セキュリティ対策室のn01e0です。
この記事では、セキュリティ対策室で私がAI(広義)をどのように活用しているかを紹介します。
Attack Surface Managementの自動化から、機械学習による異常検知、AIエージェントを活用した脆弱性診断まで、私の業務の各領域でAIが前提となりつつある現状をお伝えします。
PASM (Pepabo Attack Surface Management)
PASMはPepabo Attack Surface Managementの略称で、独自のスキャナとShodanなどの外部ソースからの情報収集を組み合わせ、Attack Surfaceの把握と管理を行うプロジェクトです。
スキャナはECS Fargate(Spot)上で稼働しており、Rustで書かれたバイナリをstatic linkでビルドしてscratchコンテナに載せています。コンテナサイズはわずか6.7MBで、1日あたりの実行コストは合計で約50円です(Shodan APIの方が圧倒的に高いです)。
スキャンは主にドメインを対象として実行しており、対象ドメインはAWSやCertificate Transparency、社内DNSから自動収集しています。監視対象のドメインは4,000件以上にのぼります。
主な検出項目として、意図せず公開されているエンドポイントの検出、Subdomain Takeoverリスクの検出、証明書の有効期限監視、WAFの動作確認、HTTPレスポンスヘッダからの情報漏洩検出などがあります。
scratchコンテナで動くRustスキャナ
PASMのコンテナイメージのベースはscratchです。scratchにはlibc、shはもちろん、/etc/hostsすら存在しないため、多くのアプリケーションはそのままでは動きません。これを実現するために以下の工夫をしています。
まず、ビルド時にx86_64-unknown-linux-muslターゲットでRUSTFLAGS="-C target-feature=+crt-static"を指定し、musl libcを含むすべての依存を静的リンクします。DNS解決については、libcのgetaddrinfoに依存しないPure RustのDNSリゾルバであるhickory-resolverを使用しています。これにより、/etc/resolv.confも不要で、シングルバイナリで名前解決まで可能になります。
さらに、リリースビルドではサイズの最小化を徹底しています。
[profile.release]
opt-level = "z"
lto = true
strip = true
panic = 'abort'
codegen-units = 1
opt-level = "z"でサイズ優先の最適化、LTOでリンク時最適化、シンボルのstrip、panicをabortにしてunwind用のコードを除去、codegen-units = 1でコンパイル単位を1つにまとめてさらなる最適化を可能にしています。この結果、4,000件以上のドメインを高速にスキャンするバイナリと設定ファイルが6.7MBのコンテナに収まっています。
ドメインの自動収集
監視対象のドメインは手動管理ではなく、複数のソースから自動収集しています。
最大のソースはAWS Route53で、ペパボが管理する14以上のAWSアカウント(division)からDNSレコードを定期的に取得しています。基盤チームが管理するdivisionは変更頻度が高いため毎時更新、その他は日次で更新しています。
取得したRoute53のRecordSets JSONは、Rustで書かれたfilterバイナリに渡されます。filterはA/CNAMEレコードのみを対象とし、以下のフィルタを優先順位順に適用します。
- ワイルドカードレコード(
*.example.com)の除外 - 無視パターン(正規表現)による除外
- サービス固有の除外(ユーザに提供しているサブドメインなど)
- 既存の監視対象との重複チェック
どのフィルタにもマッチしなかった(監視除外対象でない)ドメインは、Public Suffix Listを拡張したPepabo Suffix Listを使ってサービスに振り分けられ、サービスごとのYAMLファイルに追記されます。
