データ基盤チームの方から来ました、 @udzura です。
私の所属するGMOペパボのデータ基盤チームは、「Bigfoot」と名付けられたデータ基盤の開発・運用を行いつつ、全社のデータ駆動化を推進していく組織です。
これは2021年の資料になりますが、 @tosh2230 によるデータ基盤チームの立ち上げについての資料もありますので併せてご覧ください。このテックブログでもいくつかデータ基盤に関する記事があります。
さて、このチームは、2021年から発足した新しい組織です。なおかつ、立ち上がりの始めから全てをオンラインで行ってきた、リモートネイティブなチームでもあります。
この記事では、そんなデータ基盤チームをどのように整えていったか振り返ろうと思います。その過程で、実践したチーム開発のプラクティスを紹介します。
〜2020年のデータチームについて
実はBigfootという名前の基盤自体は、2020年以前から存在していました。
過去にどのように活用されていたかは、例えば2016年の研究開発チーム @miyakey による発表資料があります。
さて、2020年からは基盤をGCPに移設し、そのタイミングで @udzura がジョインすることになりました。当初からBigfootに関わっていた @zaimy と2人で、より全社的に活用できるように、例えばInfrastructure as Codeの整備やIAMのPull Requestベースでの管理などの基本的な部分の見直し・開発を行いました。
2021年からの取り組み
ここから、今年行った取り組みを概ね実施順で紹介します。
新規ジョインメンバーのためのオンボーディングの整備
2020年末に @tosh2230 が、2021年に @kozee がジョインしました。これで、改めて4人のチームとして始動することとなりました。
お2人はフルリモートでのオンボーディングとなるので、滞りなくかつ効率的に実施できるよう原則テキストベースで非同期に進めていくことにしました。
そのための方法として、まずはNotionに「〜さん向けオンボーディング」のページを作成し、NotionのTODOリスト記法を用いて全てをリストアップ、上から一つずつ自分でチェックを入れていく方式を取りました。
ペパボはAWS、GCPアカウントをはじめセットアップが必要な外部サービスであったり、また社内用の自前のシステムも存在するため、それらの権限を逐一必要になるたびに申請していては効率が良くないです。そのため最初から一通りセットアップを行うようにしました。また、開発時の言語(Ruby、Python)やDockerのようなツール類などインストールが必要なツールもまとめてリストアップしました。

オンボーディングのNotionページ
結果的には自力でチェックボックスを埋めていき、非同期で進めることができたようです。
