
Netflixジャンキーこんにちは。Stranger Thingsのシーズン3が公開されてましたね!もう見ましたか?僕はやっと最近見れました。Netflix Originalが大好きなプリンシパルエンジニアの@linyowsです(オススメは、DARKです)。
私は、福岡のGo言語コミュニティであるFukuoka.goのオーガナイザーの1人でもあるんですが、はじめてのGo Conference地方開催を、福岡で、Fukuoka.goのメンバーとともに行いました。「Go Conference’19 Summer in Fukuoka」には、GMOペパボから多くのエンジニアが登壇または参加しました。
ということで、当日の発表を参加者のリレー形式でかいつまんで簡単にご紹介していきます。
“Cost-effective Go unit test thinking and practices” by hgsgtk
こんにちは。ロリポップ!マネージドクラウドでエンジニアをしています@k1LoWです。私からは@hgsgtkさんによるCost-effective Go unit test thinking and practicesについて紹介したいと思います。
まずタイトルやセッションのアブストラクトから目を引くのは「Cost-effective」「費用対効果の高い」という単語です。テストを書くことが当たり前になった今、とても興味のある切り口だったので聴講させていただきました。発表資料はこちらになります。
費用対効果とは。コスト削減とは
セッションでは、まず「なぜUnit Testを書くのか?」の回答として「コスト削減」と述べていました。Unit Testのコストは「Unit Testによるコスト削減(左辺)」と「Unit Testの作成・維持コスト(右辺)」の不等式で成り立ち、左辺が大きい状態を保つことが「費用対効果」があると言えるということだと、とてもわかりやすい図で説明されていました。
つまり、「コスト削減」とは、左辺の最大化と右辺の最小化ということですね。
GoによるUnit Testの基礎的な考え方
“Go Unit Test Basic”の章では、Goが公式的に提案しているテストの考え方について、3つ紹介していただきました。そしてその提案が前章の図におけるどのような「コスト削減」に繋がるかを述べていました。3つの中で、私が「あーよくやりがちだ」と思ったのは「適切なエラーリポート」になっていないテーブルテストを書いてしまうことです。
for _, tt := range tests {
if got := some.Func(tt.arg); got != tt.want {
t.Errorf("got = %v, want = %v", got, tt.want)
}
}
上記だと複数エラーが発生したときに
sample_test.go:22 got = true, want = false
sample_test.go:22 got = true, want = false
という、どのテストがエラーになったかわからなくなるリポートが出てきてしまいます。
セッションでは、Goの公式FAQにあるように「直接的かつ適切なエラーリポートにする」ことが大事だと述べていました。これにより上記は
for _, tt := range tests {
if got := some.Func(tt.arg); got != tt.want {
t.Errorf("some.Func(%v) = %v, want = %v", tt.arg, got, tt.want)
}
}
と改善できます。ちなみに私は
for _, tt := range tests {
if got := some.Func(tt.arg); got != tt.want {
t.Errorf("%v: got = %v, want = %v", tt.name, got, tt.want)
}
}
としがちです。ただ、これだとテストの意味を tt.name で説明しようとしている点が確かに直接的ではないと思いました。
現場でのテスト
最後の章では「現場でのテスト」をテーマに3つのプラクティスを紹介していただきました。今回はそのうちの2つを紹介します。
カスタムアサーション
1つ目はテストコードでも共通処理をまとめる意識を持つというお話でした。テストコードが増えてくるときに、どのように「Unit Testの維持コスト」を抑えるかという観点で、共通処理を行うヘルパーを書くという選択肢を示されていました。そしてそれは継続的にメンテナンスをしていく必要があると述べていました。
テストをコピぺして使い回すことによって、テストが汎用的になり、汎用的になるとエラーメッセージも抽象化され、不親切なエラーメッセージになってしまうことは、個人的に実体験としてあるあるでしたので、耳が痛いお話でした。