Certificate Transparencyからの収集では、crt.shのAPIを通じてSSL証明書のCN(Common Name)とSAN(Subject Alternative Name)を抽出し、新しいサブドメインを発見しています。
これらの収集パイプラインはGitHub Actionsで自動化されており、新規ドメインが発見されるとPRが作成され、レビュー後にスキャン対象に追加される仕組みです。
AI x Rust
PASMのスキャナはRustで実装していますが、AIはRustを書くのが基本的に上手です。以下の点さえ注意して指示すれば、良い実装を出してくれます。
- 古いcrateを使いがち
- 古いeditionを使いがち
- 古いパターン(
mod.rs)で書きがち
型システムの強さとテストのしやすさが仕様の担保に役立っていると考えています。Rustは所有権やライフタイムといった概念が独特で学習コストの高さが課題とされてきました(本質的に難しいのはプログラミングそのものであり、Rustではないという意見もあり、私はその意見を支持しています)が、AIの登場によってその障壁は大幅に下がりました。
AIが生成したコードはコンパイラがチェックしてくれるため、「コンパイルが通ればおおむね正しい」というRustの特性がAIとの協業と非常に相性が良いと感じています。ただAI以前からRustが好きなのでバイアスはかかっていると思います。コンパイルが遅いことはデメリットですが。
Agentic ML
令和最新版「ビッグデータをエーアイで良い感じに」
ShodanのAPIで保有IPレンジのデータを取得・モニタリングしています。
ShodanにはAlertという機能があり、指定したIPやCIDR、ドメインのイベント(ポート変更など)を通知してくれる仕組みを使っています。
また、Search APIを利用することで指定したホストのスキャン結果を得られますが、以下の問題を抱えています。
- データが不安定(UDPなど一部のポートは検出できたりできなかったりするような挙動があり、ポートが開閉してるように見える)
- IPが多すぎるため情報量も膨大
- 15,000以上のIP
- サービスや社内利用のIPだけでなく、ホスティング商材としてユーザが使用しているIPも含まれる
これらの課題に対して、AIエージェントと共にパイプラインを構築しました。モデルの選定は、目的と手元にあるデータの特性をもとに、エージェントと議論しつつペパボ研究所の三宅さんにもアドバイスをもらいながら進めました。
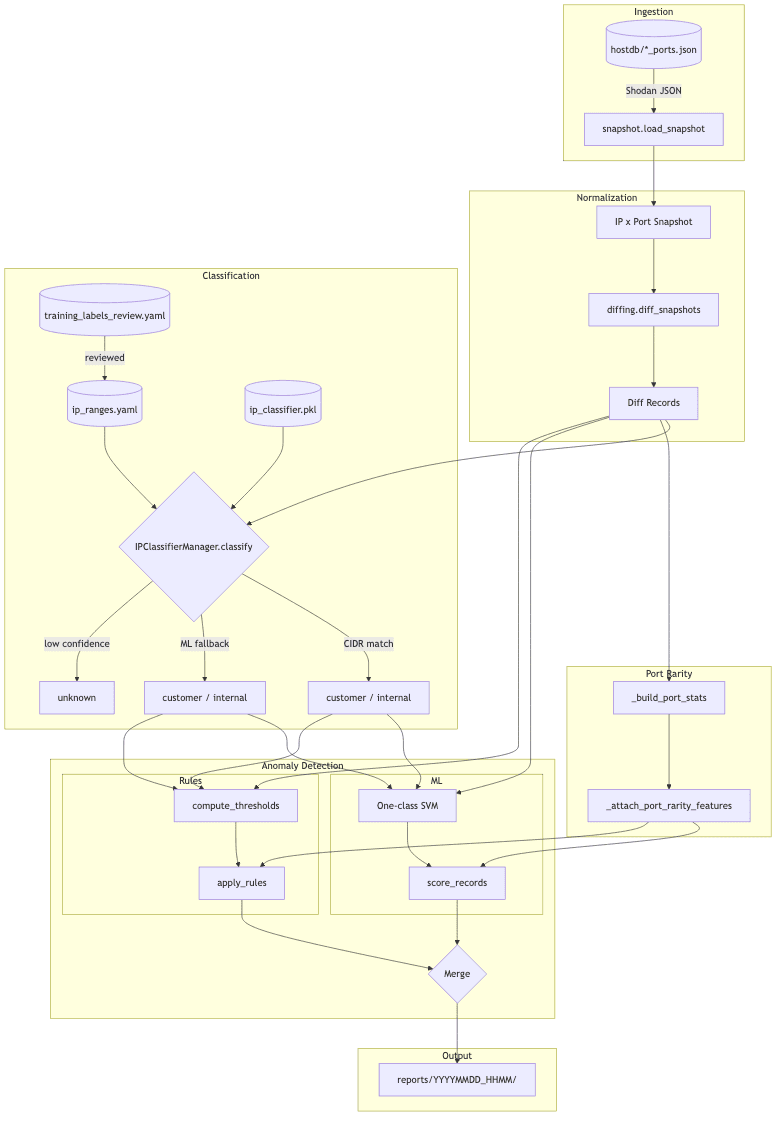
データの正規化とgit管理
Shodan APIが返すJSONはホストごとに非常に大きく、バナー情報やHTML本文、証明書チェーンの全体などノイズが多いデータ、サイズが大きすぎるデータも大量に含まれています。これをそのままgit管理すると容量が膨大になるため、APIから取得したJSONをポートごとにいくつかの特徴量に必要なフィールドに絞り込んでからhostdb/*_ports.jsonとしてgitで履歴管理しています。
Shodanデータの可視化・クエリ基盤
正規化したとはいえ、この規模のデータを人間が直接読んで分析するのは現実的ではありません。MetabaseやRedashのようなBIツールを立てる選択肢もありますが、利用者が限られる中でインフラを維持するのは割に合いません。そこで、ブラウザ上でSQLクエリを実行できる分析基盤をAIと一緒に構築しました。
DuckDB WASMを使い、hostdb/のJSONをブラウザ上でパースしてテーブルに投入し、SQLで分析します。バックエンドサーバが不要なため運用コストが非常に小さいです。
時系列分析にはgitのコミット履歴を活用しています。hostdb/の各コミットからスナップショットを生成し、pasm_historyテーブルとしてロードすることで、ポートの増減やサービス構成の変化をSQLで追えるようにしています。大規模な履歴データはビルド時にgzip圧縮し、ブラウザ側でストリーミング展開・バッチ挿入することでメモリ消費を抑えています。
