
はじめに
新卒エンジニア研修を担当しました、yukyan, ugoです!
今年も新たなパートナーを迎え、研修のカリキュラムを実施しました。この記事では、各コンテンツの講師陣がその内容と資料をまとめています。ぜひご覧ください!
- はじめに
- 2025年度新卒エンジニア研修概要
- Webアプリケーション開発研修
- フロントエンド研修
- コンテナ研修
- オブザーバビリティ研修
- セキュリティ研修
- 影響を広げる力研修
- データエンジニアリング研修
- 機械学習研修
- AIを前提とした体験の実現に向けて
- Vibe Coding研修
- Web3/Crypto研修
- 外部講師による研修コンテンツ
- おわりに
2025年度新卒エンジニア研修概要
今年は、新卒エンジニアはもちろん、講師陣や迎え入れる全パートナーで「2年後にシニアエンジニアになる」という目標を掲げました。ここでいう「シニアエンジニア」とは、ペパボのエンジニアの制度上の職位になります。
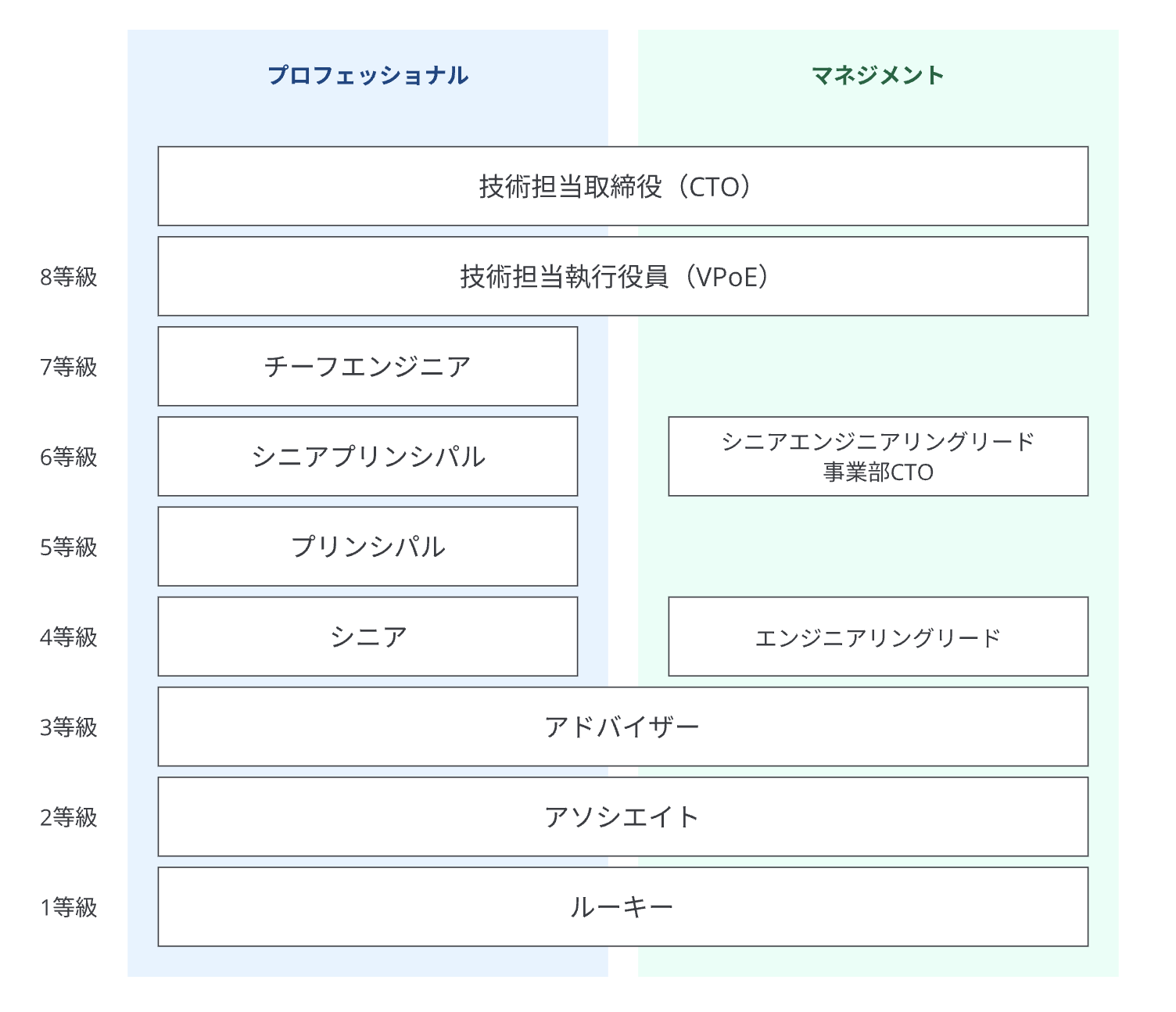
シニアエンジニアは、単に業務を遂行する能力が高いだけでなく、ペパボにおける人材要件の3軸すべてにおいて高度な専門性が求められます。
- 作り上げる力:専門領域において、組織のトップレベルを引き上げられる深い知識を持ち、未解決の課題の解決を完遂できる
- 先を見通す力:専門領域の将来像を示し、現状を整理して課題を抽出した上で、技術・手法の候補を理由とともに言語化し、組織の技術標準として昇華できる
- 影響を広げる力:自身の技術的な経験や知見を言語化し、社内外に発信することで組織力向上やファン獲得につなげられる
また、シニアエンジニアへの昇格の判断は、日常の中で3軸を満たすふるまいをしていることを言語化して表明し、その評価によって「追認」されるものです。つまり、2年後にこの職位に到達するためには、それまでにそうしたふるまいを日常的にできているという実績が必要です。
こうした、ペパボのエンジニアリング組織のトップレベルを引き上げられる専門力を持ったシニアエンジニアに向け走っていくため、研修の目的を下記のように設定しました。
- サービスを作るための技術要素や観点について、現時点で良いやり方を一通り学ぶ
- 目指すべきシニア像を定める
- ペパボの中で、誰が何の専門家なのかを認識する
2024年度の新卒エンジニア研修が「サービスを作るための技術要素や観点について、現時点で良いやり方を一通り学ぶ」ことに重点を置いていたのに対し、今年の研修はさらに2つを追加し、よりシニアエンジニアへの成長を強く意識した内容としています。去年の新卒エンジニア研修について気になる方は、2024年度新卒エンジニア研修を実施しました!もぜひご覧ください。
この目的の達成に向かうという前提のもと、各研修をペパボで活躍している講師の方々に構築してもらいました。
ここからは各研修の講師陣から、カリキュラムの説明と一部研修資料の公開をします。
Webアプリケーション開発研修
担当:shimoju、shiorin
Webアプリケーション開発研修は、shimojuとshiorinで担当しました。 この研修は、新卒エンジニア研修の最初のステップとして、Railsを通してWebアプリケーション開発を学びつつ、AIを前提にした開発のために何が必要かを知ることを目的に設定しました。
AIを使ってRailsチュートリアルを進めてもらいましたが、生成されたコードをそのまま使うのではなく、疑問点が生じた際は書籍や講師への質問などを通じて理解を深めることを重視してもらいました。