RDBMSを使う処理のテスト
2つ目を飛ばして3つ目は、RDBMSを使う処理のテストについてです。Goに限らず、本当にありがちな2択である「実際のDBを含めたテストをするかどうか」という課題に対して、丁寧にまとめて示していただきました。
それぞれに対して、@hgsgtkさんの実感値として、
- 実際のDBを含めたテストの場合は、実際にDBを使った処理なので欠陥の発生可能性は低くなりますが、テスト実行時間が長くなりがちになる
- 一方で、DBを使わず「期待したSQLを発行するか」を検証するようなテストにした場合は、テスト実行時間は短くなりますが、期待値のSQLが間違ってしまう可能性がある
とし、上記のようなPros/Consから、こちらもどのような「コスト削減」に繋がるかを述べられていました。
では、「@hgsgtkさんが実際に現場でどちらを選んだ」か、について、確か口頭では「実際のDBを含めたテストを書くことを選択した」とおっしゃっていた気がしたのですが、なぜそうしたのか、どのようなテストに対してそうしたのか、Pros/Consをどう捉えたのか、を懇親会で聞こうと思っていて聞きそびれてしまったのが心残りでした。
感想
「コスト削減」という切り口で、テスト手法における様々なアドバイスを得ることができました。発表者の@hgsgtkさんは普段から複数のプログラミング言語を扱っているからか、Go言語だけにとどまらない汎用的な領域で発表をされていたように感じました。
普段ロリポップ!マネージドクラウドの開発で、GoだけでなくGo以外の言語で作られたWebアプリケーションでもテストについて考えることがある私にとって非常にありがたいセッションでした。
“Data aggregation design with Goroutine, Channel, “sync” package, and Simple diagram” by k1LoW
引き続き@k1LoWです。今回、私も発表をさせていただきました。
セッションでは、「データを収集して処理する=入力を処理して出力する」という要件をGoでどのように実装していくかについて、実際に作成したツールを例に紹介しました。
パイプライン
「入力->処理->出力」の流れについて、入力を効率的に処理し出力することを考えると、必然的に入力から出力までの間はストリームデータの処理(パイプライン処理)になります。パイプライン処理は「入力->処理->出力」ということもあれば、「入力->処理->処理->出力」となることもあります。上記の各要素をパイプラインにおけるステージとして別のコンポーネントとして定義します。そしてステージごとの処理を並行処理(goroutine)で書くことによって、効率的なGoらしい実装で書くことができます。
例えば、1つのステージは以下のように書くことができます。
type Stage struct {
out chan Out
}
func NewStage() (*Stage, error) {
out := make(chan Out)
return &Stage{
out: out,
}, nil
}
func (s *Stage) Handle(ctx context.Context, in <-chan In) <-chan Out {
go func() {
defer close(s.out)
L:
for i := range in {
select {
case <-ctx.Done():
break L
default:
doSomething(i, s.out)
}
}
}()
return s.out
}
具体的なユースケースとアーキテクチャ
セッションではパイプラインを考慮した具体的な実装を4つ紹介しました。今回はその中で、一番簡単なものとして標準出力に色をつけるツールcolrの例を紹介します。
colrは以下のように、ストリームデータを標準入力として受けて、指定した文字列に色をつけるだけのツールです。

これをどのように実装したかというと、以下のように、入力と処理と出力のステージからなるパイプラインと考えました。
- 入力…標準入力
- 処理…指定した文字列に色をつける
- 出力…標準出力
実装を図で表すと以下のようになります(この図がタイトルにもある”Simple diagram”です!)。
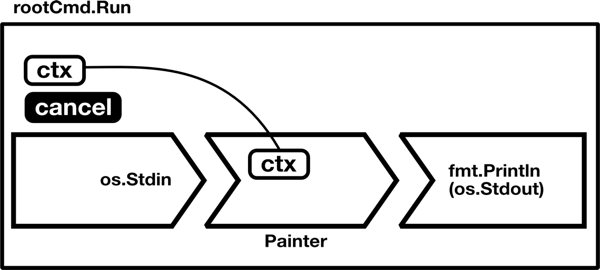
このように、ステージで考えることで、図に書き起こしやすく、そしてそのまま実装に落としやすいという実感があります。
感想