Notionのページにまとめるもう一つのメリットとして、ページを複製することで他の方のオンボーディングにも利用できる点があります。実際、 @tosh2230 のオンボーディングで利用したページは、いくつか改善したのち @kozee のオンボーディングにスムーズに使うことができました。
Notion を用いたカンバン可視化
さて、4人でチームを改めて結成し、スクラムを回していくことになりました。
今回、スクラムにあたってカンバン作成で使ったサービスの話をします。データチームでは、こちらもNotionを利用しました。
Notionには、以下のようなメリットがあると考えています。
- Board内部の一つ一つのアイテムには自由にタグづけができ、例えばストーリーポイントやステータス、関係する事業部などメタ情報を編集しやすかった点。
- Boardビューが操作しやすく、かつステータスごとに縦に分類して表示できたので、ストーリーのステート変更に対応しやすかった点。
- ベロシティの計測も、リストの計測機能でスプリントごとに行える点。
- 埋め込み機能が強力な点。例えばベロシティの変遷をGoogle DataStudioでグラフにしてNotionのページに貼り付けました。
こと、Notionの、記事に融通無碍にメタ情報を書き込めるという特徴は、物理のカンバンのような手触りを感じました。
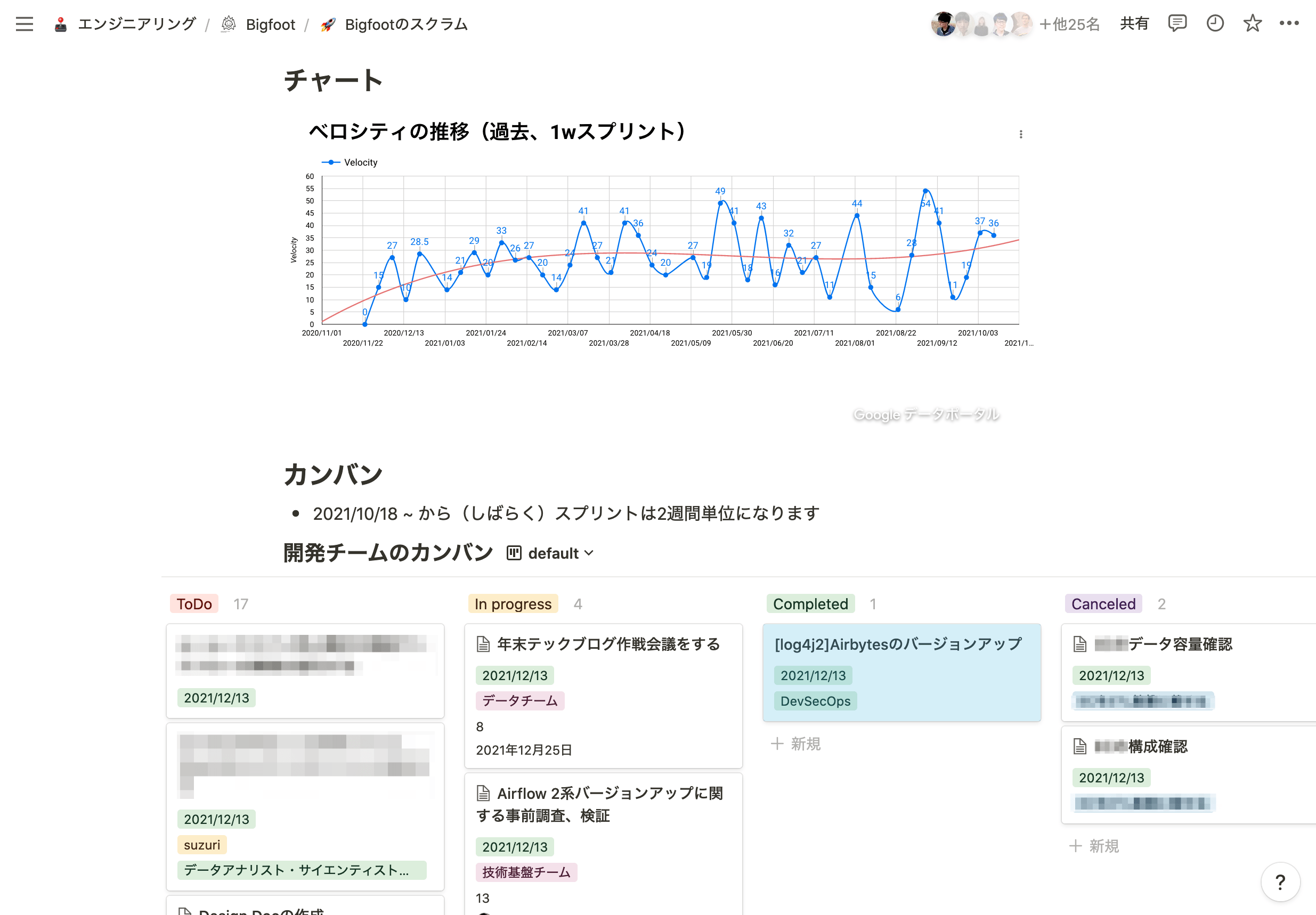
チームカンバンのNotionページ
その後レイアウトは少しずつマイナーチェンジをしていますが、今でもNotionは有効活用しています。
事業部からの依頼フォーマットの整備
4人のチームになったことで、基盤の安定化、SUZURIをはじめとした事業部のビジネスデータのETLの整備、活用のためのデータカタログやデータマートの整備などを随時行っていきました。
その際、データ基盤チームの開発すべき内容は、原則としてチーム全体のOKRを基に、トップダウンで分解していくことで決定しています。
スクラム的な優先順位の決定は最終的に上長で、データ基盤のオウナーでもある @hsbt が行いますが、OKRを基にある程度脳内同期をした上で @udzura が具体的なストーリー・タスクの抽出やそれらの優先順位付けを行って進める形をとっています。
一方で、基盤運営の上ではOKRにない割り込みのタスクもどうしても多くなります。事業部で急遽必要な数値が出てきたり、日々のルーチン上依存しているデータが突然おかしくなったり、などなどです。
それらのタスクについては、いったん事業部側で「それらの開発が必要な背景」や「事業部でかけられるコスト」、「緊急度や影響範囲」などをまとめてもらい、こちらもNotionの専用のリスト(「依頼の壺」などと呼んでいます)に入れてもらうことにしました。一種のエレベーターピッチのようなものと考えてください。
