
こんにちは!ペパボでは今年の6月から8月にかけて、新卒パートナー向けのエンジニア研修を実施しました。 今回は研修に参加した新卒パートナーが研修内容を振り返りながら、研修の中で得た気づきを紹介します。
ペパボの2021年研修では2021年にWebアプリケーション開発を行う上で必要な技術領域について広く扱っています。
- Rails研修
- フロントエンド研修
- モバイル研修
- コンテナ・デプロイ研修
- 機械学習研修
- セキュリティ研修
詳細な研修内容については、先日公開された 「GMOペパボのエンジニア研修2021の資料を公開します」 において講師陣が紹介しておりますので、ぜひそちらもご覧ください! またその他にも外部講師をお招きした1day形式のワークショップや読書会など盛りだくさんでした。 DBモデリングとRSpecについてのワークショップの内容をまとめたテックブログもありますので、気になる方はぜひ読んでみてください。
先日公開された前編では、Rails研修、フロントエンド研修、モバイル研修について紹介しました。
後編の今回は、コンテナ・デプロイ研修、機械学習研修、セキュリティ研修について紹介していきます。
コンテナ・デプロイ研修
こんにちは、新卒11期エンジニアのhomirun(@h0mirun_deux)です。 僕からはコンテナとデプロイ研修について紹介します。
この研修は主にakichanさんとghostさんにご指導いただき、コンテナ・クラウド・デプロイ技術に触ることができ、標準化・抽象化について実戦で使える理解をするという目標をもとに、11日間で以下のような流れで行われました。
- コンテナ
- コンテナの歴史とコンテナから学ぶ標準化・抽象化について
- コンテナを使わない世界と使う世界
- Docker, Vagrant, Docker以外のランタイムをそれぞれ使ってみる
- Docker Composeを使ってみる
- CI/CD
- GitHub Actionsを使ってみる
- パブリッククラウド
- AWSを使ってみる
- Infrastructure as Code
- Terraformを使ってAWSの操作をしてみる
- 総合演習
- Kubernetesに入門してアプリケーションを動かす
それぞれの技術で座学 + ハンズオンを繰り返す形で進行していき、それによって着実に学びを深めていくことができました。
個人的に楽しかったのはGitHub Actionsでした。というのも今までCI/CDを利用することはあってもそれを自分で用意したことはなかったため、今回の研修で実際に手を動かしてデプロイまで行うことができ、これからの業務や趣味プログラミングにも役立てることができそうだなと感じました。
下記の画像はself hostedなGitHub ActionsのRunnerを手元のマシンで動かしたときのスクリーンショットです。手元で実際にJobが動いていて感動しました。

次に、研修の後半で行われた総合演習について掘り下げて話をします。 総合演習は、未知の技術領域に先輩や同僚の力を借りてアプローチできるようになることを目的に行われました。
総合演習は先にも述べたように、Kubernetesに一から入門し、それを使ってRailsTutorialで作成したアプリケーションを動かそうというものでした。実はこれ以外にも要件があり、「コンテナにログインする運用は禁止」、「manifestはGitOpsでデプロイする」など実際の業務に近い要件が設定されていました。
個人的に一番躓いたのはどうやってDBマイグレーションを行うかでした。Initコンテナでマイグレーションを行うとオートヒーリングやアップデートの際に毎回マイグレーションが走ってしまいます。なので、最終的にはJobを使うことでそれを解決する事ができました。
下記は、総合演習で僕が実際に作成したアーキテクチャの図です。この図を書き終えたとき、自分は先輩方や同期と相談しつつもここまで実装できたんだなという達成感がありました。
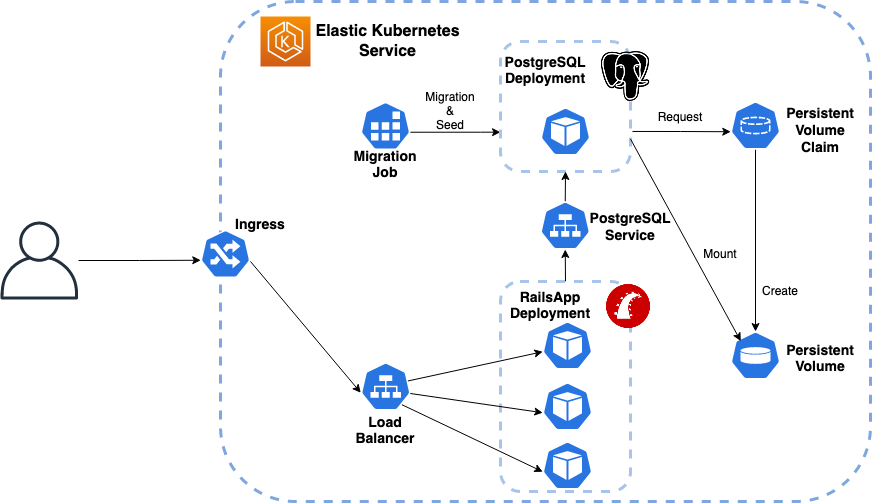
この研修を通して、自分たちが書いたアプリケーションがどのような技術を介して提供されるのかを理解することができました。ここで学んだ技術を用いてこれからバリューを出していきたいと思います!