また、HTTPタイトル、SSL証明書のフィンガープリント、ホスト名パターンなどを組み合わせたサービスマイグレーション検出も組み込んでおり、IPが別のサービスに移動した場合を追跡できます。リスク分析、脆弱性一覧、ポートサマリなどのプリセットクエリに加え、自由にSQLを書いて分析することも可能です。
スナップショットの差分抽出
解析時には各コミットのJSONをパースし、IP × ポートの状態を正規化したスナップショットを生成し、2つの時点のスナップショットの差分からIPごとに以下の差分特徴量を生成します。
- ポートの増減(新規・削除・変更)
- サービス情報の変化(product/versionの変更回数)
- SSL証明書の変更回数
- HTTPステータスの変化
- 変化率(
total_change_count / max(prev_port_count, curr_port_count, 1)) - etc…
これらを合わせた21の特徴量が、後段の分類・異常検知の入力となります。
IPの分類
15,000以上のIPには、自社サービスのIP、社内利用のIP、そしてホスティング商材のユーザが利用するIPが混在しています。異常検知の精度を上げるには、IPがcustomer(ユーザ利用)かinternal(自社管理)かを正しく分類する必要があります。
分類は3段階のフォールバック構造です。
- CIDRレンジによる静的マッチ —
ip_ranges.yamlに定義されたCIDRレンジで最長一致。確実に分類できるIPはここで決まる - MLによる分類 — CIDRで判定できないIPに対して、RandomForest + XGBoostのアンサンブルモデルで分類する。ポートの構成パターン、Webサーバの種類、SSL証明書の特徴(Let’s Encrypt率、商用CA率)、HTMLハッシュのシグネチャなど50以上の特徴量を使用し、SelectKBestで30に絞り込む
- unknown — MLの確信度が閾値に満たない場合はunknownとする
ポートの希少性スコア
新しく開いたポートが「珍しいもの」かどうかを定量化するために、カテゴリ内での出現頻度から-log10(frequency / total)で希少性スコアを算出しています。同じカテゴリ内で過去に一度も観測されていないポートが開いた場合、new_port_unseen_countとして強い異常シグナルになります。
customer IPについてはこの希少ポートのみに着目したrare_change_rateを、internal IPについてはSNMP(161番ポート)のようなノイズの多いポートを除外したfiltered_change_rateを、それぞれの異常検知に用います。
異常検知
異常検知はMLとルールベースのハイブリッドです。
One-Class SVM はカテゴリ(customer / internal)ごとに個別のモデルを学習します。連続値の特徴量にはRBFカーネル、boolean特徴量にはHamming類似度を組み合わせたハイブリッドカーネルを使用しています。decision_functionのスコアが低いほど異常度が高く、customer IPについてはchange_rateが低い場合に異常判定を抑制するルールも組み込んでいます。
ルールベース はパーセンタイル閾値による検出です。たとえば変化率が90パーセンタイルを超えた場合や、過去に観測されていないポートが新たに開いた場合にスコアを加算します。閾値は訓練データから動的に算出されるため、データの分布が変わっても追従します。
両者のスコアをマージし、最終的な異常フラグを決定します。customerはルールスコアの閾値を高めに設定し、ノイズの多さに対応しています。
Human-in-the-Loop
IP分類の精度はパイプライン全体の精度に直結します。これを継続的に改善するため、以下のサイクルを回しています。
- ヒューリスティックによるラベル自動生成 — Shodanのメタデータ(HTMLハッシュ、SSL証明書のパターン、ホスト名、ポート構成)からcustomer/internalのスコアリングを行い、
