
こんにちは!技術部データ基盤チームのmisatonです。
本記事では、先日開催した開発合宿にて検証した、BigQuery のデータマートと Cursor Agent を使った信頼性の高い dbt model の生成を紹介します。
開発の背景
データ活用現場の課題
ペパボには多数の部門・サービスのデータが蓄積されています。各部門やチームでそれぞれデータが活用される一方で、データの集計・分析をより効率的に行うための課題もあります。
たとえば「この商品の売上傾向は?」「ユーザーの行動パターンは?」といったビジネス上の問いに答えるには、以下の要素が必要です。
- 各サービス・ドメインの知識や業務経験に基づいた仮説立案
- 既存データの構造理解やSQLスキル
- 仮説検証から結論導出までの分析プロセス
これらすべての要素を揃えて分析を行うためには相応のリソースが必要となります。 結果として、ニーズが生まれてから結果が取得できるまでに時間がかかってしまうケースもありました。 そこで私たちは、データを活用したいパートナーがより簡単に、迅速に、安心してデータを扱える仕組みづくりに取り組みました。
目指すゴールと開発合宿で行ったこと
「データ利用者本人が、自分の知りたいことを、専門知識がなくてもデータで確かめられる環境」を実現するため、「業務で使えるSQLをデータ利用者が自然言語から得られること」をゴールに定めました。 その上で、今回の開発合宿では、LLMを活用して実用的なdbt modelを自動生成する仕組みの検証に取り組みました。
この仕組みでは、自然言語で質問するだけで、以下の4つの情報が自動で出力されます。
出力される内容
- 質問に対する回答を得られる dbt model(クエリとスキーマ定義)