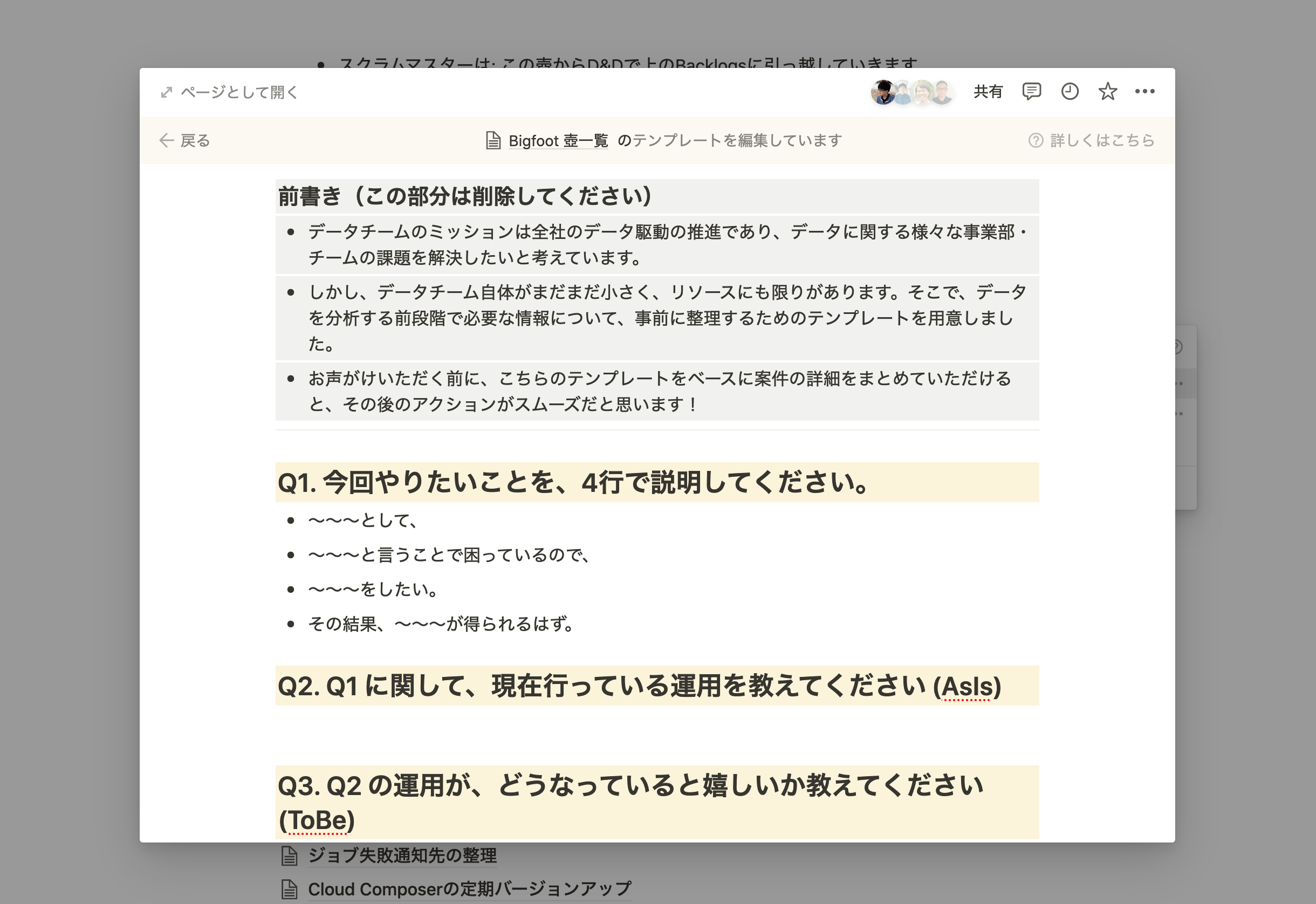
依頼用テンプレートの一部
データチームはその依頼内容について以下のようなフローで対応します。
- 1) まずは非同期的に確認し、緊急度などを把握する
- 2) 本当に緊急であれば @udzura の判断で割り込み作業=Choreとして対応する
- 3) 緊急度が相対的に低そうであれば、締め切りなど要件を満たせるタイミングで対応できるよう、週1のスプリントミーティングで検討する
こうすることで、Slackメンションなどの「同期的な割り込み」の頻発による生産性の低下を減らしています。
Design Doc の試験的導入
SUZURIのETL整備がある程度軌道に乗ったタイミングで、次のゴールとしてエンジニアの生産性の可視化を行うプロジェクトが立ち上がりました。
具体的には、Four Keysに代表されるような各種生産性の指標を選定し、エンジニアのアクティビティデータをGitHub Enterprise ServerのAPIなどを用いてロード、集計をし、streamlitで可視化を行いました。こちらのシステム全体については、今後のテックブログの更新をお待ちください…。
このプロジェクトにおいて、データチームで初めてDesign Docを書いてみることにしました。
Design Docとは、これから新しく開発しようとするソフトウェアなどの全体の設計について基本的な要点をまとめた文章のことです。内容は例えば、
- 開発の背景
- 検討した別の方法
- 設計やアーキテクチャ
- セキュリティの考慮点
…など、ソースコードやPull Requestを見ても読み取りにくいような情報についてなるべく網羅的に残します。事前にある程度これらの情報を書き出しておくことで、メンバーで議論をしやすくすることも目的の一つです。
Design Docのレビューの様子
今回Design Docを事前に作成することで、以下のようなメリットがありました。
- 実装前に設計上難しい点や、議論すべき点が分かり、より負債を残しにくい設計にできた
- アーキテクチャが共有できたため、いざ実装に入る際に、タスクやユーザストーリーをチーム内でスムーズに分担できた
- (これはリリース後のメリットだが)後から入ったメンバーにもシステムの概要が把握しやすかった
デメリット的なところとしては、実装にすぐには入れないため、短期的なスピードは落ちてしまうように見える点は挙げられるかもしれません。しかし、ソフトウェアやシステムはチームで継続的に育てていくものである以上、最初の段階で設計の勘所を脳内同期することは有益であると思います。Design Docはそのための道具としてはなかなか悪くないのではないかと思います。
「うづらの会」(自己開示型振り返り)の開始
