こんにちは。技術部プラットフォームグループのしばっちといいます。
わたしは以前、権威DNSをBIND->PowerDNS(on EC2)+Auroraへ再構成した話と題しましてAWSで権威DNSを構築するという、一風変わったことをした話をご紹介しました。一年以上ぶりのテックブログになりますが、今回もAWSを用いておもしろいことをやってみたので紹介します。
ところでみなさん、AWS Lambdaは好きですか?Lambdaはサーバーの構成を考えずにプログラムを実行するサービスですが、私はこのサービスが好きです。サーバーのメンテナンスや構成を考えずに、自分の実行したいコードがサッと実行できるなんて!提供が開始されてから随分経ちます(2014年開始)が、いまだにおもしろいサービスだと思っていますし、アイディア次第で夢が広がるサービスですし、趣味でちくちく触ったりもします。
今回ご紹介したいのは、そんなLambdaを使った問題解決事例です。
この記事はLambdaを活用した自動化の事例を知りたい方や、CloudFrontでリクエスト数を取得してみたい方、Route53のレコードを自動更新させてみたい方、そして何よりAWSでおもしろいことをやってる事例を知りたい方に贈ります!
解決したかったこと
解決したかったことはSUZURIというサービスでの課題です。SUZURIでは画像変換サーバーというものを運用しており、2つのKubernetes環境─GoogleKubernetesEngine(GKE)と、プライベートクラウド環境のNyahKubernetesEngine(NKE)─にまたがって構成しています。アクセスが来たらまずCDNであるAmazon CloudFrontを通り、キャッシュヒットしなかったアクセスのみGKE/NKEに到達します。このとき、GKE/NKEへのアクセスの割り振りはAmazon Route53の重み付きラウンドロビンを使用しています。
図で示すと以下のようになります。

最大の特徴はGKE/NKEのマルチクラウド構成であることですが、この2つのクラウド環境はそれぞれ以下の特徴があります。
- GKE…ノードのオートスケールができるのでアクセス増加に柔軟に対応できる、コストはNKEより高い
- NKE…ノードのオートスケールができない、プライベートクラウドでコストはGKEより安い
そこで、コストと冗長性のバランスを取るため、普段のアクセス量はNKEでほぼまかない、突発的にアクセスが増えたときのみGKEの重みを増やすことをしています。
この重みを変更するオペレーションは手動で行っていました。セール前に事前にアクセス増を見越してGKEの重みを増やすのですが、DNSレコードの変更オペレーションは手慣れてない人がやるとわりと心理的に負荷がありますし(まちがえたら最悪の場合障害になってしまいますね)、突発的にアクセスが増えた場合、レイテンシが悪化してアラートになる→エスカレーションを受ける→手動で変更する…という流れはあまりやりたくないオペレーションです(特に深夜に一人で…というのは嫌ですね、幸いそのパターンは経験していないですが可能性はありますね)。
アクセスが増えたら「いい感じに」「自動で」DNSのレコードを更新してGKEにオフロードをしてくれる仕組みはできないものか…?それが解決したかったことになります。
どのように解決したか?
