こんにちは、技術部データ基盤チームの zaimy です。
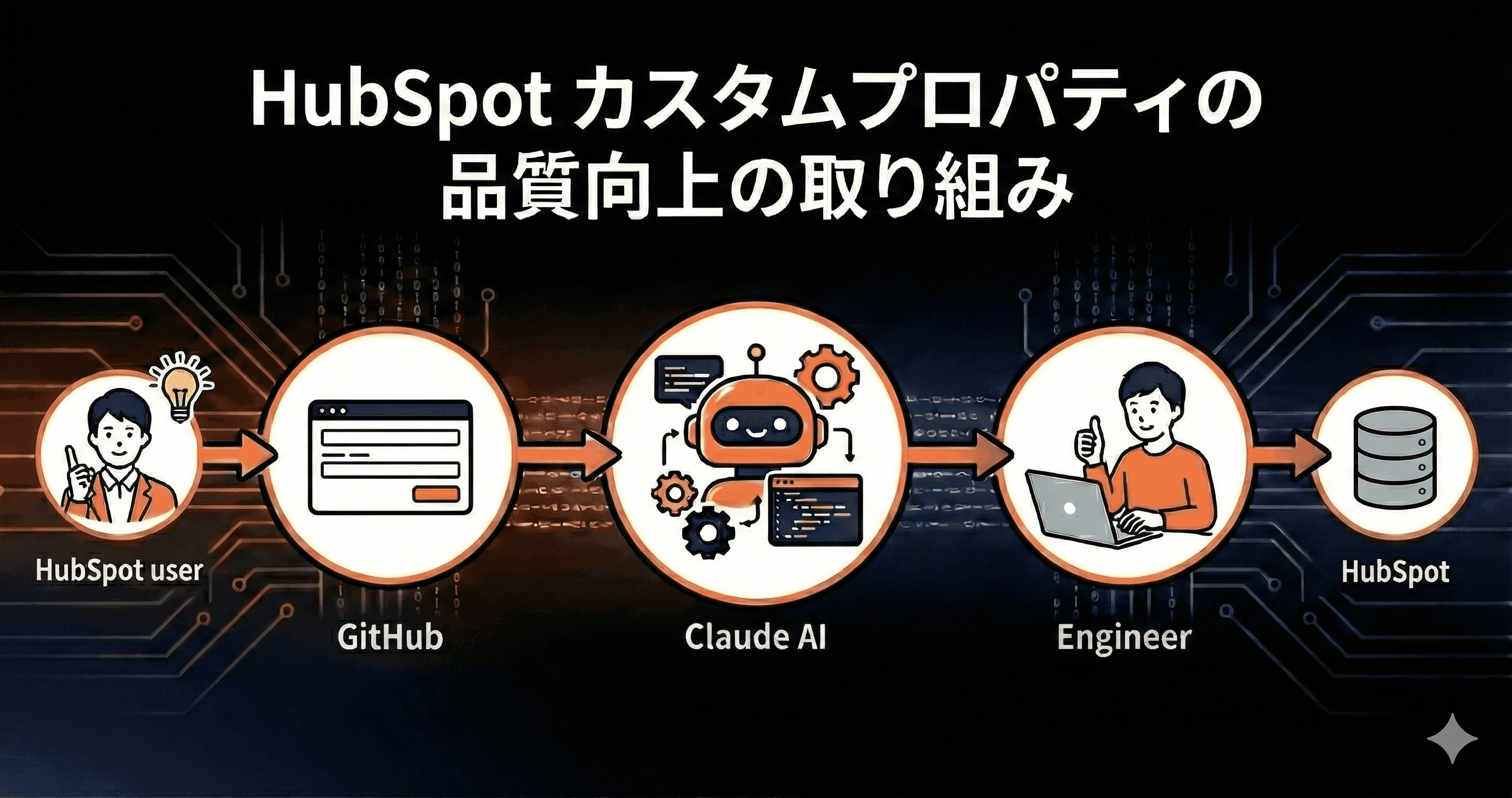
今回は、GitHubのIssue TemplateとClaudeを組み合わせて、HubSpotユーザーが作成するカスタムプロパティに対してエンジニアレビューを挟むことによる、データ品質向上の取り組みについて紹介します。
背景:データ設計の課題
ペパボでは営業活動やカスタマーサポートのためにHubSpotを利用しています。HubSpotは営業管理やマーケティングに使われるSaaSで、ノーコードツールとしてカスタムプロパティ(RDBのカラムに相当)を自由に作成できます。
この自由度の高さは便利な反面、営業やマーケティング担当者が業務上必要なプロパティを自由に作成した結果、データ利用に問題が生じていました。
- 命名規則がバラバラ(英語/日本語ローマ字、スネークケース/キャメルケース、prefixの有無が混在)
- データ型と値の指定が不適切(例:bool を意図した
true/noのような値が存在) - 同じ意味のプロパティが複数存在
- 用途が不明なプロパティが存在
これらの問題により、HubSpotのデータをBigQueryにロードしてもデータクレンジングなしには種々の施策に使えず、データクレンジングそのものが困難なことすらある状態でした。
解決策:GitHub Issue Template + Claudeによる設計の提案とエンジニアによるレビューフロー
この問題を解決するため、以下のような仕組みを構築しました。
- HubSpotユーザーがGitHubのIssue Templateに沿ってカスタムプロパティ作成を申請