- テストデータ(dbt data tests の given)
- テストデータから期待される集計結果(dbt data tests の expect)
- dbt model から compile されたクエリ
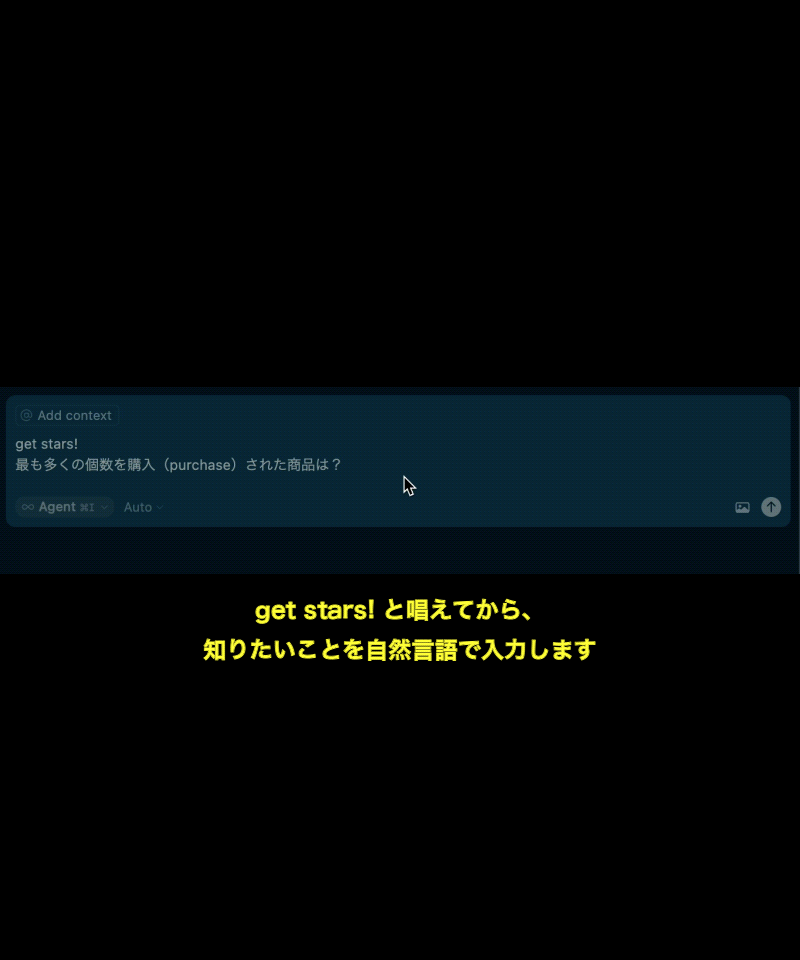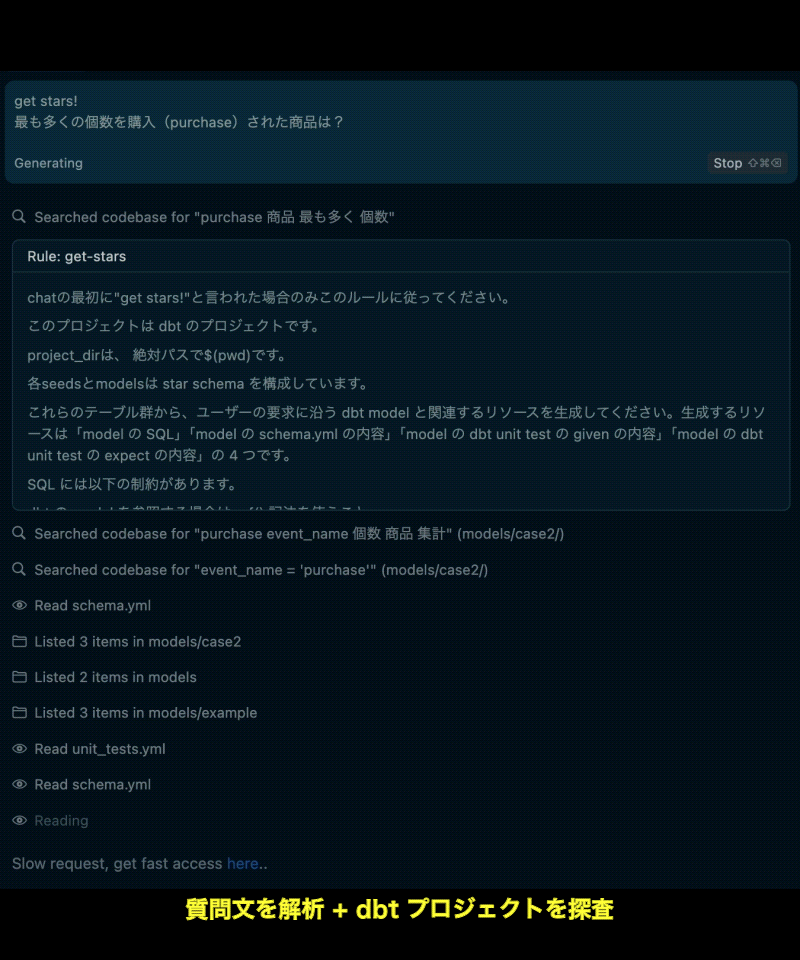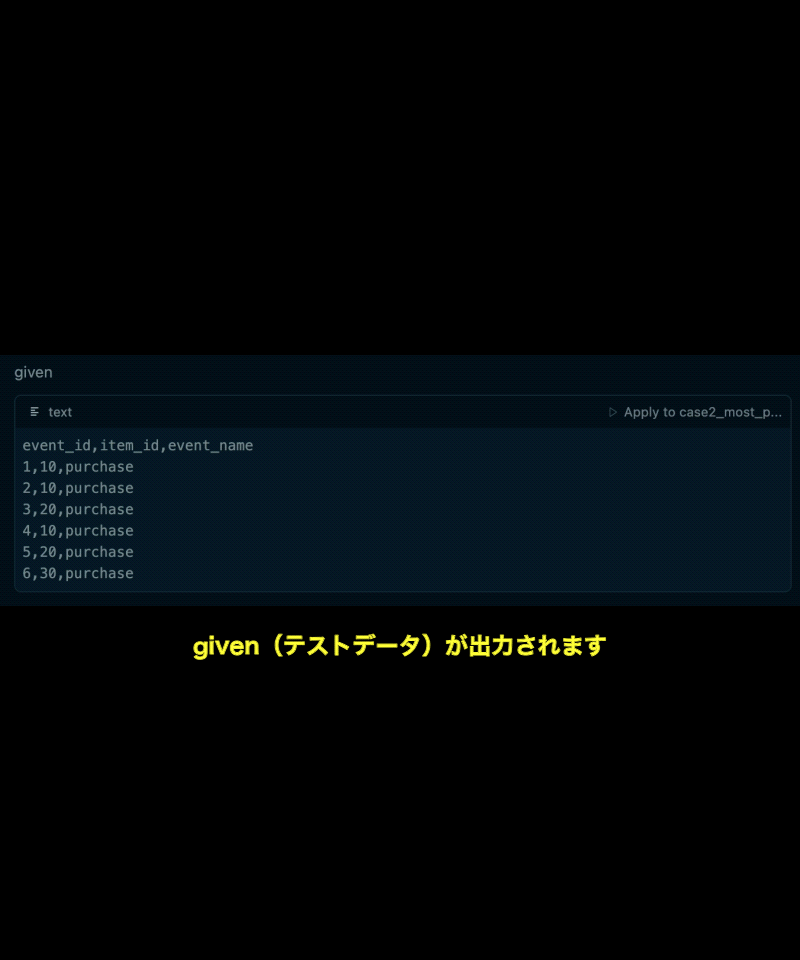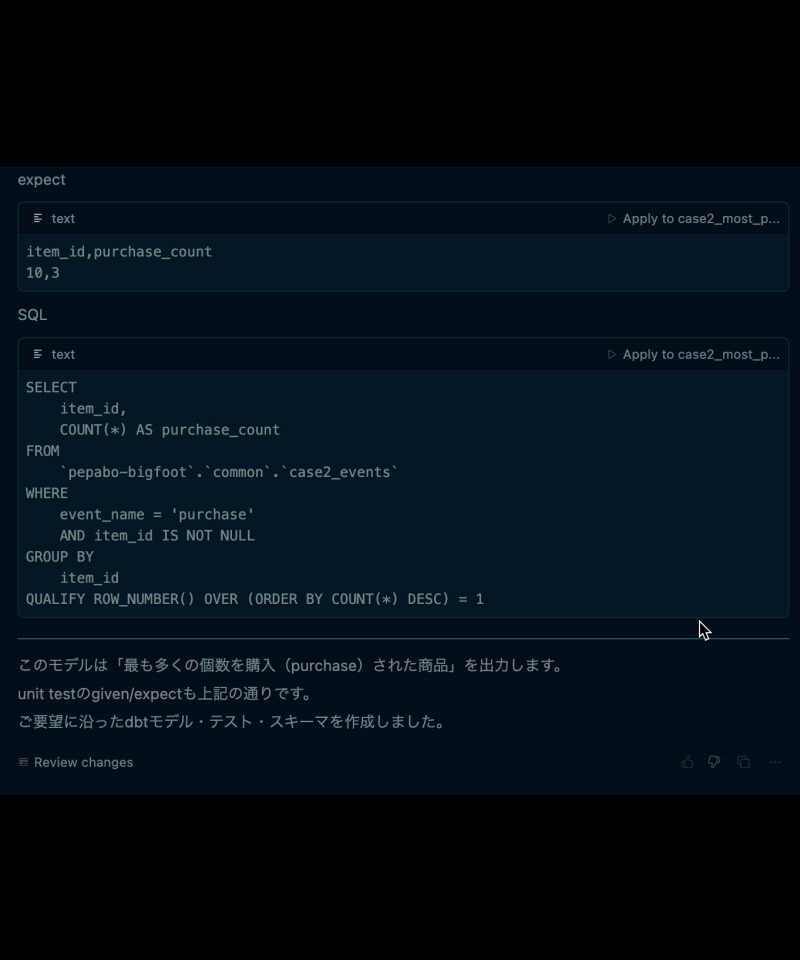
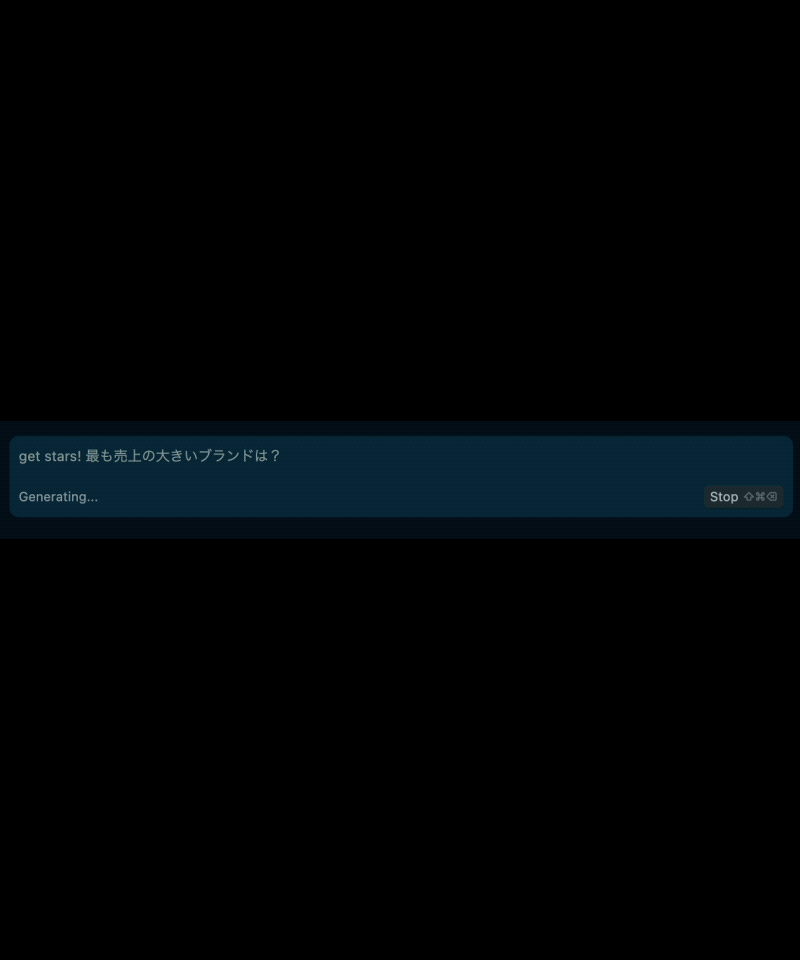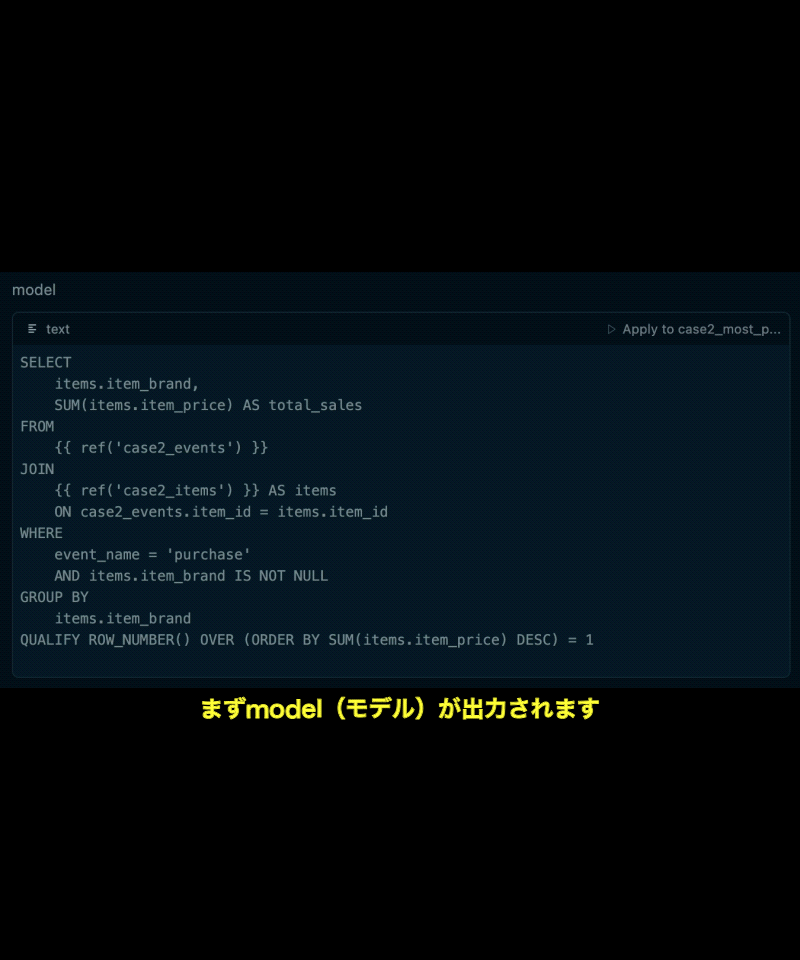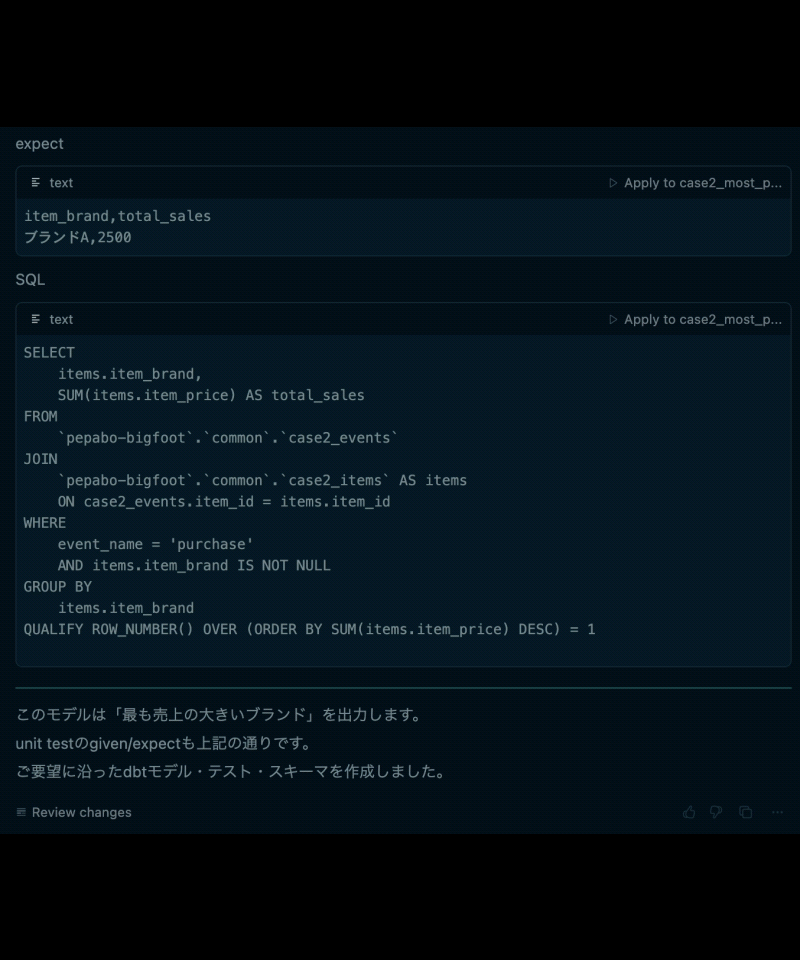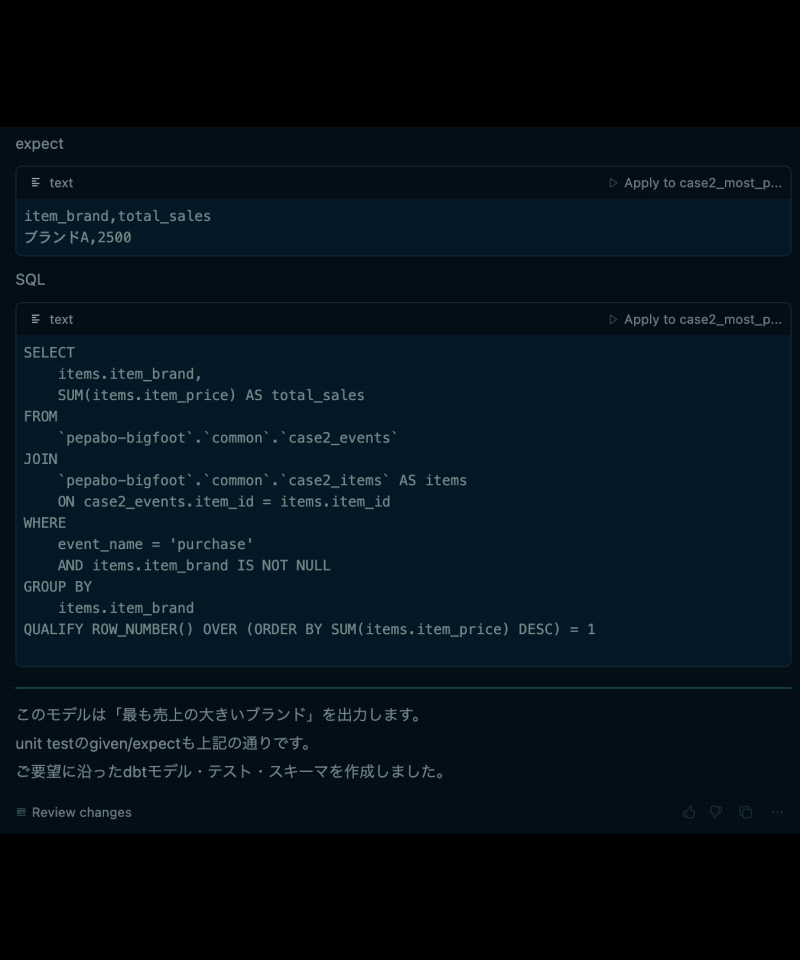