また、一番初めの研修ということで、技術力以外でエンジニアとして働く上で大事になるエンジニアマインドに関する研修も併せて実施しました。テクニカルスキルだけでなく、ヒューマンスキルやコンセプチュアルスキルといったソフトスキルの重要性について講義し、エンジニアとして成長するためのマインドや自分ならではの価値観について各自で言語化し、ディスカッションを行いました。
AIを活用した開発が当たり前になる時代だからこそ、自分なりの価値観を持って技術と向き合う姿勢を身につけてもらえたのではないかと思います。
フロントエンド研修
担当: gatchan, yoshikouki, nacal
フロントエンド研修では、JavaScriptのごく基本的な文法についての説明や実行環境、CommonJSやES Moduleといったモジュールシステム、モジュールバンドラー等の周辺ツールに支えられた開発環境などに触れ、要素となる技術のポインタを示すような構成としました。
AIを活用した高速な開発を妥当な技術選択で支えながら進めるには、取りうる手段の引き出しを手広く持つことがよいだろうと考えています。 要素となる技術を抑えておけば、コーディングエージェントと共に高速に試行することで、自身の学習速度を速めることもできるはずです。 要点をおさえつつ、限られた期間でなるべく広く触れられるようにすることで、今後の業務等において「そういえばあのような話があったな」と思い出し、詳細をコーディングエージェントや周辺のエンジニアと共に決定していけるようになるとよいでしょう。
最終的に、前述のWebアプリケーション研修で作り上げたバックエンドを利用し、React Routerによってフロントエンドを構築するような実践的な演習を設け、これらの知識を活用して体得できるようにしました。
加えて、一連の研修の目的である「ペパボの中で誰が何の専門家であるかを認識する」を達成するために、お茶会と称したフロントエンド関連の話題を扱う雑談タイムを設けました。 講師が各々の興味関心のある技術(たとえば、業務で利用している技術やブラウザ、アクセシビリティの話題など)を紹介したり、研修における質問を受け付けるような時間となりました。
これらの取り組みによって、要素となる技術の引き出しとコーディングエージェントの活用を武器にする下地を用意できたと思います。
今回の研修資料は、 trainingリポジトリ にて公開しています。
コンテナ研修
担当: drumato, ryu-ch, kbeku
前年度 でも講師を務めたdrumatoと、初めてコンテナ研修の講師を担当するryu-ch, kbekuの3名で実施しました。内容は前年度から大きく変わりませんが、ミニマムなコンテナランタイム自作を取り入れてより実践的な理解を助けるように構成しました。
- コンテナ技術の基本的な考え方と根幹技術を、ミニマムなコンテナランタイム実装を通して学ぶ
- Dockerの使い方、Dockerfileの書き方、本番運用するうえでのプラクティス実践
- GitHub Actionsの使い方、ペパボ社内で実際に利用されているActionsをもとにしたハンズオン
- Kubernetesクラスタのアーキテクチャ理解、基本的なWorkloads APIハンズオン
- 講義の内容をすべて包括した、デモアプリケーションを開発してKubernetesにデプロイするまでを独力で完走する最終ハンズオン
