番のメンテナンスは2022/8/4に実施し、無事にS3への移設が完了しました。
先述の通りBaytからS3へのオブジェクトの同期には4時間程度かかることが想定され、同期後にさらにアプリケーションの参照先を切り替えて不具合がないかを確認する必要があります。 この間はGoopeへのサービス影響が出ることになります。 一方でオブジェクトストレージを利用する全ての機能を制限してメンテナンスをすると、ユーザー体験・満足度の低下につながるため、可能な限りユーザー影響を最小限に抑えることも求められます。
Goopeではホームページを作成するための管理画面を提供しており、管理画面からホームページで利用したいコンテンツをアップロードしたり削除したりできます。 メンテナンス中にこれらの操作があると、BaytからS3へ同期している途中でBaytにのみオブジェクトが更新されて不整合が起きるリスクがあります。 一方で、作成されたホームページを閲覧する場合は、BaytもしくはS3からオブジェクトの取得ができれば閲覧に影響はないので、機能制限をせずともアプリケーションの参照先ストレージのエンドポイントを変更するだけで良いことになります。 そこで、メンテナンスはGoopeの管理画面からのコンテンツのアップロード・削除の機能だけを制限し、ホームページの閲覧は引き続き利用できる状態で実施することで、サービス影響を最小限にしました。
当初はS3への同期やアプリケーションの切り替えを含めて全体で6時間程度メンテナンスに要する想定でしたが、4時間以内にメンテナンスを完了させることができました。 要因として、メンテナンス前日の深夜にsyncコマンドを実行して差分を可能な限り減らしたことでオブジェクトの同期に4時間程度かかる想定だったのが3時間程度で完了できたことや、検証環境で十分な検証をしていたおかげでトラブルを起こさずにアプリケーションの参照先切り替えができたことが挙げられます。
まとめ
弊社のプライベートなオブジェクトストレージからS3へ移設するプロジェクトについて、GoopeのオブジェクトをS3へ移設したことについて紹介しました。 単にAWS CLIで同期するだけはなく、移設手段・パフォーマンスを評価したり、移設のために必要なBaytのアプリケーションを改修したり、Baytを利用しているサービスの関係者と協力して移設を実現したり、非常に内容の濃いプロジェクトだったと思います。
さて、Goope分の移設は完了しましたがこのプロジェクトは第二段が進行中です。 Baytを利用しているサービスは他にもあり、現在はカラーミーショップのオブジェクトをS3へ移設するための検証を進めています。 Goopeよりもサービスの規模が大きく、より大きなチャレンジと言えます。 第二段のプロジェクトを完遂して、ペパボのサービスの成長そしてユーザー体験の向上に結びつけたいと思います。
最後に
繰り返しになりますが、本プロジェクトはCloudCREWに支援していただいたことで完遂することができました。 心より御礼を申し上げます。



