おはようございますこんにちは、こんばんは、初めましての人は初めまして、GMOペパボの情報システムグループでエンジニアをしている西畑です。
今回は私が作成したbotについての話をしたいと思います。どのようなbotかというと、ペパボ内での制度や日々の困り事があった時にどの部署に問い合わせるのがよいのかを推薦してくれるbotです。 ここでの困り事とは、技術的に分からない事やお客様への対応方法がわからないというような業務のスキルに関するものではなく、例えば使っているPCが壊れた、経費精算の仕方がわからないといった業務上必要になる雑務的なものを処理する上での困りごとを指します。
社会人の方であれば、経費精算や備品のトラブルで何処かに対応を依頼するという経験をしているのではないでしょうか。学生でも似たようなケースはありそうですね。 そういった、いわゆる組織内の取り決めやフローについて疑問を抱いていたとしてもGoogleで検索しても出てくるものでもないし、どこでその疑問をぶつけるべきかわからない、というような経験をお持ちの方が居るはずです。 経費精算なら経理、といういかにもわかりそうな問題もありますが、PCトラブルはどうでしょう。ペパボではPCのセットアップは情報システムグループが担当となっていますが、物品調達と実際に使用者とやり取りして渡すのは総務部が担当しています。 このような問題はどちらに聞くのが正解なのかわかりづらいですね。
さて、この手の問題を解決するために皆さんはどのようなアプローチを取っていますか? 先輩やメンター、上司などに質問するのがよくあるやり方に思えます。もしかしたらなんとなくこの部署だろう、と当たりをつけて適当に聞くかもしれません。 ペパボでもいわゆるバックオフィスと呼ばれる人たちが各部門ごとにSlackにチャンネルを持っており、パートナーが質問したり対応を依頼します。部門内でパートナーの疑問が共有されて、属人化を避けられる良い仕組みだと私は思っています。
ではその仕組だけで十分かというとそうではありません。このようなどこに聞くのが良いかわからない問題というのは質問者も、質問を受ける人も負担を感じるものです。例えば、下記のような事象が考えられます。
- 質問先を間違えて質問してしまい、質問者がたらい回しになる
- 異口同音の質問を受け、その度に回答する必要が出てバックオフィスの負担が増える
- 結果チャンネルが忙しそうな雰囲気を醸し出し質問しづらくなる
以上に上げた例だけではなく、様々な依頼や質問が来ます。依頼には対応するとして、質問者からの質問に答えるだけで沢山の時間を費やすことになります。 そして、バックオフィスの仕事は本来質問に回答することではないということを踏まえると、質問が増えるのは嬉しいことではありません。質問者も質問したくて質問をしているわけではないはずなので、双方ともに不幸な状態です。
たとえ疑問をなくすことはできなくても、質問の回数を減らすことはできるのではないか?と考え、botによるアプローチを試みました。
どんなbotを作りたいか
理想を言えば、質問者の質問に答えを返してくれるbotが欲しいですよね。更に理想を言うと、僕の代わりに仕事をしてくれれば最高です。しかし実現は難しいので、実現可能な範囲まで機能を絞るところからはじめました。
botにできること、できないこと
今回作成したbotに求められる要件は、質問者の疑問を解決することです。そして、Slackで動作するbotであれば質問に対する答えを返すことが容易にできそうに思えました。
ここでいう答えとは、質問への 回答 ではなく、何らかの 応答 という方が正確です。
しかし、botが質問者の抱える問題を解決するということは難しいのでは、とも考えられました。例えば、情報システムグループによく来る質問を例にすると
質問者:社内システムへのログインができなくなっちゃいました!問い合わせ先はここでよいですか?
bot:いいよ
と、質問への応答として YES を返すようなことは出来そうです。しかし、下記のようなことは難しいとも考えられます。
質問者:ファイルサーバへのログインができないので、アクセス権をください!