training_labels_review.yamlに出力 - 人間によるレビュー — 自動生成されたラベルを確認し、
pending_reviewからapprovedに変更 - モデルの再学習 — approvedラベルを使ってRandomForest + XGBoostを再学習
- 差分レビュー — MLの分類結果とCIDRの分類結果が異なるIPを対話的にレビューし、正しい分類を
/32エントリとしてip_ranges.yamlに追加
1ヶ月ほどこのサイクルを回したところで、ラベルの網羅性が上がり、本来の目的である異常検知も良い精度で機能するようになりました。
MLは過渡的な手段
ここで重要なのは、人間のタスクをAIで置き換えて終わりではないという点です。最終的なゴールはプログラムによる完全な自動化です。Human-in-the-Loopのサイクルを回し続けることでip_ranges.yamlのCIDRエントリが充実していけば、MLによる分類のフォールバックは不要になります。異常検知についても、ルールの閾値が十分にチューニングされればOne-Class SVMは外せます。つまりMLは、ルールを確立するまでの過渡的な手段です。
MLのクオリティはさておき、エージェントの登場によって目的に対する手段の選択肢が増えたことが大きな変化です。今までは自分が持っている武器しか使えませんでしたが、今ではあらゆる選択肢から最適なものを選べます(最適なものを選ぶ能力は別途必要ですが)。
Agenticな脆弱性診断 (Unravelling)
人間の脆弱性診断フローを落とし込む
脆弱性診断の民主化を目指し、Unravellingというツールセットを開発しています。誰がやっても同じような結果が得られること、誰でもできることが目標です。完全な内製化ではなく、SASTの拡張・DASTの代替という位置づけです。
このツールはClaude Code/Codex CLIのスキルシステム上に構築されており、13のスキル定義が9フェーズの診断パイプラインを駆動します。Playwright MCPでブラウザ操作を行い、ローカルで環境を構築するとコンテナに入ってMFA含むユーザ登録まで自動で行います。
LLMに任せる部分とスクリプトに任せる部分
実装上の特徴は、診断の本体(脆弱性の探索・検証・レビュー)にはプロンプトによるアプローチだけを使い、決定的に実行できる部分はスクリプトに分離していることです。
セットアップ(bin/setupによるPlaywright MCPの登録やCLIインストール、unravelling-initによる対象リポジトリの初期化)、トリアージ(unravelling-triage)、レポート生成(unravelling-report)はRuby/Bashスクリプトで実装しています。これらは毎回同じ結果を返せばよいので、LLMを通す必要がありません。
一方、脆弱性の探索や検証はコンテキストに依存する判断の連続であり、ここにはSkillsのプロンプト設計を通じてモデルの能力を引き出すアプローチを取っています。
これは私個人の設計思想ですが、FN(見逃し)やFP(誤検知)の削減に寄与する要素を分解すると、最も支配的なのはモデル自体の性能だと考えています。自前でハーネスや診断ツールを作り込んでも、モデルが賢くなれば陳腐化しますし、モデルが対応できない領域をハーネスで補おうとするとメンテナンスコストが継続的に発生します。であれば、モデルの進化に乗る形でSkillsの設計に集中し、モデルの能力を最大限引き出す方が長期的に見て合理的だと考えています。
診断フロー
アカウント情報と対象のソースコードを与えると、以下のフローで診断を実行します。各フェーズの完了状態はscan_state.jsonで追跡されるため、途中で中断しても安全に再開できます。フェーズごとにキー(login, discovery, scope, threat_model, candidates, dedupe, verify, grouping, report)が記録され、再実行時には完了済みフェーズを自動でスキップします。