機械学習研修
こんにちは、わたさん @watasan です!ペパボに入社する前から大学院で機械学習関係の研究をしておりまして、そんな私が機械学習研修で学んだことや感じたことをお伝えしたいと思います。
5日間の研修はデータエンジニアリング(2日間)と機械学習(3日間)の2パートに分かれていました。ここからそれぞれのパートで特に印象に残った内容と個人的な感想をご紹介していきます。
データエンジニアリングパート
データエンジニアリングのパートでは、機械学習について学ぶ前にそもそもなぜデータを収集するのか、またそのデータを扱うためにどのような処理が必要なのかという考え方を教えていただきました。データの扱いの基本的な三要素である
- Extract(収集)
- Transform(変換)
- Load(蓄積)
の頭文字を取ったETLという概念と、それぞれでどのようなことを気をつけなければならないかというお話を聞きました。データを無目的にただ蓄積する、というのは簡単だけれども、量が増えれば増えるほどコストがかかってしまうし、いざ何かに利用しようとしたときに、適切な構造化を施した上での収集がされていないとデータから情報を引き出せないという話はとても納得できました。
また分析を行うためにデータはTransform(変換)されますが、大元のデータが蓄積されている場所と変換済みのデータの保管場所は分けておこう、という話も勉強になりました。分析のプロセスでは不可逆な変換を繰り返すことがよくあるので、ちゃんと大元のデータに戻れるようにという配慮だそうです。
私個人の感想としては、これまで研究のためにデータが必要となった際はオンラインにある既に整理されたデータを扱うことがほとんどだったので、その整理されたデータを作るためにこれだけ考えることがあるのか…と率直に驚きました。今まで使っていたデータを整備してくださった方々にお礼を言わなければという気持ちになりました。「データ駆動」という言葉をよく目にするようになった昨今ですが、データを活かすところまで持っていくことがいかに困難かということを、この研修を通して以前よりも具体的にイメージできるようになれたように思います。
機械学習パート
このパートでは「『機械学習とは何か?』を自分の言葉で説明できるようになる」ことを目的に、機械学習で取り組む主要なタスク(回帰や識別)や基本的な概念(損失関数や汎化誤差など)、学習のテクニック(勾配法など)について学びました。
研修の形式は、座学とハンズオンの二段構えになっており、座学では講師であるペパボ研究所の皆さんがスライドで丁寧に解説してくださいました。数式を軸としながらも、ビジュアルに基本的な概念を教えてくださり非常にわかりやすかったです。一方でハンズオンはGoogleが公開しているMachine Learning Crash Courseが題材となっていました。このCrash Courseは機械学習を実際に利用するために必要な知識が無駄なく配置されていて、なおかつ直感的に操作できるデモや具体例が充実していて素敵な教材だと感じました。基本的にこのコースは英語で書かれていて、たまに数式が書かれているので完全に機械学習が初めての人にとっては少しとっつきにくいかもなぁという印象がありましたが、そこは座学でのフォローアップを丁寧にしていただいていたのでノープロブレムという感じでした。
座学もCrash Courseも、エンジニアが機械学習を学ぶなら?という観点で説明がなされていたのが非常に印象的でした。たとえば座学では、「機械学習は、ある関数の入出力を左右するパラメータを、プログラマがマニュアルで決めるのではなく、データから自動的に決めるために利用される技術」と、ソフトウェア開発の観点から説明がなされていました。この説明の仕方は機械学習の入門本ではあまり見たことがないですが、非常に分かりやすくて個人的に感動しました。
また研修の最終日では応用編として、BigQueryを操作して実際のペパボのサービスのデータにアクセスし、そこから識別モデルの訓練と予測までおこなってみるという、データエンジニアリングパートと機械学習パートの集大成的なハンズオンを行いました。BigQueryではBigQuery MLという機械学習モデルの構築と実行をSQLクエリでサポートする機能を提供していて、それを実際に触らせてもらいました。データの収集からモデルの訓練と予測までを1つのクエリ文で出来てしまうのが非常に快適で驚きました。また、実際のサービスのどのような場面に機械学習を活かすことができるかという実例を示していただけたので、これからサービスの開発をしていく上で課題にぶつかった時に「この課題は機械学習で解けないか?」と考える視点をいただけたように思います。
データエンジニアリングパートも機械学習基礎・応用パートも資料は全て公開されている研修資料に含まれていますので、ぜひご覧いただければと思います!