bot:……
人が何かしら判断する必要がある(上記の例の場合、アクセス権を付与してよいか?ということ)ようなことはbotには難しいですし、コントロールするために人の監視が必要になるとも考えられます。 単にアクセス権の付与コマンドを走らせるのではアクセス権の制御をしている意味がなく、人や制度での制御が必要なことだからです。
このような理由から、今回botには単純な応答を返す機能を実装するに留めることにしました。
botの返す応答を考える
質問に答えてくれるのがやはり最強では?という考えに至るのに時間はかかりませんでした。そこで、どのようなアルゴリズムを実装すればよいかを考えました。 先に結論を言ってしまうと、そのようなbotの作成には至らず、質問する場所(ペパボではSlackのチャンネル)を教えてくれるbot、という完成度に留まっています…理由は後述します。
botの回答抽出アルゴリズムとして考えられるものは以下のようなものでした。
- 質疑表のような
質問:回答の組み合わせを持つデータを作成して、それに基づいて回答する 質問を裏で人が回答する- 機械学習を使って多値分類モデルを作成する
質疑表を作るというのはある意味理想的です。それがあれば質問者は質問する必要すらありません。それを見ればよいのです。答えが乗っているのですから。 ですが、そのような質疑表を作る膨大な労力を費やしたいとは思いません。なぜならその質疑表は近い将来更新が必要になるでしょうし、その度に質疑表を更新するコストを考えるととても作る気にはなりません。
そこで、今までの質疑がなされているチャンネルの会話履歴から多値分類モデルを作れないか?と考えました。
機械学習をするにあたって
さて、機械学習を何故選んだのかというところまでお話しましたが、機械学習をするにはいくつかのハードルが有ります。
- 教師あり学習をするのであれば膨大な教師データが必要になる
- 学習を行うに当たって、常時稼働できる高スペックな環境が欲しくなる
- 数学的な知識が必要になる
- エントロピー、プレースホルダーなど未知の領域
教師データが必要というハードルは、Slackには過去の会話履歴をexportする機能があるのでクリアできました。zipで1GBと少しのデータが得られ、学習に用いたデータはそのうち5MB程度のCSVになりました。 常時稼働できる高スペックな環境は、ペパボにはその手の開発支援環境が豊富なのでさくっと用意できました。GPUの搭載されたマシンの購入も検討してくれたのですが、作るものの難易度が高く達成できるか不安があったり、前述した教師データの件数的にもとりあえずはサーバのCPUで間に合いそうなので見送りました。 詳しい事は後述しますが、適当なサーバで1日回せば学習が終わっていました。
最後の数学的な知識が必要、という点が最も鬼門と言えるものでした。 私は数学ができません。高専卒なのですが、5年間テストの点が悪いがために先生の所に通いつめていた記憶があります。 機械学習を使う、という上でどのように機械学習を実現するかという決定をする必要があるのですが、最初はTensorFlowを使うことを考えました。 しかしTensorFlowのサンプルコードを見ていると、数式を繋げていくような印象を受けました。 これは厳しいと思いつつネットの海を泳いでいるとKerasというTensorFlowのラッパーを見つけました。
Kerasのサンプルコードを読み進めているうちにKerasを使おうという気持ちが高まり結果的にKerasを採用しました。 その理由について、次の節にて説明します。
なぜKerasを選んだのか
一言で軽く言ってしまうと、 ロジックをそのまま文章にしている かのようにコードをかける、という一言に尽きます。
例えばTensorFlowでCNNモデルを構築しようとすると下記のリンクのようなコードを書くことになります。これはTensorFlowの公式で用意されているMNISTのコードです。 tensorflow/mnist_deep.py at r1.2 · tensorflow/tensorflow
特に注目してほしいのは下記のコードです。
# First convolutional layer - maps one grayscale image to 32 feature maps.
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# Pooling layer - downsamples by 2X.
h_pool1 = max_pool_2x2(h_conv1)
# Second convolutional layer -- maps 32 feature maps to 64.
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# Second pooling layer.