Phase 1: ログイン・セッション確立 — Playwright MCPで各アカウントにログインし、Cookieを抽出します。以降のフェーズではこのセッション情報を使い回します。診断中にセッションが切れた場合(401/403、ログインページへのリダイレクト、レスポンスにログインフォームが含まれる場合)は、自動で再ログインして継続します。
Phase 2: エンドポイント探索 — 2つのアプローチを組み合わせます。まずソースコードからフレームワークのルーティング定義を解析してエンドポイントを抽出します。Rails、Django、Laravel、Spring、Gin、FastAPI、Express等の主要フレームワークに対応しています。次にPlaywrightでリンクを辿りフォームを送信しながらネットワークトラフィックをキャプチャします。ここで重要なのは、各リクエストの実際のパラメータ(名前、位置、値、推定型)をsample_requestsとして記録することです。このサンプルリクエストが後段のGrayboxエージェントにとって「実際のトラフィックがどう見えるか」の基準となります。両者をマージ・重複排除してendpoints.jsonに出力します。
Phase 2.5: スコープ設定 — 対話を通じて診断範囲を決定します。3つのモードがあります。
- ブランチdiffモード —
git diff main...HEADで変更ファイルを特定し、変更されたハンドラと、そのハンドラが依存するモデル・サービス層の変更から影響を受けるエンドポイントを自動特定します。機能ブランチの開発中に差分だけ診断したい場合に使います - パス手動指定モード — 特定のパス配下だけを対象にします
- フルスキャンモード — 全エンドポイントを対象にします
どのモードでもexcludes(除外パス)とcontext(エンドポイントごとのテスト方針)を設定できます。たとえば/adminに対して「管理者用。操作の制限はゆるくして良いが、アクセス制限やXSS対策は厳しく確認する」というコンテキストを付与すると、後段のWhitebox/Grayboxエージェントがこの方針を考慮して診断します。
Phase 3: 脅威モデリング — STRIDE(Spoofing, Tampering, Repudiation, Information Disclosure, DoS, Elevation of Privilege)に基づき、資産、アクター、データフロー、信頼境界を特定したうえで、エンドポイントごとの脅威を列挙します。この結果は後段のWhitebox/Grayboxエージェントが診断の優先順位付けに使用しますが、テスト範囲を制限するものではありません。脅威モデルにない脆弱性も検出対象です。
Phase 4: 脆弱性探索 — 各エンドポイントに対して、WhiteboxとGrayboxの2つのSubagentを同時に起動します(並列数は設定可能)。全エージェントの完了を必ず待ちます。完了後にカバレッジチェックを行い、出力ファイルが欠落しているエンドポイントがあれば再起動します。
Phase 5: 重複排除 — Whitebox/Grayboxの検出結果を意味的に統合します。たとえば「CSRF保護なし」と「CSRFトークン未検証」は同一の脆弱性として扱います。Grayboxの動的な証拠を持つ方を優先的に代表として選出します。
Phase 6: 再現確認 — 候補ごとに検証エージェントを起動し、独立した手順で再現を試みます。検証エージェントは元のエージェントの説明を鵜呑みにせず、自分でソースコードを読み直してから検証アプローチを設計します。失敗した場合はレスポンスとコードを分析し、防御の見落としやアプローチの誤りを特定してリトライします(最大3回)。XSSやOpen Redirectについては、curlのレスポンスだけでは判断できないため、Playwrightでブラウザ上のDOM状態やスクリプト実行を確認します。再現できなかった場合は、何を試して何が起きたかをunconfirmed_reasonに詳細に記録します。