前年度との差分として、講義のコンセプトの主軸を AI前提におけるSREingのマインドセットと、ハンズオンを通じた実践 に置きました。ペパボではAI前提のエンジニアリングで生産性を限界まで高め、また限界を広げることに取り組んでいます。今回の講義では、Dockerfileを書いてみたり、Kubernetesマニフェストを書いてみるといった素朴な講義にかける時間を大幅に制限し、わからないことを資料+AIを使ってわかるようにするというインプットと、わかったことをAIに取り組ませるというアウトプットのサイクルをとにかく早く回す、という形にしました。
結果として、受講生が最終ハンズオンに必要な知識を習得して使えるようになるまでを、AIを活用して効率的に学習することができていました。最終ハンズオンでは、受講生のそれぞれがアプリケーションの設計から実装、継続的リリースを独力で実現できました。
オブザーバビリティ研修
担当:pochy、chiroru
今年で2回目となるオブザーバビリティ研修を実施しました。
これまでの研修でサービスを「作る」技術を学んだ新卒エンジニアに、本研修ではそのサービスを「運用」し、安定稼働させるためのオブザーバビリティ技術を伝えます。 これにより、サービスを運用する中で発生する様々な問題を、エンジニアリングで解決する力を養います。
そこで本研修では、「監視と可観測性を中心に、システムの運用課題をエンジニアリングで解決できるようになること」を目標に据え、実践的なカリキュラムを設計しました。
この目標を達成するため、利用するツールも見直しを行いました。 その結果、昨年採用したGrafanaスタックに代わり、今年はDatadogを採用することにしました。 選定の決め手は、トレースからログへのドリルダウンが容易であることと、視覚的に統合されたUIがもたらす分析体験の優位性です。
数日という限られた期間で、初めて触れる技術をキャッチアップし最終演習に到達してもらうため、研修の導入にも工夫を凝らしました。
研修の冒頭では、一見問題がなさそうに見えるパフォーマンス問題を仕込んだデモアプリケーションを実際に操作してもらい、そこで発見されなかった問題をトレースを用いて解説することで「オブザーバビリティの利点」を直感的に掴んでもらいました。
また実はこのデモは最終演習とほぼ同じ構成になっており、新卒エンジニアがゴールを具体的にイメージする助けにもなっています。
そして本編では、オブザーバビリティに関する用語や概念を解説する座学と、ユースケースを想定した複数のハンズオンを用意しました。 これらはあくまで最終演習を完遂するための補助的な位置づけとし、各自が必要なものから進めてもらうスタイルを取りました。
研修のハイライトは「破壊と再生」と名付けた最終演習です。 新卒エンジニアは各自で、意図的に欠陥を仕込んだシステムを構築します。 次にそのシステムをOpenTelemetryに基づいて計装し、欠陥の調査に必要なテレメトリーデータの収集と監視の設定をします。 そして最終的に、自分以外のメンバーがDatadogを駆使してその欠陥を調査・修復します。
これまでの研修で培ったアプリケーションやインフラの知識を総動員して取り組んでもらいました。
カリキュラム設計当初は、技術キャッチアップとトラブルシューティングに必要な計装、そして初見のサービスの調査を限られた時間内でうまく進められるかを懸念していました。 しかし当初の心配をよそに、新卒エンジニアはテレメトリーデータを着実に活用して原因を特定し、サービスの改善プルリクエスト作成までやり遂げてくれました。非常に素晴らしい最終演習になったと感じています。
今回の研修資料の一部は、ペパボのtrainingリポジトリで公開しています。
セキュリティ研修
担当: n01e0, hiboma, hirokawa
セキュリティ研修は大きく3つのカテゴリに分け、セキュリティ対策室のエンジニア3名がそれぞれ実施しました。