今回、データ収集処理にフォーカスして、4つのケースと実装を例にアーキテクチャを紹介しました。Twitterのタイムラインを見る限り、デモと図とコードを混ぜて説明することでわかりやすいという感想をいただけて安心しました。今後も手を動かして知見を得て、それらを紹介できればと思います。
“How to Write Go CLI Tools” by qt_luigi
こんにちは、ryoma123 です。私からは @qt_luigi さんのセッション How to Write Go CLI Tools についてレポートします。
発表資料はこちらです。
こちらのセッションでは、Go による CLI ツールの作成によって得られたヒントや注意点について発表されていました。これからツールを作成してみたいと考えている人にとって、とても役立ちそうな内容となっています。
それでは発表内容を振り返っていきます。
コマンド
CLI ツールを作成する際に気をつけるポイントを順に紹介されています。
- コマンドは組み合わせて使われる
- 標準出力と標準エラーを認識
- マルチプラットフォームへの意識
- 終了ステータスの使い分け
コマンドはワンライナーやスクリプトでひとまとめにして利用されることがあります。 | (パイプ)と一緒に複数のコマンドを組み合わせて利用されることもあるため、標準入出力に気を配る必要があります。また、標準エラーを Go で扱うには fmt パッケージの Fprint 関数を利用することができます。引数によって標準出力と標準エラーを指定することができます。
マルチプラットフォームで利用可能にするには、Unix系、Windows系の対応が必要です。複雑な部分は Go によって吸収されていますが、考慮が必要なものとして、改行コードとファイルのセパレーターを紹介されています。コマンドの実行結果を表す終了ステータスについては、 Exit() 関数の引数にて指定することができます。
このようにメッセージの出力先や終了ステータスなど考えることは複数ありますが、Go のソースコードを参考にすることは役に立ったと @qt_luigi さんはおっしゃっていました。
自分も OSS として公開されている CLI ツールの実装から考慮すべき点や解決のアイデアを間接的に教わった経験がありとても納得しました。Go のソースコードも読んでいこうと思います!
外部リソースの解放
メモリの解放は Go の GC が行ってくれますが、外部リソースは Close() メソッドを利用して明示的に解放する必要があります。その際に defer を利用すると呼び忘れを防ぐことができます。ただし、compress や archive 等の標準パッケージで利用される Flush() メソッドに関連する場合は使用しないこと、関数化する場合には for ループに含めないことも紹介されています。
なお、自分の手元でもアンチパターンとして紹介されている サンプルコード に標準出力を加えて実行してみると、for ループの中で defer が蓄積される様子を確認することができました。
$ go run cmd/print_go_line/main.go sample
for ループ開始
sample/1.txt を Open()
sample/2.txt を Open()
sample/3.txt を Open()
for ループ終了
sample/3.txt を Close()
sample/2.txt を Close()
sample/1.txt を Close()
パッケージ
Go のディレクトリ構成のパターンは複数存在しますが、main パッケージを cmd ディレクトリ配下に配置する方法を選択されています。主に以下のメリットが得られます。
- main パッケージ以外が外部パッケージとして利用可能になる
- main パッケージは利用可能なパッケージのサンプルコードになる
使われどころについても意識する必要があり、goroutine から呼ばれるケースや、クラウド、モバイル、共有ライブラリ、Webブラウザなどの動作環境が考えられます。また、パッケージ内では exit や panic を使用せず、 error や終了ステータス値を返すことによりパッケージ利用者で対応できるようにします。関数をモジュール化する際にも、エラー内容からプログラムの終了、続行をハンドリングできるようになります。エラーに関しては、意図しない箇所でプログラムの中断が発生しないように自分も注意して実装しようと思いました。
発表内容のご紹介は以上です。
感想
@hgsgtk さんより、Go で CLI ツールを作成する際に気をつけるポイントを分かりやすく解説していただきました。発表を聴いて、手を動かして Go の知見を得ること、だれかに利用される場合をしっかりと考慮することを意識的にやってみようと思いました。ありがとうございました!