以下の仕組みを作りました。

6つアイコンが並んでいますが、すべてAWSのサービスです。今までGKE/NKEの話をしてきましたが、この仕組みの中にはありません。AWSのサービスを組み合わせた仕組みで解決しました。
- CloudFrontはキャッシュヒット率とリクエスト数をCloudWatchに送信します
- EventBridgeは5分に1回、Lambdaを起動します
- LambdaにはあらかじめCloudWatchのメトリクス取得権限とRoute53の更新権限を付与しておきます
- LambdaはCloudWatchからCloudFrontから受信したリクエスト数、キャッシュヒット率を取得し、そこからキャッシュミスの量(=GKEとNKEへ流れるリクエスト数)を算出します
- キャッシュミスの数がNKEで処理できる数を上回っている場合、Route53のレコードのweight値を更新します
ちょっと補足させてください。CloudFrontのキャッシュミスの量がリクエスト数になる というくだりはパッと聞いても本当なの?と思うかもしれません。あまり耳慣れない考え方に思います。今回の構成では、キャッシュミスしたリクエストはすべてGKE/NKEに流れるので、オリジンへ流れるリクエスト数として使えるのではないか?と考えました。そして実際に実際にGKE/NKEのDatadogで取得していたリクエスト数と比較検証して、ほぼ相似形であることも確認しました。
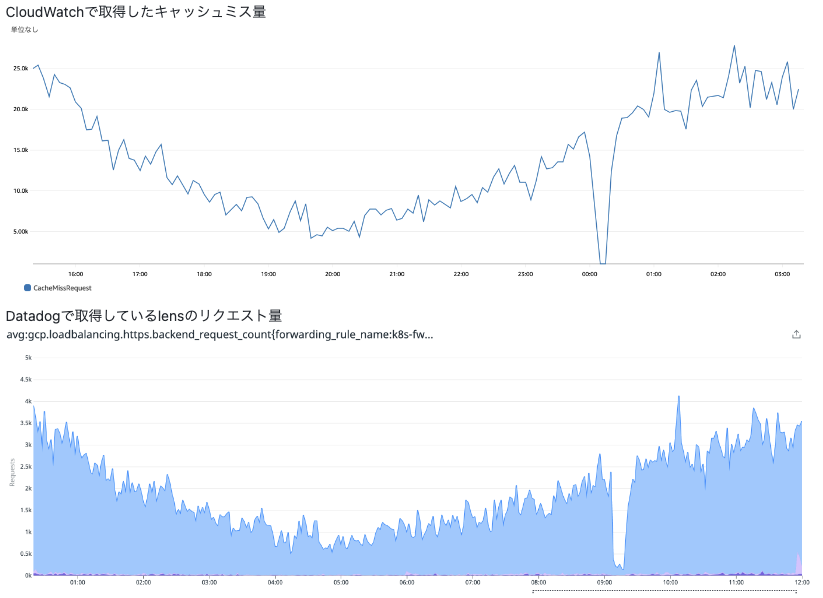
また、リクエスト数を取得したいのならわざわざCloudFrontのメトリクスをこねくりまわさなくても、もっと良い方法があるのでは?と思う方もいるかもしれせん。前述した通りGKE/NKEではDatadogでリクエスト数を取得しているので、その値を用いても確かに同じものは作れたと思います。ただ、複数の会社のツールが連携するよりはAWSのみで完結させたほうが稼働安定する予想ができたことと、構想段階ではAWS内で完結するほうが実現可能性が高そうに感じたので、AWS内で完結する仕組みにしました。
具体的に行ったこと
ここからは具体的に行ったことを簡単に書いていきます。
 IAM
IAM
AWSの権限管理を行っているIAMでは、Lambdaに付与する権限を設定します。具体的には以下です。
- cloudwatch: GetMetricData
- CloudFrontのメトリクスをCloudWatchで取得するため
- route53:ListResourceRecordSets