個別に実施した研修は以下のとおりです。
アプリケーションセキュリティ研修(n01e0)
研修に用いた資料は昨年のものと大きく変更はありませんので、ぜひこちらをご覧ください。
昨年との差分としては
- ハンズオンで使用するやられアプリをVibe Codingで作成した
- よりAI前提の研修を意識した
の二点です。
Vibe Codingによるやられアプリの作成
セキュリティ研修内のコンテンツとして多くの脆弱性を再現したアプリケーション(いわゆるやられアプリ)に対し、実際に攻撃・修正を行うというものがあります。
昨年使用したアプリケーションを更新するのも良かったのですが、いろいろと依存が古くなっており、Migrationが面倒だったので「いっそ0から作ろう。」と思いVibe Codingで作りました。
研修のためとなれば意図的に脆弱性を埋め込むのもやってくれましたし、意図していない脆弱性・バグも発生させてくれました(?)。脆弱性の発見・修正を目的とするアプリケーションなので、意図せず脆弱性が発生しても困りません。Vibe Codingとの相性は最高でした。
AI前提の意識
AI Nativeな世代への研修を実施するにあたり、Unknown-UnknownをKnown-Unknownにする事を主に意識しました。
脆弱性の発見・修正を行う上では、実際の攻撃で使われるテクニックを知る必要があります。
しかし、攻撃のテクニックは非常に数が多く、状況によっても違います。まずは攻撃によって狙われる資産の種類と、その種類毎の攻撃箇所から入り、個別のテクニックについては列挙するだけ。というようなスタイルにしました。
「クライアントサイドでXSSをすればCookieを窃取できる」ということだけ知っていれば、その先のことはAIに聞くなり検索するなりすればわかりますし、講師も現地にいるのでサポートできます。
過去インシデントの再現アプリケーション体験と伝承 (hiboma 研修)
AI では学べない、リアルなインシデント事例を教材とする研修です。
GMOペパボは 2018年1月に情報漏洩のセキュリティインシデントを発生させてしまい、ユーザーの皆様に多大なるご迷惑をおかけした苦い経験があります。この出来事を契機に、全社一丸となりでセキュリティ対策の強化に取り組んできました。
先のインシデントでは、外部の攻撃者によってWebアプリケーションの脆弱性が突かれたことが調査により判明していますが、攻撃の詳細については非公開としています。ただし、社内のパートナー(同僚)には、ポストモーテムやSlackの過去ログ、口頭での伝達などを通じて情報共有を継続し、インシデントの苦い経験を風化させることなく、組織全体のセキュリティ意識の向上につなげています。
今回、Claude Codeを活用して、このインシデントで発生した脆弱性・攻撃を模擬的に再現できるアプリケーションを作成しました。アプリケーションの脆弱性がどのように悪用されるのかを、実際に体験できるハンズオン教材として構成しています。
この教材では、複数の攻撃手法を組み合わせて、最終的にデータベースの情報を奪取するまでの流れを簡易的に再現しています。
実際に作成したアプリケーションや講義スライドの詳細は公開できませんが、「過去の失敗」を教訓とし、未来の再発防止につなげる取り組みとして、参考にしていただければ幸いです。
ドメイン名とDNSに関連するセキュリティの話 (hirokawa 研修)
他の講師がなかなか取り上げなさそうな、ちょっとニッチな題材で研修を行いました。