“Goでつくる進化計算パッケージ” by tsurubee3
ホスティング事業部でエンジニアをしている @takumakume です。私からは @tsurubee3 さんの 「Goでつくる進化計算パッケージ」 について紹介します。
内容としては進化計算/遺伝的アルゴリズムの説明と、それをGoで実装した話。最後に、今回実装された eago を使ったデモを見せていただきました。私自身、数学やアルゴリズムの知識を持っているわけではありませんでしたが、非常に分かりやすくアルゴリズムの特徴を説明されておりどういう課題を解決するものなのかを理解できました。
進化計算について
今回実装された eago は進化計算という生物の進化や振る舞いを模倣した最適化手法が用いられています。進化計算はメタヒューリスティックな手法であり、特定の問題のみでなく様々な問題に対して 近似解 を効率よく求める解法であると期待されています。eagoでは以下の2つのアルゴリズムを実装しており、後者について紹介がありました。
- 粒子群最適化
- 遺伝的アルゴリズム (GA)
筆者はアルゴリズムの種類について詳しくないのですが、近似アルゴリズムのように最適解を求めることが現実的に難しいような課題に対して実用的な処理時間とある程度の品質をもって解を出すというアプローチは面白いなと思いました。これを用いて人間ではたどり着かないような解を得て新たな価値を生むエンジニアリングに興味が湧きました。
遺伝的アルゴリズム (GA) について
集団の中で環境に適応した個体がより高い確率で生き残り次世代に子を残す自然淘汰説の仕組みをソフトウェア的に模倣する手法です。
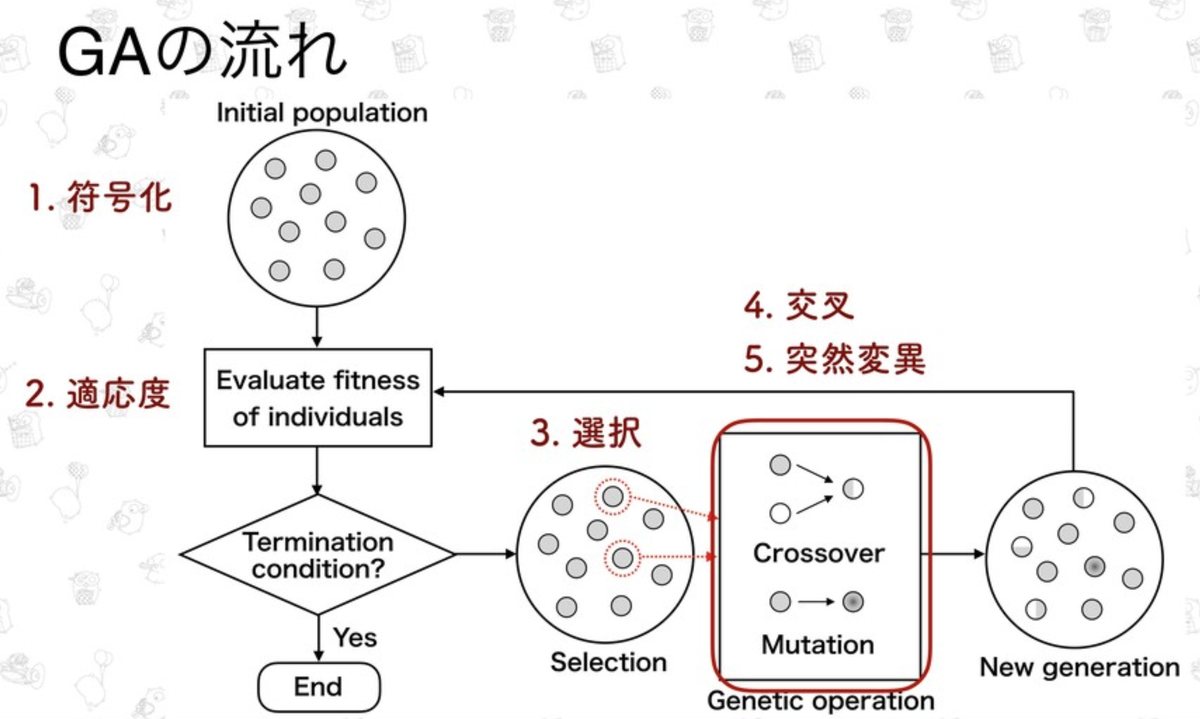
- 符号化
- 適用度
- 選択
- 交叉
- 突然変異
これらの処理の繰り返しによって近似解を求めます。
Goによる実装
まずは、なぜ Goを用いて実装したのかの解説でした。大きな理由として挙げられたのが計算時間の短縮でした。GAは膨大な計算量が必要である・多点探索アルゴリズムであるため並列化と親和性が高いという特徴があります。そのため、並列処理が書きやすいGoで実装してみたという内容でした。
筆者もGoを用いて並列処理を書くことがあるのですが、それはやはり標準パッケージで用意されている機能を使ってシュッと書けることも挙げられるので共感しました。書きやすいことは生産性につながるし、書いてて楽しいと思います。一方で機械学習の分野でGoがより活用されるために必要な要素として他になにがありそうなのかを知りたいなと思いました。
Gopherくんの画像生成デモ

上の画像のように、Gopherくんの画像が生成されるデモを見せていただきました。会場からの質問で、最後は綺麗なGopherくんの画像になるのですか?というのがあったが、進化計算は近似解を効率良く求める手法なので、100%きれいな画像を生成することはできないということでした。
感想
遺伝的アルゴリズムなどを用いた機械学習の分野の多くは Python を用いた事例が多い中、アルゴリズムのと並列化の親和性とGoの並列処理の実装の容易性をかけ合わせてシュッと実装されており、改めてGoの良さを感じました。今後、どれほどまでに機械学習の分野で Goが活用されてくるのかが非常に楽しみになる発表でした。
発表ありがとうございました!!
