
はじめに
minneでは、アプリでミッションを達成したり、広告を見ることでminneコインが無料で貯まる機能「minneリワード」をリリースしました。 minneリワードには昨年リリースされた作家・ブランドへの応援ミッションの他に、「アプリを起動する」「注目の特集をチェック」といったデイリーミッション、応援・購入回数に応じた累積ミッションが用意されています。ミッションを達成し動画広告を視聴すると、minneコインが付与される仕組みです。
【予告】お買い物がちょっとお得になる「minneリワード」が3月に登場✨
— minne byGMOペパボ(ミンネ) (@minnecom) February 20, 2026
アプリでミッションを達成し、広告を見るとコインがもらえます🎁
貯めたコインは、ポイントに交換してお買い物に使えます!… pic.twitter.com/xp955ifPQ9
本記事では、マルチクラウド構成でのゲーミフィケーション機能を実現するにあたっての設計判断と、実際に運用する上で直面した課題・解決策を紹介します。
- はじめに
- minneリワードの全体像
- クライアント起点の実績集計を採用しなかった理由
- なぜマルチクラウドになったのか
- 設計判断のポイント
- 累積ミッションの設計:新しいデータストアを作らない判断
- 見積もりと開発体制
- まとめ
minneリワードの全体像
minneリワードは、大きく二種類のミッションで構成されています。
- デイリーミッション: 毎日リセットされ、「アプリを起動する」「注目の特集をチェック」といったタスクをこなすと達成されるミッション
- 累積ミッション: 「作品を10回購入する」「応援スタンプを10回送る」のように、長期的な利用で達成されるミッション
ミッション達成後にユーザーが動画広告を視聴すると、minneコインが付与されます。このコインはminneでのお買い物に利用できるminneポイントに変換することができます。
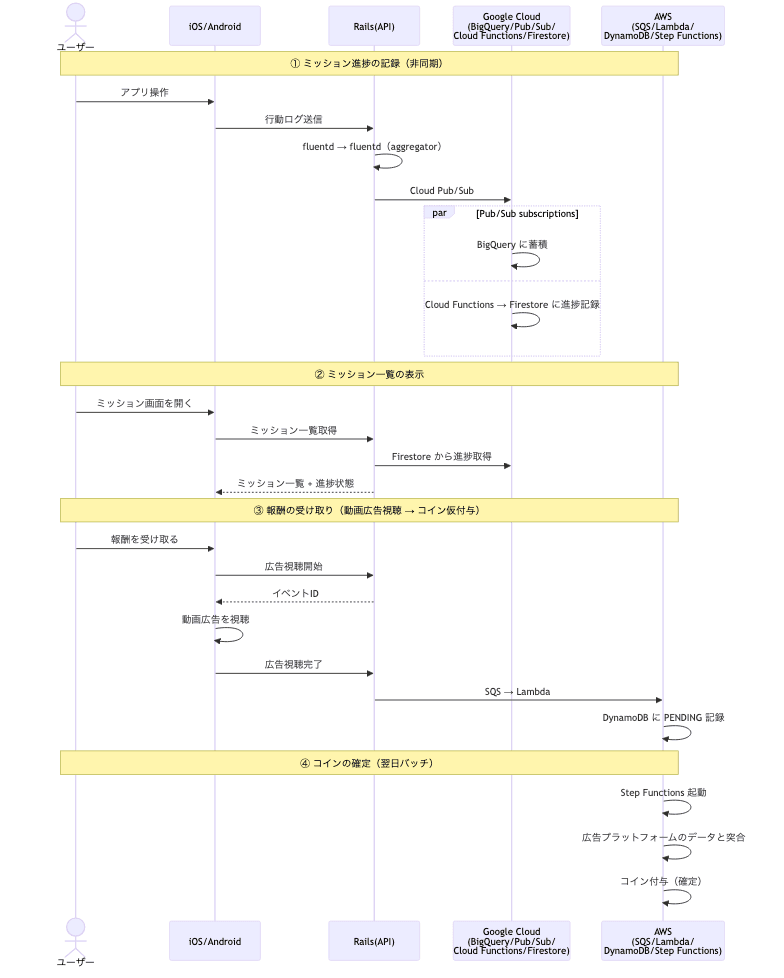
全体の処理は大きく4つのフェーズに分かれます。
- ミッション進捗の記録: ユーザーの行動ログをGC側で非同期にFirestoreへ記録
- ミッション一覧の表示: GraphQLクエリでFirestoreから進捗を取得しクライアントに返却
- 報酬の受け取り: 動画広告視聴後、AWS SQS経由でDynamoDBに達成の記録を作成
- コインの確定: バッチで広告配信元の視聴データと突合し、minneコインを付与
クライアント起点の実績集計を採用しなかった理由
当初、ミッションの進捗記録はクライアント(iOS/Android)起点で行う設計を検討していました。具体的には、ミッション達成条件を満たす行動が発生したタイミングで、クライアントからGraphQL APIを呼び出して実績をインクリメントする方式です。
しかし、この方式ではミッションを新たに追加するたびに、そのミッションの達成導線となる画面にAPIコールを仕込むクライアント側の改修が必要になります。例えば「特集から作品を見る」ミッションを追加するなら特集画面に、「新着作品を確認する」ミッションを追加するなら新着一覧画面に、それぞれAPI呼び出しのコードを追加してアプリをリリースしなければなりません。
minneリワードは今後もミッション種別を柔軟に追加・変更していきたい機能です。ミッションの追加のたびにクライアントの改修とアプリリリースが必要になる構成では、その機動性が大きく損なわれてしまいます。
この課題を踏まえて、実績集計をバックエンド側に閉じる方針に転換しました。それが次に説明するマルチクラウド構成の採用につながっています。
なぜマルチクラウドになったのか
minneのメインアプリケーションはAWS上のRuby on Railsで動作していますが、ミッション報酬機能ではGoogle Cloud(以下、GC)のFirestoreやCloud Functionsも組み合わせたマルチクラウド構成を採用しました。
minneではユーザーの行動ログを Railsアプリケーション → fluentd → fluentd(aggregator) → Cloud Pub/Sub のパイプラインで収集しています。このCloud Pub/Subに対してBigQueryへの蓄積用とCloud Functions用の2つのサブスクリプションを設定し、Cloud Functionsでミッション進捗をFirestoreに書き込む構成にしたことで、メインアプリケーションへの変更をほぼゼロにしながらデイリーミッションの進捗記録を実現しました。
[ユーザー行動]
↓
Railsアプリケーション → fluentd → fluentd(aggregator) → Cloud Pub/Sub → BigQuery