まず初めに、講師の持っていたドメイン名が売れた話と絡めて、ドメイン名のWHOISとは何か、という話をしました。 併せて、本来はドメイン名の登録者と連絡を取れるように作られたWHOISの情報も、個人情報に敏感になった現代ではドメイン登録事業者による代理公開になっていることが大半である、と言った話題にも触れました。
次に、Lame Delegationの話をしました。 Lame Delegationは、あるドメインの親ゾーンに、そのドメインの権威DNSサーバーとして設定されているサーバーが、実際にはそのドメインのゾーン情報を管理していない、あるいは応答しない状態を指します。
Lame Delegationが発生すると、そのドメインの名前解決が遅延したり、失敗したりする原因となります。しかし、より深刻な問題として、この状態がDNS take overにつながるリスクがあります。
DNS take overは、DNSの設定ミスにつけ込んで、悪意のある第三者がドメインの制御権を乗っ取る攻撃手法です。特に、Lame Delegationが引き起こす「名前解決できない、しかしNSレコードは存在している」という状態は、この攻撃の格好の標的となります。
攻撃者は、親ゾーンに残っている無効なNSレコードやCNAMEレコードを悪用します。例えば、ドメインのNSレコードが、第三者が登録可能なドメインに紐づいている場合、攻撃者はそのドメインを再登録し、自身の権威DNSサーバーを立ち上げます。これにより、元々そのドメインの名前解決を担当していたサーバーではないにもかかわらず、そのドメインに対するDNSクエリの応答を乗っ取ることができます。
研修では、「再登録可能になっているドメイン名」に見立てたドメイン名で既存のドメイン名にネームサーバを設定することでLame Delegation状態を作りました。 その上で、実際にこのドメイン名を取得し、攻撃を再現しました。
影響を広げる力研修
担当:yumu
minne事業部のyumuです。私は、新卒エンジニアが将来シニアエンジニアとして成長していく上で重要な「技術的なアウトプット」の習慣を身につけることを目的として、影響を広げる力研修を実施しました。
「影響を広げる力」とは、ペパボの評価要件の3つの軸のうちの一つです。
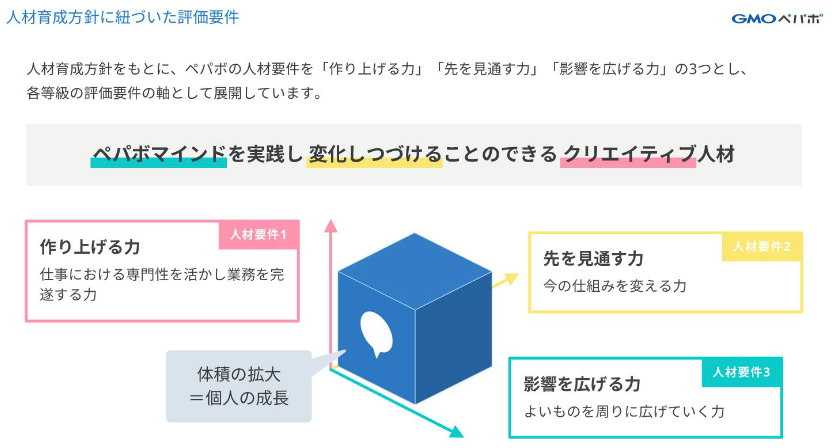
エンジニアとしてのキャリアを積む中で、技術力の向上はもちろん重要ですが、それと同じくらい大切なのが「影響を広げる力」です。この力は、自分の知識や経験を他者に共有し、コミュニティや組織に価値を提供する能力を指します。
実体験から学ぶアウトプットの価値
私自身のアウトプット歴を振り返ると、2024年10月のKaigi on Rails 2024でのLT登壇が大きな転機でした。それまでは「私なんかが知っていることはみんな知っているだろう」という卑屈さがありましたが、実際に発表すると「知らなかった!」という反応をいただき、自信につながりました。
【登壇する → コミュニティに知り合いが増える → イベント参加が楽しくなる → 登壇する】というサイクルが回り始めると、自然とより多くのアウトプットをしたくなり、エンジニアとしてのスキルも向上していく好循環が生まれます。
実践のススメ
研修の後半では、新卒エンジニアがアウトプットを始めやすくするため、よくある疑問に回答しました。
- Q: 詳しくないことはアウトプットできない? → A: アウトプットすることで詳しくなれる
- Q: プロポーザルを出す段階でネタが完成していないといけない? → A: プロポーザル駆動開発でOK
- Q: アウトプットするネタがない → A: 一つの機能開発でも切り口はいっぱいある