Phase 7: グルーピング — 再現確認済みの検出結果を脆弱性カテゴリごとに集約します。confirmed(再現成功)とunconfirmed(再現未了)を分離し、レポートの構造を形成します。
Phase 8: 懐疑的レビュー — グループごとに懐疑的なレビューエージェントを起動します。このエージェントは意図的に敵対的な立場を取り、「この検出は間違っている」という前提でソースコードを読み直します。フレームワークのデフォルト防御(RailsのCSRF保護やActiveRecordのパラメータ化クエリ、DjangoのCSRFミドルウェアやテンプレートの自動エスケープなど)、ミドルウェア、CSPなど、元のエージェントが見落とした防御策がないかを検証します。confirmed/likely/severity_overestimated/severity_underestimated/unlikely/false_positiveの6段階で判定を下します。
WhiteboxとGraybox
2種類のエージェントは相補的な役割を持ちます。
Whitebox はソースコードの構造分析に特化しています。リクエストは送信しません。まずPhase 0として、脅威モデルとスコープのコンテキストを参照し、このエンドポイントで起こりうる脅威を列挙します。次にPhase 1で、フレームワークのセキュリティデフォルトやグローバル設定、他のエンドポイントで使われている共通パターンをベースラインとして把握します。Phase 2で対象エンドポイントのコードパス(ルーティング→ミドルウェア→ハンドラ→モデル→レスポンス)を分析し、ベースラインからの逸脱を検出します。
具体的に見ているのは、ミドルウェアや設定の欠落、認可モデルの不整合(他のエンドポイントではcurrent_user.organization.usersでスコープしているのにこのエンドポイントだけUser.find(params[:id]))、データ露出(レスポンスシリアライザが意図しないフィールドを返す)、クロスエンドポイントのデータフロー(書き込み時にサニタイズされたデータが読み取り時にraw/html_safeで出力される)、依存ライブラリの危険な使用法などです。
出力にはコードの場所(file:line)、問題のスニペット、正しいパターンとの比較、そして検証エージェントが使うtest_focus(「account2のセッションでaccount1のリソースIDを指定してPUTし、更新が成功するか確認」のような具体的な指示)を含めます。
Graybox はソースコードを読んだうえで、実際にリクエストを送信して脆弱性を実証します。同じくPhase 0で脅威を列挙した後、Phase 1でリクエストのライフサイクルを追跡し、ユーザ入力がどこで消費されるか(SQLクエリ、シェルコマンド、ファイルパス、テンプレートレンダリング、正規表現、デシリアライゼーション)を特定します。各シンクに対する防御(ORMのパラメータ化、テンプレートの自動エスケープ、明示的なバリデーション)も確認します。
Phase 2で、コード分析に基づいた仮説駆動のテストを実行します。インジェクション系はコンテキスト固有のペイロード(SQLのシングルクォートを脱出する、HTMLの属性値を閉じるなど)を設計します。アクセス制御はセカンダリアカウントを使ったクロスアカウントIDOR、未認証アクセス、権限昇格をテストします。ビジネスロジックは状態遷移の不正操作、数値のマイナス値・オーバーフロー、競合状態(並行リクエスト10本)を確認します。
sample_requestsが存在する場合はそれをベースラインとし、テスト対象のパラメータだけを変異させます。これにより、Content-Typeやリクエスト構造の不整合による偽の検出を防ぎます。SSRFやBlind XSSの検証にはローカルのDockerネットワーク内にコールバックサーバを立てて確認します。
この二重構造により、Whiteboxが「あるべき防御が欠けている」という視点から、Grayboxが「実際に攻撃が成立する」という視点から、それぞれ脆弱性を捉えます。
トリアージと修正