“Cloud Functions in Go at Mercari” by b4b4r07
こんにちは。ホスティング事業部でエンジニアをしている @genkiroid です。私からは @b4b4r07 さんが発表された『Cloud Functions in Go at Mercari』についてのレポートをさせていただきます。発表資料は以下になります。
扱っている問題について
ご存知の方も多いと思いますが、メルカリ社ではモノリスからマイクロサービスへの移行を精力的に行っています。マイクロサービスへの移行は、当然ながら一朝一夕で行えるものではないため、メルカリ社においてもその取り組みの中で遭遇した様々な課題とその解決について、様々な技術イベント等で紹介がされています。
メルカリ社では、マイクロサービスへの移行について、大きく2つの目的を設定しているとのことでした。1つ目は、”組織を再編し組織としてのアウトプットを最大化するため” 、 2つ目は、”技術的な課題を解決するため” です。明確な目的ですね。そして、今回の発表で扱われている問題は、上記の目的が本当に解決・達成されているのか?という組織としての自問でした。
問題への対応について
問題の認識が出来たところで、それに対してどのようなアプローチによって解決を図ろうとしているのかという点に話が移ります。
一言で言えば、メルカリ社は目的に対する成果に関する指標を集め、それを可視化するという手段によって、問題の解決を図っていました。「目的に対する成果に関する指標」については、ひとつの例として『ACCELERATE』(Forsgren, Nicole, Ph.D. / Jez Humble / Gene Kim 『Accelerate: The Science Behind Devops: Building and Scaling High Performing Technology Organizations』It Revolution Pr, 2018 年) という書籍に登場する “生産性の高い組織において開発者数とデプロイ数は比例関係にある” という指標を挙げられていました。今回の発表では、この指標を題材とし、その指標をどのように収集し、可視化したかという流れで話が展開されていきます。
まずはじめに、DevStats というものが紹介されました。これは、Datadog のダッシュボード、指標を収集する実装である Collector 、そして Collector 実装のための Go パッケージの3つからなるソフトウェアの総称とのことでした。Datadog のダッシュボードについては、当然ながらビューにあたり、可視化手段を提供するものでした。収集した指標を保存するストレージとして、今回のケースでは Datadog を採用されたようですが、本質的には他のミドルウェアでも良いと思われます。実際、DevStats では、そのレイヤは置換可能になっているのかも知れません。
次に、DevStats の Collector 実装のための Go パッケージとしての役割ですが、これは、様々な指標を収集して他のレイヤで扱えるように整形してアウトプットするといった、Collector に必要な機能を抽象化し、実際に特定の指標を扱う Collector 実装を行う際に便利なパッケージという位置づけでした。DevStats では、Collector のインタフェースとして、データソースとなる指標を集めてそれを利用目的に合ったメトリクスとして生成する Producer というものと、メトリクスを利用する側に向けてメトリクスを流す Exporter というものを定義しているとのことでした。とてもシンプルな設計だと思いました。
Collector 実装については、mercari/devstats-collectors というリポジトリがちらっと紹介されており、ぱっと見た感じでは、すでに様々な Collector 実装が存在している雰囲気を感じました。公開されていないので雰囲気だけです。
さて、上記を用いることによって、目的に対する成果に関する指標を集める道具はそろった感じですが、これらの道具とくに収集の部分のランタイムをどこに置くかという部分が残っています。これについては、インフラレイヤの技術の発展により、現在では DC で物理マシンを選択するというメリットはほぼなくなっており、コンテナ基盤を利用するか、Serverless かという2つの選択肢に絞られた様子でした。今回のケースでは、
- 関数の呼び出しのたびに起動され課金されるのでアイドル時間のコストを抑えられる