また、「影響を広げる」とは単にアウトプットするだけでなく、「人に行動を引き起こさせた」かが重要であることも説明しました。SNSでの反響、専門分野での認知獲得、採用への貢献、チームメンバーへの良い影響などが具体例として挙げられます。
最後に、テックブログの執筆やイベントへの応募など、すぐに実践できるアクションを提案しました。新卒エンジニアのみなさんには、まずは恐れず小さなアウトプットから始めて、それを継続していってほしいと思います。
データエンジニアリング研修
担当: misaton, pochy, yancya, zaimy
技術部データ基盤チームのzaimyです。データエンジニアリング研修を担当しました。
今年の研修では、去年の1営業日から3営業日へと大幅に期間を拡充し、「現時点での最高のやり方」を体系的に学べるカリキュラムを構築しました。
研修の狙いと構成
本研修は、以下の3つの柱で構成しました。
- ビジネス理念とデータ活用事例の理解(1日目)
- Bigfootのミッション・ビジョン・戦略の共有
- SSOT(Single Source of Truth)の重要性とデータ民主化
- これまでの活用事例(可視化、マーケティング自動化、機械学習の導入)の紹介
- モダンデータパイプラインの実践(2日目)
- ELT vs ETL の理解と、なぜ ELT を選ぶのか
- データ基盤三層構造(Bronze/Silver/Gold)の設計思想
- MySQL -> Debezium -> Kafka -> DuckDB のリアルタイムパイプライン構築
- dbt によるデータ変換の習得(3日目)
- dbt の設計思想と基本操作
- マテリアライゼーション戦略の実践的な使い分け
- 実データを使った品質問題の発見と対処
座学とハンズオンのバランス
データエンジニアリングは「実際に手を動かす」ことが重要な分野です。そのため、座学で理論を学び、ハンズオンで実践するという構成を採用しました。例えば2日目では、架空の EC サイトをサンプルアプリケーションとして用意して、これを題材にビジネス課題を解決するパイプラインを構築してもらいました。
AI 時代の学習アプローチの提案
今年の研修で特筆すべきは、受講者全員が AI を活用して自律的に学習を進めていた点です。しかし、AI は問題点を自ら提示してくれないという課題もありました。また、新卒の方々からは「なじみがない分野で専門用語がわかりづらい」というフィードバックも頂きました。今後の研修では、以下のような工夫を取り入れることで、より効果的な学習環境を構築できると考えています。
- 専門用語の事前学習: データエンジニアリング特有の用語集や概念マップを事前に提供し、基礎知識の土台を作る
- Working Out Loud の導入: 受講者に作業の可視化と思考プロセスの共有を促すことで、AI との対話だけでなく、他の受講者との相互学習を活性化させる
- 実データの課題体験: AI では解決できないデータの不足や品質問題などに意図的に直面させることで、AI の限界と効果的な活用方法を理解してもらう
- 15分ルールの導入: 「15分 AI に質問して解決しない場合は、Slack で思考プロセスを共有しながら人間に聞く」というルールを設定し、AI と人間の協働による効果的な学習環境を構築する
研修の成果と今後の展望
研修後の振り返りでは、技術だけでなく「データの利活用者をどう支援するか」「Bigfoot がどのような価値や使われ方を期待しているか」といったビジネス視点の議論ができたことが高く評価されました。