- route53:ChangeResourceRecordSets
- Route53のレコードに設定されているweight値を取得、更新するため
- logs:CreateLogStream
- logs:CreateLogGroup
- logs:PutLogEvents
- Lambdaの実行ログをCloudWatchlogsに保管するため
これらの権限のポリシーを作成し、ロールを作成して付与しておきます。
 CloudFront
CloudFront
CloudFrontは、初期設定ではメトリクスをCloudWatchへ送信する設定になっていないので、追加のメトリクスを有効にする設定にします。こうすることでリクエスト数やキャッシュヒット率がCloudWatchに送信されるようになります。
 CloudWatch
CloudWatch
CloudFrontから送られてきているリクエスト数(Requests)、キャッシュヒット率(CacheHitRate)、エラーレート(TotalErrorRate)を組み合わせて、キャッシュミスリクエスト数を算出する式を検証します。
必要と思われるメトリクスを選択し、以下の数式に組み合わせることでキャッシュミスのリクエスト数を算出できました。
キャッシュミスリクエスト数 = Requests * (100 - CacheHitRate - TotalErrorRate) / 100
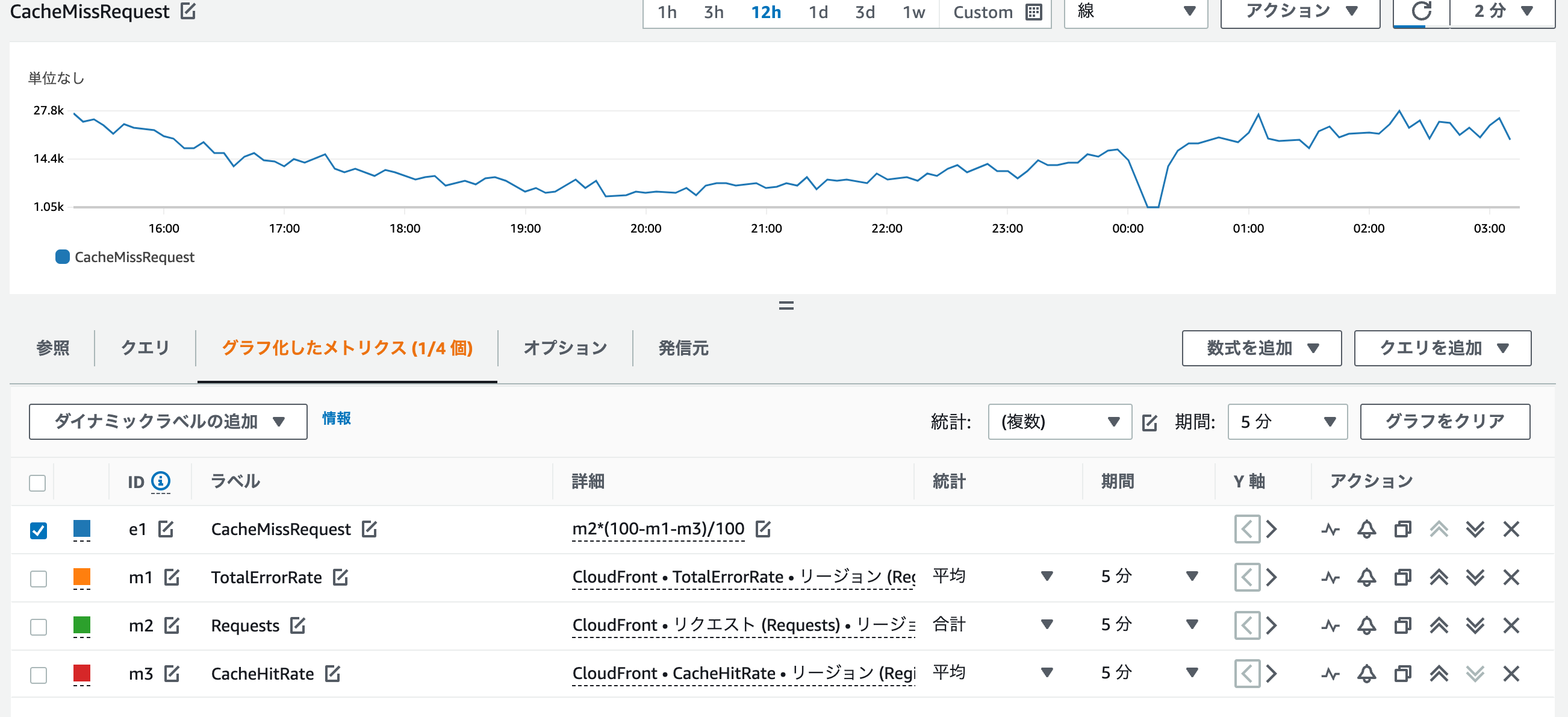
CacheHitRateとTotalErrorRateは平均値を使用し、Requestsは合計値を使用することで取得できました。合計値を使用しているため、単位は「期間」の設定によります。上の図では5分にしているため、5分間の合計になります。(そのため、1分当たりに直すには5で割る必要があります。)
 Lambda
Lambda
PythonでAWS用のSDK(boto3)を使って機能を実装していきます。落とし穴としてCloudWatchから値を取得する場合はリージョンをus-east-1にする必要があることです(ドキュメントに書いてあるのですが私はだいぶこれで時間を消費してしまいました…)。また、IAMで作成したロールをLambdaを作成する際に付与します。
実装した内容は以下の通りです。
- CloudWatchからキャッシュミスリクエスト数を取得します
- get_metric_dataを使います
- コードは長いので省略します
- CloudWatchで検証した、 3つのメトリクスを組み合わせた式を用いて算出します