セキュリティ研修
講義資料:https://github.com/pepabo/training/blob/master/security/web-security-training-2021.pdf
どうも、yagijinです。他の新卒のみんなの力を借りつつセキュリティ研修について紹介できればと思います。 この研修ではmrtc0さんよりWebアプリケーションのセキュリティについて5日間にわたって講義していただきました。
講義の冒頭ではイントロダクションとして、セキュリティを学ぶ必要がある理由やペパボでのセキュリティに対する取り組みについて、実際の事例を交えながら紹介していただきました。 ペパボのセキュリティへの取組みについて興味がある方は、社外向けの記事としてlogmiでの記事がありますので併せてご覧ください。
研修の前半:脆弱性についての座学と攻撃体験
前半は、CVEなどの分類や用語、要素技術や脆弱性の種類について学びました。具体的に学んだトピックは以下の通りです。
- Web セキュリティ基礎
- ブラウザの仕組み
- HTTP
- Same Origin Policy
- Cookie とセッション
- セッションハイジャック
- CSRF
- Fetch Metadata
- XSS
- SQLインジェクション
- オープンリダイレクト
- ディレクトリトラバーサル
- RCE
- CORS
- 安全なアプリケーションの作りかた
- 認証、認可
- ログ
- 秘匿情報の管理
- セキュアコーディングについて
また、セキュリティへの意識を高めるために攻撃者側を体験してみようということで、PortSwiggerのWebSecurityAcademyというサービスを使って脆弱性を実際に攻撃してみるワークも行いました。当たり前ですが実際のサービスに対してはしてはいけない行為なので、なんだかドキドキしながらワークを進めました。実際に攻撃してみることで、脆弱性によってはサービスにとって致命的なリスクになることを体感することができました。具体例を出すと、よく聞くSQLインジェクションがデータベースから任意のデータを抜き出すことのできる絶対に作ってはいけない脆弱性の一つだと再認識できましたし、ユーザーからの入力は絶対に信じてはいけないという教訓が得られました。
後半:脆弱性を実際に修正する
後半は実践編ということで、脆弱性の修正を体験しました。 事前に用意された脆弱性を持ったRailsアプリケーションを題材に、ここまで学んできた脆弱性を探し、修正するというワークがありました。このワークはチームに分かれて行ったのですが、脆弱性について話し合いながら行うことができたので良い復習になりました。また、このワークでは脆弱性が修正できたか確認できるテストが用意されており、実際に修正できているかすぐに確認することができました。
セキュリティ研修のまとめ
セキュリティ研修では、幅広く脆弱性やそれが生まれやすい部分について学ぶことができました。また、体験を通して個々の脆弱性の脅威の違いや対策についても学ぶことができました。
そんな中でも、最初のイントロダクションでの「攻撃者は一つでも穴を見つければ勝ち、サービス側はすべての穴を防がなければならない」というmrtc0さんの言葉が印象に残っています。 セキュリティは、忙しいからといっておろそかにしてはいけなく、常に狙われているという意識を持ち、コストを掛けて維持していかなくてはならないものだと再認識することができました。
また、Webアプリケーションのセキュリティは見なくてはならない領域がとても広いことがわかりました。 なので、エンジニア各々が意識していても1人ですべての領域を網羅することは不可能で、組織として取り組む必要があると感じました。 そんな中、社内にセキュリティ対策室があってmrtc0さんのようなスペシャリストがいる環境はとても心強いことだと思いました。
以上、セキュリティ研修の振り返りでした!
終わりに
前編に続いて、2021年度のペパボエンジニア研修について振り返ってみましたが、いかがだったでしょうか。
ペパボエンジニア研修では、サービスを形作る技術について幅広い領域に渡って学ぶことができました。 この後、2021年度の新卒エンジニアたちは様々な部署に配属されました。 研修で学んだことを糧に、各部署でぐんぐん成長していきたいと思います!
研修に携わってくださった皆さん、ここまで読んでくださった皆さんありがとうございました!!