また、「現時点での最高のやり方を提供する」という目標設定により、現状できていないことでも理想的な状態を示すことができ、講師側にとっても「現代における最高」を再考する良い機会となりました。新卒の方々がそれぞれの配属先で、現時点の最高のやり方でデータ活用を推進してくれることを期待しています。
来年に向けては、アウトプットの機会を増やし、実データを用いた仮説検証のサイクルを回せるような、より実践的な研修へと進化させていく予定です。
機械学習研修
担当: miyakey
研究開発チームのmiyakeyです。機械学習研修を担当しました。
本研修では例年、機械学習やAIを活用したサービス開発に必要な基礎知識を学んでいただいています。しかし本年は、ほぼ全ての受講者がすでに機械学習モデルの開発経験を持っていたため、座学を最小限にとどめ、演習を中心に実施しました。
演習では、実際のサービスデータを用いた分類モデルの開発に取り組んでいただきました。簡易的なコンペ形式としたことで、半日程度の短い時間ながら、特徴量設計やデータ変換を分担し、協力しながらスコアを着実に伸ばしていく姿が大変頼もしく感じられました。
後半は、開発したモデルをサービスへ適用する際に必要となる知識について座学を行いました。 本研修で得た経験を活かし、今後もAIや機械学習の積極的な活用を推進していただけることを期待しています。
AIを前提とした体験の実現に向けて
担当:どすこい
「AIを前提とした体験の実現に向けて」を担当したどすこいです。ペパボで掲げている「AI前提」の認識を揃え、自分が去年からしている活動や、その時の知見を加えた講義をしました。
本研修では、去年miyakeyさんが担当したAIを前提とした体験に向けてを学んでもらい、それをペパボのサービスに適用するにはどうしたらよいのかをワークショップ形式で考えてもらいました。その後、ユーザに提供するAI体験とは別に、ペパボでの”AI前提”を推進した話をしました。
昨今、AIの進歩は著しく、サービスや業務にAIを導入していかなければ、競争力を失ってしまうという状況になっています。ここで見誤ってはいけないことは、AI導入そのものは目的でなく、ユーザ体験の向上や業務効率化こそが目的であり、手段に過ぎないということです。この目的に焦点を当てて、本講義のワークショップや事例紹介では、AIを用いてどのような体験を実現したいのか、AIを用いてどのような目的を達成したいのかということを知って、考えてもらいました。
また、僕がDify講習会(こちらの記事に詳細があります)で、Difyを利用した業務でのAI活用を推進していく中での知見、また実際に業務改善を進めていった中での知見も共有しました。技術的な難しさよりも、業務のどの部分が自動化されたのか、人間の仕事とAIの仕事をどこで区切ったのかという事例を紹介しました。
今年の新卒の方々は、みなさんAIに関する知識がありますし、VibeCoding研修の記事で言われている「パラダイムシフト」後にエンジニアのキャリアを始められた方々です。これからのペパボの”AI前提”を一緒に推進していってくれるというのを楽しみにしています。
Vibe Coding研修
担当:yukyan
Vibe Coding研修を担当したyukyanです。今年は『日本初!?「Vibe Coding研修」を2025年新卒研修の目玉として実施します』にて宣言したとおり、昨今のLLMによる開発の時流を踏まえ、今後のエンジニアリングについて考えること、そしてAI前提の開発を次のステージに引き上げることを目的とし、カリキュラムを設計しました。