- インフラやリソースを管理しなくてよく、コードを書くことだけに集中できる
という2点を優先した結果、Google Cloud Functions をランタイムとして採用したとのことでした。Collector 実装を関数としてランタイム上で実行させるという理解です。
Google Cloud Functions については、2種類の関数が紹介されていました。HTTP function と Background function です。前者については、マイクロサービスごとの k8s マニフェストを管理するリポジトリにおいて、デプロイ(deployment を apply)するタイミングで、HTTP 経由で Collector をトリガーするというものでした。これにより、デプロイ数というメトリクスを収集出来ることになります。後者については、マイクロサービスごとの開発者を定義した Terraform リポジトリに対して、スケジューラによってトリガーされる関数により、Collector が動作し、マイクロサービスごとの開発者数をメトリクスとして収集することが出来るようになっているようでした。
これらのしくみによって、自動的に開発者数というメトリクスとデプロイ数というメトリクスが、マイクロサービスごとにそろうことになります。これはつまり、”生産性の高い組織において開発者数とデプロイ数は比例関係にある” という論説を実際に収集したメトリクスによって可視化し、確認出来ることにつながるわけです。
実際に成果がどうであったのかという詳細は、発表では述べられませんでしたが、チラ見出来たキャプチャによると、右肩上がりでグロースしていたように見えました。(いいなー。)
感想
一番印象に残ったのは、「果たして本当にこれらが解決されているか?」という自らの問題提起の部分です。ともすれば、「マイクロサービス(的な何か)に移行したぞ!やったー!ばんざーい!」と盛り上がっている裏で、実情はシステムアーキテクチャにおける複雑性が増しただけの結果に終わり、マイクロサービス(的な何か)化した後の成果を真摯に分析していないことにより、本来解決したかった問題、またその先に見据えていたはずのサービスがユーザーに届ける価値の向上などが置き去りにされるといったケースも珍しくないでしょう。そうした、脱線、手段の目的化といった過ちを踏まず、きっちりと取り組みに対する成果を求め、技術的にそれを確認出来るようなしくみを産み出しているというのが、エンジニアとしてとても参考になりましたし、エンジニアリングしているなぁと感じました。
また、Go という言語の観点では、Collector の Producer インタフェースと Exporter インタフェースが、Collector の振る舞いを必要十分な感じで抽象化した、とても小さなインタフェースになっており、そのあたりが Go の世界で良いとされているインタフェースの設計と合致していて参考になりました。
“Goでツールを量産する僕の方法” by songmu
はい、こんにちは、ご飯って何度食べても飽きないじゃないですか、朝、昼、夜、毎日ご飯を食べるという行為をしているのに全く飽きが来ない、これってとっても不思議ですね・・・どうも、@pyama86です。僕は @songmuさんのセッションをご紹介します。ご本人のブログおよび資料はこちらです。
本セッションではCLIツールを量産してきた話し手が、CLIツールを開発するにあたって便利なテクニックや、フラグの扱い、プロセスの扱いについて紹介しています。僕自身はこのトークを東京でもショートバージョンで聞いており、東京ではGNU timeoutコマンドがプロセスを停止する挙動を「無敵になって自爆する」という比喩がそれなりにうけておったのですが、福岡ではドンズベリしていたので、さすがの @songmu さんもアウェイ戦ではそのユーモアを存分に発揮できないのだなと感じました。
また、セッション後に話す機会があったので、CLIツールを開発するときのbootstrapをどのようにしているかを訪ねたところ、godzilというご自身で開発しているコマンドを用いているとのことでした。僕自身は新しいコマンドを書くときはgcliを利用していることが多いのですが、毎回同じような変更を付け足しているので、ある程度コマンドを作る機会が多い方は自身で実装するのが良いのかもしれません。
“Linux middleware development by Go” by pyama
話は変わり、僕自身もGoを用いてShared objectを実装する際に、自身が体験した挙動を共有するセッションを行いました。