↓ (subscription)
Cloud Functions
↓
Firestore
(デイリーミッション進捗)
この設計には2つの大きなメリットがあります。まず、既存のRailsアプリケーションにミッション進捗記録のためのコードを追加する必要がなく、新機能のリリースが既存機能の安定性に影響を与えるリスクを最小限に抑えられます。さらに重要なのは、新しいミッションを追加する際にiOS/Androidのクライアント側の改修がほとんど不要になる点です。ミッションの実績集計はバックエンド側で完結するため、ミッション種別の追加はサーバーサイドの設定変更で対応でき、クライアントアプリのリリースサイクルに縛られません。
設計判断のポイント
1. Firestoreのドキュメント構造:ユーザー起点 vs 日付起点
デイリーミッションの進捗をFirestoreに格納する際、2つの構造を検討しました。
候補A:ユーザー起点(採用)
missions/{user_id}/dailyProgress/{YYYYMMDD}
候補B:日付起点(不採用)
dailyMissions/{date}/{user_id}
候補Bは日別の集計に便利ですが、同じ日付ドキュメント配下に全ユーザーの書き込みが集中します。Firestoreには書き込み数の制限があり、キャンペーン時などにDAUが跳ね上がるとボトルネックになり得ます。候補Aのユーザー起点であれば、各ユーザーのドキュメントへの書き込みが自然に分散されるため、こちらを採用しました。
2. DynamoDB GSIシャーディングによるホットパーティション回避
ミッションの達成状態はDynamoDBに格納しています。DynamoDBではパーティションキーを指定して効率的にデータを取得するQueryが基本であり、パーティションキーの設計がパフォーマンスを左右します。DynamoDBの基礎的な設計の考え方については、以前のテックブログ記事「DynamoDB設計で痛い目にあった話 – RDB脳から抜け出すための実践ガイド」で紹介していますので、あわせてご覧ください。
今回、「特定日にミッションを達成したユーザー一覧」を取得するためのGSI(Global Secondary Index)で、ホットパーティション問題が発生し得ます。
例えば、GSIのパーティションキーを acquired_at_date(日付)にすると、全ユーザーの書き込みがその日の1パーティションに集中してしまいます。
これを回避するため、パーティションキーにシャードサフィックスを付与しました。
パーティションキー: {YYYY-MM-DD}#{user_id % 10}
user_id % 10 で10個のシャードに分散させることで、1パーティションあたりの書き込み負荷を1/10に軽減しています。読み取り時は10シャード分をScatterGatherで取得する必要がありますが、日次バッチ処理でしか使わないため許容範囲です。
3. SQSを介した非同期書き込み
DynamoDBへの書き込みは、Railsアプリケーションから直接行うのではなく、SQSキューを経由してLambdaで処理する構成にしました。
[Rails] → SQS → Lambda → DynamoDB
これは既存の応援スタンプ機能で実績のあるパターンを踏襲したものです。メリットは以下のとおりです。
- Railsのリクエスト処理とDynamoDBの書き込みを分離し、レイテンシのスパイクを防ぐ
- DynamoDBのスロットリングが発生してもSQSがバッファとして機能し、リトライが自動で行われる
- ミッション達成時のトラフィックスパイクからメインアプリケーションを保護する
4. 2フェーズコイン付与による不正防止
コインの付与は、即時に仮付与→翌日に本付与という2フェーズで行っています。
[ミッション達成 + 動画広告視聴]
↓
DynamoDB に PENDING 状態で記録(仮付与)
↓ (翌日 18:00 JST)
広告配信元から取得した広告視聴レポート(CSV)と突合
↓
一致 → コイン付与(本付与)
不一致 → 付与をスキップ
動画広告の視聴完了をクライアント側の報告だけで信用すると、不正にコインを取得される可能性があります。広告プラットフォーム側が独立に生成するCSVレポートと突合することで、広告が実際に視聴されたことを第三者データで検証しています。
この突合処理はAWS Step Functionsでオーケストレーションしており、CSV取得→突合→コイン付与という一連のバッチ処理を管理しています。
5. GraphQLにおけるインターフェース分離パターン
ミッション情報のGraphQLスキーマでは、認証状態に応じて返すフィールドを変えるためにInterface + Typeの分離パターンを採用しました。
interface Mission {
id: ID!