- メトリクスを算出する際は過去10分間の平均値を取ることでレコード更新がバタつくことを防ぎます
- Route53から現状のレコードのWeightを取得します
- list_resource_record_setsを使います(下のソースコードでは
__init__()メソッドは省略しています) -
def get_record(self): client = boto3.client('route53') response = client.list_resource_record_sets( HostedZoneId = config.ZONEID, StartRecordName = self.name, StartRecordType = self.type, StartRecordIdentifier = self.identifer, MaxItems = self.maxitems ) self.weight = response["ResourceRecordSets"][0]['Weight'] ## weight値を取得する self.ttl = response["ResourceRecordSets"][0]['TTL'] self.resourcerecords = response["ResourceRecordSets"][0]["ResourceRecords"] - ここではweight値のほかに、都度TTLやAレコードの内容(ResourceRecordSets)を取得しておきます
- 書き換える際に利用することで、誰かがTTLやAレコードの内容を書き換えていても巻き戻りの事故が起こらないようにしておきます
- list_resource_record_setsを使います(下のソースコードでは
- キャッシュミスリクエスト数から、理想的なGKE/NKEのアクセス比率を算出します
- この算出のためには、NKEが処理できるリクエスト数を事前に算出しておく必要があります
- 私はNKEへのリクエスト数とそのときのPod数(Podはオートスケールがなされるよう設定されています)から算出しました
- weight値を変更する必要がある場合は、Route53のレコードを更新します
- change_resource_record_setsを使います
-