それらを調査する過程、開発する際に気をつけるべきことを資料に記しているので、ササッと読んでおくと今後の人生において役に立つことがあるかもしれません。
僕は今このブログを羽田〜福岡間の移動中に書いておるのですが、最近の飛行機は便利ですね、空の上にいてもブログかけちゃうんですもんね、良い世の中になったものです。
8月末にはまたbuilderscon tokyo 2019で東京におりますので、是非会場でお会いしましょう。
“Go初心者がgoroutineで挑んだFTPプロキシ開発” by ryu
こんにちは、heat1024 です。私からは自分が発表したスポンサーセッション Go初心者がgoroutineで挑んだFTPプロキシ開発 についてレポートします。
FTP Proxyの必要性について
GMOペパボのホスティングサービスで使うFTPシステムは、他のシステムと同じ構成で、usersサーバと呼んでいるユーザデータを保存するwebサーバに、FTPサービスを立ち上げてクライアントが直接接続する仕組みです。したがって、何らかの理由でサーバを移設すると、FTPの接続先も変わってしまいます。この構成だと、サーバ内のユーザ領域を移設し難いし、リソースの割り当てが難しい状態でした。
さらに、ユーザが接続するusersサーバの番号をお客さまに知ってもらう必要があるので、ユーザコンソールページでusersサーバの番号を確認してもらう必要がありました。ということで、私たちは、ユーザの使用とリソース管理をより良くするため、ユーザとusersサーバの間に、FTP Proxyを導入することにしました。
なぜgoroutineが大量に必要なのか
まず、FTP proxyは1セッションあたりクライアント側とサーバ側の2セッションを作らないといけないので、それぞれの接続に1個のgoroutineを割当しました。そこにFTP的な仕組みてデータ転送のための接続は別セッションになります。それぞれの接続をhandlingするgoroutineも含めてFTP proxyは、1クライアントの接続に6個のgoroutineが発生しています。
Leakを探す方法について
大量にgoroutineを使うため、どんどん割当したsocket数が増えていく事がgrafana上で見えました。Leakする場所を探すため、下のように発見と修正を繰り返しながら今までやっています。
- 400個以上一気に接続をかけるストレステストみたいなテストを入れました
- 大量接続を実行する前のgoroutine数と、テストが終わった後のgoroutine数を比較します
- 失敗した時は問題になる部分をログからちゃんと調べます
- 原因特定できたか調査して修正します
その流れの中で、学んだ事や覚えたスキルなども話しながら最近もバグ修正していた事も紹介したりしました。
- write connectionをただクローズするのではなく、EOFを送信する方法
- socket reuseを設定して同じポートを同時に使えるようにする方法
- 4ケースの転送モードが設定可能になった事
感想
FTP proxyは、マルチスレッドの処理が必ず必要な、複雑なプロセスだと思いましたが、なんとなく実サービスで使えるものが作られました。開発経験も短い自分が実装する事が出来たのも、そのおかげでこうしてGo Conferenceに登壇して発表する事ができたのもGoが提供するgoroutineの圧倒的な便利性があるから実現できたなと思います。しかし、goroutineは便利だけどその分Leakしやすい危険も持っているので、気を付けながらもっと楽しく開発していきたいです。
Go Conferenceに参加できて嬉しかったです。ありがとうございました!
まとめ
Go Conference’19 Summer in Fukuokaの発表紹介はいかがでしたでしょうか?当日は、全30の発表がありましたので、全部をご紹介できませんが、参加者が興味深いと感じたセッションをご紹介いたしました(全部の資料を見るにはオフィシャルをご覧ください)。ペパボ ではGoを使って、APIやLinuxミドルウェア、Kubernetes関連のツールなどを現在開発しています。Goを使ったシステムプログラミング興味がある人は、ペパランチョンというペパボ のエンジニアと気軽におしゃべりする制度がありますので、利用していただければと思います!では、最後まで読んでくれてありGoとうございます!(完全にqt_luigiさんの影響をうけている)