- GitHub ActionsがClaudeを自動実行し、HubSpotの公式ドキュメントと既存プロパティを参照して設定値を提案
- データエンジニアがレビュー
- レビュー承認後、HubSpotユーザーがカスタムプロパティを作成
1. Issue Templateの設計
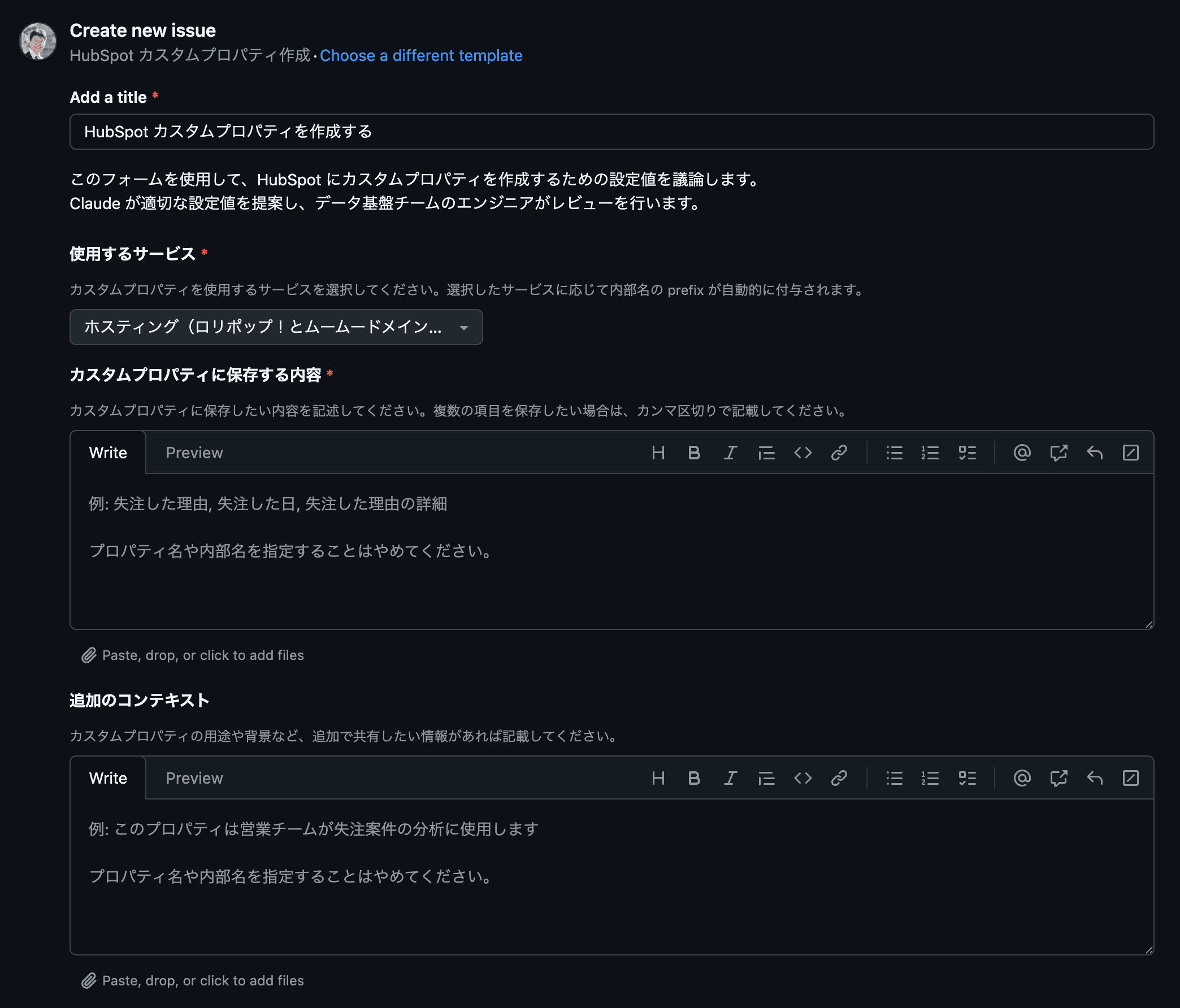
GitHubのIssue Templateには以下の情報を入力してもらいます。
- 使用するサービス
- カスタムプロパティに保存する内容:保存したいデータの説明
- 追加のコンテキスト:用途や背景情報
重要なのは、プロパティ名や内部名を申請者に考えてもらわない点です。Claudeに任せることで、一般的なエンジニアリングのプラクティスに沿えるような設計にしました。
Issue Templateには以下のようなClaude向けのプロンプトが埋め込まれています。
@claude
HubSpotカスタムプロパティを作成します。カスタムプロパティに保存する内容を踏まえて、以下のナレッジベースを参照の上で、プログラミングの一般的な命名やデータベース設計のベストプラクティスに沿う形で、フィールドタイプ, プロパティラベル, 内部名, オブジェクトタイプ, ディスクリプションとして適切な設定値を日本語で提案してください。
また `hubspot_custom_properties.yml` に記載された既存のカスタムプロパティを確認し、同じデータセットに属する既存のプロパティと一貫性のある命名を心がけてください。
# Knowledge Base
Properties are fields that store information on HubSpot records...