診断結果のトリアージにはunravelling-triageというCLIツールを使います。LLMを使わない純粋なRubyスクリプトで、Token消費なしで対話的にトリアージできます。各findingに対して承認・重大度変更・偽陽性・保留の判定を行い、結果はtriage.jsonに保存されます。
修正は/fixスキルで1件ずつ行います。git worktreeで隔離されたブランチを作成し、修正を実装、回帰テスト(元の脆弱性が再現しないことを確認)を経てPRを作成します。1件完了ごとに会話が終了するため、コンテキストの消費を抑えます。人間が手動で修正した場合は/resolveで対応を記録し、自動で回帰テストと修正差分の妥当性検証が実行されます。
False Negativeが増えるくらいならFalse Positiveを許容する
既存の多くの脆弱性診断自動化ツールではFalse Positive(誤検知)の低さが重視されます。報告書に誤検知が多いとツールの信頼性に関わるからです。一方、内製のツールではFalse Positiveはトリアージで除外すれば済む(トリアージ作業自体もAIによって効率化できる)ため、見逃し(False Negative)を減らす方が重要だと考えました。
この設計思想はツール全体に反映されています。検出の段階では感度を高く保ち、その後の再現確認と懐疑的レビューで精度を上げていく構造です。もちろんトリアージの過程でAgentとの対話により精度を高めることも可能です。
なお、Token消費量は診断対象の規模やエンドポイント数に大きく依存しますが、参考値として研修用に作成したやられアプリを対象にフルスキャンした際は約$100分のTokenを消費しました。
結果として、私に回ってくる診断はAIでは見つけられないような脆弱性を探すものになりました。AIがカバーできる範囲が広がるほど、人間にはより高度な判断が求められるようになっています。
まとめ
セキュリティ対策室のエンジニアは3名で、社内での脆弱性診断はこれまで主に私一人で対応することが多くなっていました。この記事で紹介したPASMとそれに付随するAgentic ML、診断の為のUnravellingは、いずれもこの体制の中で生まれたものです。
私の目標は私の仕事を無くすことです。セキュリティ業務の属人化を排除し、全てを自動でもしくは半自動で誰でも行えるようにすることがセキュリティの向上に繋がると考えています。AIが効いているのは、ベースラインの向上と専門性の民主化、そして属人化の排除という面です。PASMではAIがRustの学習障壁を下げることで高速で堅牢なスキャナの継続的な開発を可能にし、Agentic MLでは機械学習という自分の専門外の武器を手に入れ、Unravellingでは一人では到底回しきれなかった診断を誰でも実行できる形にしました。これまで私の頭の中にしかなかった診断の観点や判断基準がSkillsのプロンプトとして明文化されたことで、私が手を動かさなくても一定水準の診断が回るようになりました。
AIの検出精度が専門家に及ばないことは承知しています。しかし、専門家が手を回せずに診断されないままリリースされるよりも、AIによる診断が走っている方が確実に良い結果をもたらします。100点の診断を1件やるよりも、70点の診断を10件回す方が、組織全体のセキュリティレベルは上がります。
ただし、AIはあくまで手段であって目的ではありません。AIにタスクを実行させることは、自動化とは呼べないと考えています。AIは確率的に動作し、同じ入力に対して同じ出力を返す保証がありません。真の自動化とは、プログラマティックに、決定的に動作するシステムによる解決です。Agentic MLのセクションで「MLは過渡的な手段」と書いたのはまさにこの思想からで、Human-in-the-Loopで知識を蓄積し、最終的にはルールベースのプログラムに落とし込むことがゴールです。AIは、そのゴールに至るまでの道のりを大幅に短縮してくれる存在です。
3人のチームでもカバーできる範囲が大きく変わったのは事実ですが、それで満足するつもりはありません。私の仕事がプログラムに置き換わり、私がいなくても回る状態を作ること。それが、AIを前提としたセキュリティ対策室の目指す姿です。