h_pool2 = max_pool_2x2(h_conv2)
MNISTのコードは多数のサンプルが作られてきたディープラーニングのHello Worldのようなものですので冗長な表現が無く比較的わかりやすいのですが、それでもモデルのレイヤーを2つ重ねるためにこれだけのコードが必要です。 一方Kerasであれば、下記のようなコードを書くことが出来ます。
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
作っているニューラルネットワークのレイヤーがこちらの方が深いので行数はさほど変わりませんが、わかりやすくなっているように見えます。TensorFlowのコードでもある程度ニューラルネットワークの入門書などを呼んで、コメントを読めば何をしているのかは理解できると思いますが、Kerasはそれ以上にわかりやすくなっています。
多層パーセプトロンの構築において層を重ねるという操作を model.add という書き方ができるのでより直感的になっているのがお分かりいただけると思います。このようなわかりやすさからKerasを選びました。
成果
多少の紆余曲折はあったのですが、結果的にKerasを用いたbotの作成に成功しました。Slackでbotにメンションされた文章から、質問・依頼先となるチャンネルを推測してそのチャンネルへのリンクとスコアを返します。
例の画像を掲載します。例えば情報システムグループによく来るPCの調子が悪いよ〜というような問には #shasys とスコアを返してくれます。 #shasys と言うのはペパボの情報システムグループの問い合わせ窓口になっているチャンネルです。
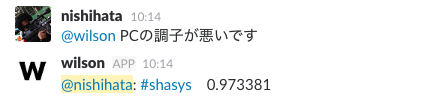
結構高いスコアを出していることもわかります。よく来る問い合わせの内容ですし、 #shasys 内ではPCという単語は山ほど飛んでいるというのも原因として上げられそうです。
これで最初の疑問についての答えがわかりましたね。
そして、他の問い合わせ・依頼先としてよくあげられる部門のチャンネルも答えてくれます。
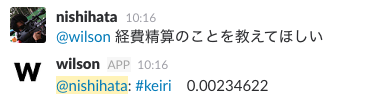
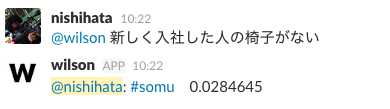

しかし、先程のPCの調子が悪いという問いと比べると随分スコアが低いです。私の作ったモデルが良くないという面もありそうですが、何より教師データの総数に問題がありそうでした。
ノイズ(例えばbotによる通知など)を取り除いた結果、#shasys で得られた教師データの数は2万と少し有るのですが、それに対して他のチャンネルでのデータ数は多くても6000件、少ないところだと3000件と少しでした。
精度が低くてもそれなりに分類することは出来ますが、精度を高めるためにはもう少し教師データの数が必要そうに見えますね。
実際にこのbotを使って問題が解決できた事例も多数あり、教師データでの正答率は80%ほどでした機械学習によるモデル評価としては正答率は低い、となるのですが助けにはなりそうです。
今後の課題
課題として考えているのはもちろん正答率の向上です。強化学習の仕組みを取り入れる、データのノイズを取り除くロジックを強化する、など様々なアプローチが有ります。
例えば、今このbotは単語と単語のつながりを意識しない学習をしています。したがって、 サーバー と ウォーターサーバー を違うものとして判断するようなことが出来ません。
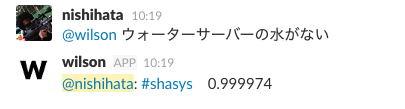
正しくは #somu を案内すべきですが、かなり高いスコアで #shasys を示しています。確かに経理や総務、人事などと比べると圧倒的にサーバーという単語は #shasys で登場しているのは容易に想像がつきます。
このような誤回答を減らす、というのが大まかな今後の目標だと考えています。
具体的には次のようなアプローチを考えています。
- 日々増えているSlackの会話履歴を教師データとして取り入れて学習する
- 強化学習を取り入れ学習精度を上げる仕組みを作る
- Slackを通して簡単にフィードバックを送れるようにする
教師データの更新は比較的簡単にできそうですが、残り2つが難易度が高そうです。しかし意義のあることであると考えられるので今後も取り組んでいこうと思います。