(HubSpotの公式ドキュメントを引用)
実際のIssue Templateのスクリーンショットはこちらです。
2. GitHub ActionsでClaudeを自動実行
Issueが作成されると、GitHub Actionsのワークフローで Claude Code GitHub Actionsを用いてClaudeが実行されます。Claude は以下の作業を自動で行います。
- Issueの内容を読み取る
hubspot_custom_properties.ymlから既存プロパティの命名規則を確認- HubSpotの公式ドキュメント(ナレッジベース)とデータベース設計のベストプラクティスに基づいて設定値を提案
- 提案内容をIssueにコメント
3. 既存プロパティ一覧の自動更新
Claude が既存プロパティとの一貫性を保った提案をできるよう、毎日実行される GitHub Actions で BigQuery から既存のカスタムプロパティ一覧を抽出し、hubspot_custom_properties.yml を更新しています。
実際の運用例
特に問題がない場合は、Issue作成から数十分程度でクローズされることが多いです。Claudeが30秒〜1分程度で提案をコメントし、データエンジニアがレビューして承認すれば、申請者はすぐにプロパティを作成してIssueをクローズできます。
一方で、Claudeの提案を無条件に受け入れるわけではなく、申請者やエンジニアからのフィードバックによって議論が発生することもあります。例えば、Claudeが提案した内部名やフィールドタイプに対して、申請者から「実際の用途を考えるとドロップダウン選択にしたい」といった修正要望が出ることがあります。このような場合は議論を経て最終的な設定値を決定します。
このように、Claudeの提案をベースに人間が議論して最適な設計を決められるのがこの仕組みの利点であり、GitHub Issueを通して適切なレビュープロセスが機能していると言えるでしょう。
効果
この仕組みを導入した効果は以下の通りです。
手戻りの削減
従来は「HubSpot ユーザーが自由にプロパティを作成 → データエンジニアが気付いて修正を依頼 → 作り直し」という事後対応で手戻りが発生していましたが、Claudeによる設計と事前レビューに変わったことで以下のような効果がありました。
- エンジニアリングのプラクティスに沿わない設計を事前に防げる
- カスタムプロパティ設計の時間を短縮できる
- Claude による即座の提案(30秒〜1分)により、適切な設計案がすぐに得られる
- データエンジニアのレビューを含めても、多くの場合が数十分程度でクローズ / 複雑なケースでも数日で議論が収束し、最適な設計が決まる
データ品質の向上
- 一貫した命名規則(サービス別のprefix、casingの統一)
- 適切なデータ型の選択
- 既存プロパティとの整合性
これにより、BigQueryにロードされたデータがそのままデータ分析に利用できるようになりました。
HubSpotユーザーの負担軽減
- プロパティ名や内部名を自分で考える必要がない
- HubSpotのフィールドタイプの詳細な仕様を理解する必要がない
- Issueで「何を保存したいか」を説明するだけで適切な設定値が提案される
ユーザーがエンジニアリングの知識やHubSpotの詳細な仕様を気にしなくても、純粋にHubSpotでやりたいことや希望するUIをIssueで述べることで業務の落とし込みが行えるようになりました。
まとめ
GitHubのIssue TemplateとClaudeを組み合わせることで、以下を実現しました。
- HubSpotユーザーがやりたいことだけを考えてカスタムプロパティを申請できる仕組み
- エンジニアリングのベストプラクティスに基づいた設計の自動提案
- データ基盤として実用的なデータ品質の確保
この取り組みのポイントは、HubSpotユーザーの利便性を損なわずに、データ品質を向上させることができた点です。Issue Templateで申請のハードルを下げつつ、Claudeが専門知識を補完し、エンジニアが最終的な品質を担保する、という役割分担がうまく機能しています。
同じような課題を抱えている方の参考になれば幸いです。