ところで、スクラムイベントといえばふりかえりです。最初はオンラインでのKPT方式で行っていましたが、難しい面が目立つようになってきました。こと、「話す人が偏りがちになる」という点が気にかかっていました。
そこで思い切って、オンラインでは気をつけないと忘れがちになる「自己開示」を一つのゴールとして、以下のような形式のふりかえりを行ってみることにしました。
- 参加者全員が、決まった時間だけ事前に決めたテーマについて喋る(今月のKeepとProblemなど)
- 一人が話した後で、その場の全員で質問をしたり感想を述べ合う
- これを(トーク7分程度+質問感想3分程度) x 人数 繰り返す
通称は「うづらの会」と名付けました。振り返りというより、ある意味でテレビのトーク番組のような雰囲気を出すようにしました。なお、まずは今考えていることや抱えていることを喋る、を主眼に置いているので、事前準備などは基本的に行わないようにお願いしています。

「うづらの会」アジェンダの一部
今年の後半はこの形式での振り返りを数回実施しました。結果的にチームの一人一人が、どういうことを考えているかちゃんと共有できるようになったため、その後のスプリントミーティングなどを納得感を持って進められたというメリットがあったように思います。また、今年のデータチームは完全にオンラインで進めたため、皆で集まっている感の補強とか、業務外コミュニケーションの補完を目指したという面もあります。そのため司会役の私が意識してトークの間の雑談や脱線を誘導するようにしました。
デメリットというか難しい点として、司会役には学会で言う座長役のような面も求められるため、その人の技能・裁量にある程度依存してしまうところはあるかもしれません。例えば司会役を持ち回りにする、チーム外の司会業が得意な人を呼ぶなどの工夫もしてみたいところです。
1年間を振り返り、来年に向けて
いかがでしたでしょうか。全体として、原則リモートで進めたのですが、そうであってもチームの中で意見や情報を交換するには十分であったし、工夫でカバーできるところも多かったように感じています。個人的には、チームメンバーに「心理的安全性がある」と言ってもらえたので、チームづくりは一定の成功を収めたのではないかと自負しています。
現在、データ基盤チームは @komatun がジョインし5名のチームになり、来年も増員が予定されています。スクラムのチームとして少し大きくなってきましたが、引き続き生産性をキープすべく様々な工夫を取り入れたいと考えています。
また、今のところチームは東京圏に3名(マネージャーも東京圏)、福岡市近辺に2名が在住しており、引き続きリモート中心でチームを進めます。ただし今後は、コロナ禍の状況次第ですが、落ち着いたタイミングを見計らい出張などでリアル交流を図ることも検討中です。
新しい時代のスクラムチームの作り方の一例としてこの記事が役立てば何よりです。