ペパボとAIコーディングの歴史について一通りお話ししたあと、ペパボで実際にエンジニアが活用しているCursorとClaude Codeについてそれぞれドキュメントを用いて学びました。また、そこで得た知識を活かして、フリーテーマでVibe Codingを使ってアプリケーションを作成しました。
元々、AIコーディングツールの一つであるCursorを研修内ですでに使っており、AIコーディング自体は日常的に体験できていたと思いますが、経験に基づく感覚的な使用がほとんどだったと思います。この研修では各ツールのドキュメントを網羅的に見て、よく使っている機能や知らなかった機能を共有し合うというセッションを設けました。これにより、今のAIコーディングツールでできることをさらに把握し、活用することができるようになりました。また、実践により、コードの詳細を意識せずとも簡単にコーディングができるVibe Codingの威力を実感できました。
さらに、座学として現状のAIコーディングツールのインタフェースや、契約形態について説明しました。ペパボにおいては現在Cursor、Claude Code、Devinなどさまざまなツールを導入していますが、それぞれ設計思想やインタフェースが違います。それらにどのような特性があるか、そしてその特性を踏まえてどのようなマインドでツールを使えばいいかについて解説しました。
今回フリーテーマで作成したアプリケーションのうち、 @Jonny が作った「Translator」というSlack Botは、実際に社内リリースされ、開発に関わるパートナー同士のコミュニケーションコストの削減に使われています。このように、Vibe Codingの考え方を活用してプロダクト開発を推進し、サービス価値向上に貢献していくことを期待しています。Translatorに関してはまた別の機会に紹介します。
Web3/Crypto研修
担当:kurotaky
今年はなんと、Web3/Crypto研修を行いました。なぜ今この領域の研修を行うのか。それはWeb3/Cryptoも、研修の目的の中に書いた「サービスを作るための技術要素」の一つであり、ユーザーに価値を提供する上で検討する手段の一つであると考えているためです。
この研修に関しては後日詳細を書いた記事がテックブログから出ますので、ぜひそちらをご覧ください。
また、今までのペパボのWeb3に関する取り組みはなぜGMOペパボがWeb3への取り組みを始めるのか に書かれています。ぜひご覧ください。
外部講師による研修コンテンツ
ペパボのパートナーによる研修のほか、外部のプロフェッショナルをお呼びし、以下のようなコンテンツも実施しました。
- データモデリング研修
- TDD研修
- データベース特別講義
おわりに
2025年度の新卒エンジニア研修では、「2年後にシニアエンジニアになる」という目標を掲げ、サービス開発に必要な技術の習得だけでなく、専門性の深化と影響力の拡大を意識したカリキュラムを実施しました。
今年の研修は、AI前提の開発という新しい要素を取り入れ、受講者にとっても講師陣にとってもチャレンジの機会となりました。AIによって技術的な壁にぶつかるスピードが上がった結果、エンジニアリングの専門力は重要性を増していると感じています。そして、そのための土台作りがこの時代のエンジニア研修で求められていることだと、研修を通して実感しました。
本研修を通じて、新卒エンジニアが現時点での最高の知識と技術を身につけ、「AI前提」で各事業部における課題解決を技術の力で推進していくことを期待しています。
最後になりますが、研修の構築に関わってくださったパートナーのみなさん、外部講師のみなさま、日本CTO協会のみなさま、その他研修にご協力いただいたすべての方々に感謝いたします。ありがとうございました!