def set_weight(self,new_weight): self.weight = new_weight client = boto3.client('route53') response = client.change_resource_record_sets( HostedZoneId = config.ZONEID, ChangeBatch={ 'Comment': 'upsert weight', 'Changes': [ { 'Action': 'UPSERT', 'ResourceRecordSet': { 'Name': self.name + ".", 'Type': self.type, 'SetIdentifier': self.identifer, 'Weight': self.weight, 'TTL': self.ttl, 'ResourceRecords': self.resourcerecords } }, ] } )
- レコード更新した場合はSlackに通知します
 EventBridge
EventBridge
作成したLambda functionを5分に1回起動させます。
これで完成です!
実際に動かしてみて
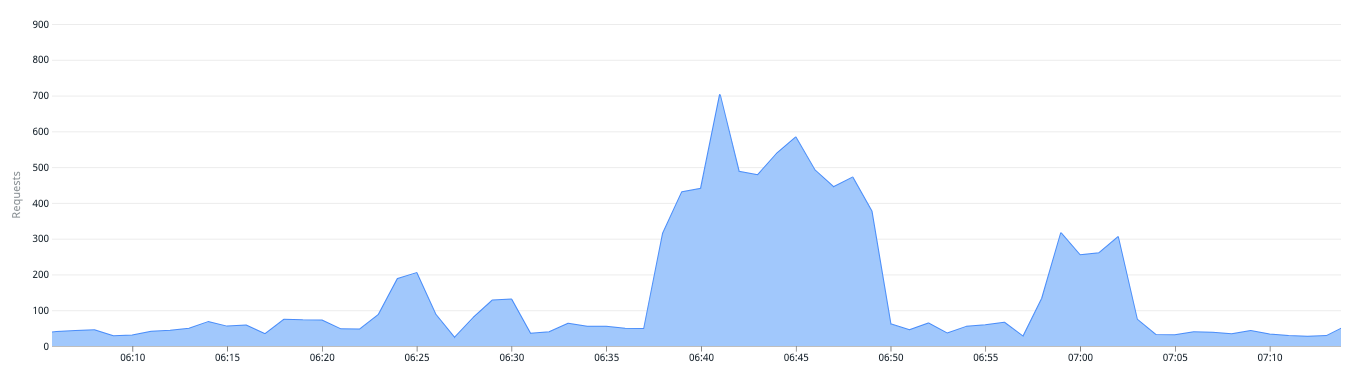
実際にオリジンへのアクセスが増えるタイミングでちゃんとRoute53を書き換えてくれました🙌
アクセス数が増えたタイミング(CloudWatch)で
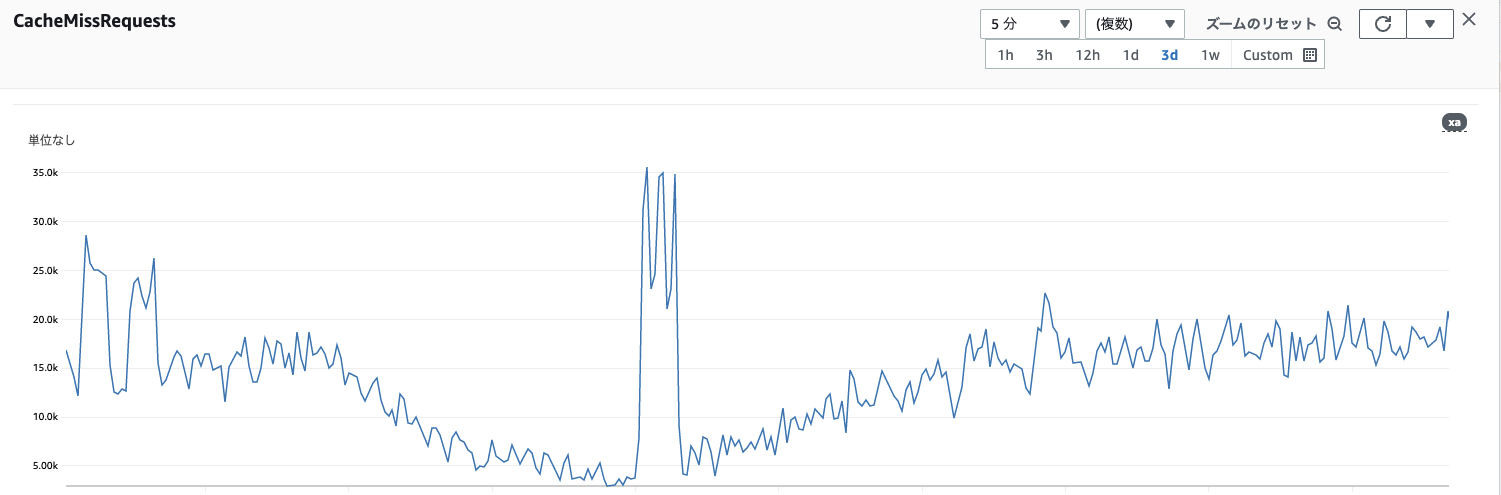
レコード変更したSlack通知がなされていました。
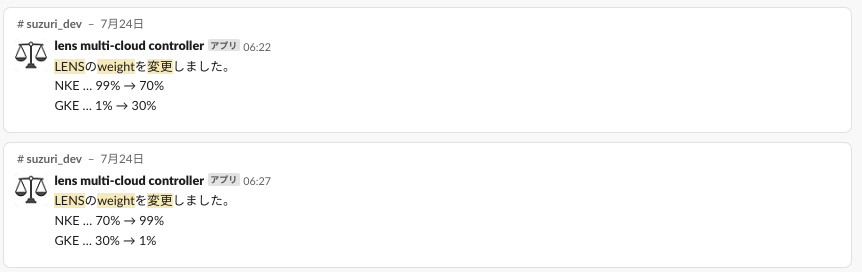
GKEのリクエストを見ると該当の時刻に増加していた(=weightが調整されていた)ことがわかります。
まとめ
この仕組み、実際にレコード書き換えの動作の発生は頻繁にはないのですが(ひと月に1回以下ほどです)、この自動化で得られたものはもう手動でオペレーションしなくていいという安心感や予想されるリクエスト増加の前にスケールアウトを忘れることができない、といった不安からの解放です。私はLambdaはとても安定して動作するサービスと評価していますが、それをCloudFrontやRoute53といった可用性の高いサービスと組み合わせることで安定して動作する仕組みを構築できました。ひらめいたことが形になると嬉しいですね。
今回はAWSに限定した話ですが、今後の改善で思いつくものとして、KubernetesのHPA(Horizontal Pod Autoscaler)を、現状はCPU使用率で判定しているところをこういったメトリクスベースにしても面白そうですね。
CloudFrontやRoute53は導入している企業やサービスは多いと思いますので、何かしら参考になれば嬉しいです!