title: String!
description: String!
rewardCoins: Int!
}
type OwnMission implements Mission {
# Missionの全フィールド + 進捗情報
currentCount: Int!
status: MissionStatus!
}
type GuestMission implements Mission {
# Missionの定義情報のみ
}
クライアント側はインラインフラグメントで認証時だけ進捗情報を取得できます。
query {
missions {
... on OwnMission {
currentCount
status
}
}
}
フィールドレベルの認可ディレクティブ(@auth など)を使う方法も検討しましたが、型レベルで分離するこのパターンを採用しました。理由は以下のとおりです。
- 要件との整合: ログインしていないユーザーにもミッション一覧は見せたい(認知→ログイン促進)ため、認証状態によって返す情報の粒度を明確に分けられる
- フィールド乖離への耐性: 今後ログイン・非ログインで必要なフィールドの差が広がっていくことが想定される中、型が分かれていれば各型に独立してフィールドを追加でき、
@authディレクティブの付け忘れといった事故も起きない - クライアント側の型安全性: インラインフラグメントにより、クライアントのコード生成で
OwnMissionとGuestMissionが別の型として扱われるため、認証状態に応じたハンドリングがコンパイル時に保証される
累積ミッションの設計:新しいデータストアを作らない判断
累積ミッション(購入回数、応援スタンプ送信回数)については、デイリーミッションのようにFirestoreに進捗を記録する方式をあえて採用しませんでした。
代わりに、既存のデータソースを直接参照しています。
- 購入回数: RDBのテーブルからDISTINCTカウント
- 応援スタンプ回数: Lambda経由でDynamoDBの応援スタンプデータを集計
ここでのポイントは、データの出自に応じてストアを使い分けるという考え方です。
- デイリーミッションの進捗は、行動ログとしてフローで流れてくるデータをPub/Sub経由でFirestoreに集約する設計が自然
- 購入回数はすでにRDBのテーブルに蓄積されているため、そこから集計すればよい
- 応援スタンプ回数もDynamoDBにレコードが溜まっているため、そこから集計すればよい
つまり、既存のデータストアにすでに集計可能な形でデータが存在しているなら、わざわざFirestoreに二重に持つ必要はありません。もちろん処理の統一性を優先して、累積ミッションの進捗もFirestoreにインポートして管理することも考えましたが、SSoTの原則から今回はそれぞれ既存のデータを参照する形式を採用しました。
見積もりと開発体制
本機能は、インフラ・API・Lambdaを2名、iOS・Androidをそれぞれ1名ずつの計4名体制で約3〜4週間で実装しました。
行動ログベースの進捗記録をGC側に寄せ、実績の集計をバックエンドに閉じたことで、ミッションの追加時にクライアント(iOS/Android)側の工数がほとんどかかりません。ミッション種別のスケーラビリティを確保できた点が、この構成の大きな成果です。
まとめ
ミッション報酬機能の開発を通じて得た学びをまとめます。
- 実績集計をバックエンドに閉じたことでミッション追加がスケーラブルに: 行動ログベースの進捗記録はGC側で、既存データの集計はバックエンドで完結させたことで、新しいミッションを追加してもiOS/Android側の改修がほとんど不要になった
- データストアは要件に合わせて使い分ける: デイリーミッションにはFirestore、報酬状態にはDynamoDB、累積データはRDB/既存Lambdaと、特性に応じたストア選択が運用負荷の低減につながった
- 書き込み分散の設計は初期に行う: FirestoreのドキュメントモデルやDynamoDBのGSIシャーディングなど、ホットパーティション対策は後から変更しにくいため、初期設計で考慮しておくことが重要
マルチクラウド構成でのゲーミフィケーション機能の設計を検討されている方の参考になれば幸いです。