特に重要なのが、2.テストデータ(dbt data tests の given)と、3.テストデータから期待される集計結果(dbt data tests の expect)です。
この2つをレビューするだけで、データ利用者は、SQLの細かい知識がなくても「このクエリ定義で自分の意図した集計が行われるのかどうか」を判断できるようになります。
例えば、データ利用者が「最も売上額の大きい注文」を求めるクエリを得たい場合、 出力された10件の注文レコード(テストデータ)について、実際に最も売上の大きい注文(期待される集計結果)が出力されていれば、出力されたクエリが正しそうであるとレビューできるわけです。
SQLで書かれたクエリが書ける・読めるかどうかに関わらず、誰もが安心してデータを利用できることこそが、この仕組みの最大の価値です。
開発合宿での成果
Cursor の Agent を用いて dbt model を自動生成する仕組みの作成
- AI にサンプルとして与える dbt model の SQL, スキーマ情報, テストデータ(dbt の unit test で用いる入力と期待出力)の作成
- Cursor の Agent で dbt を扱うための MCP Server の開発
自動生成が可能かどうか検証するためのデータマートの作成
データマートは集計や分析を行いやすいようスタースキーマで設計しました。今回の仕組みでは、データマートのテーブル群を「stars」と呼び、クエリ生成時のキーワードとしても活用しています。
なお、データマートは、マスタ系のデータとログ系のデータをそれぞれ検証できるよう 2 種類用意しました。
売り上げマスタを模したデータマート
case_1_fact_sales:売上ファクトテーブルcase_1_dim_items:アイテムディメンションテーブルcase_1_dim_users:ユーザーディメンションテーブル- etc.
ユーザー行動のログを模したデータマート
case_2_fact_events:行動イベントファクトテーブルcase_2_dim_event_types:イベント種別ディメンションテーブルcase_2_dim_device_categories:デバイス種別ディメンションテーブル- etc.
開発合宿での成果詳細(機能デモのキャプチャあり)
これらの成果を活用し、実際にどのようなことができるようになったか、デモを通じてご紹介します!
下記キャプチャでは、Cursorを使って自然言語で質問するとSQLクエリが生成され、さらにテストデータを用いた集計結果が得られる様子を確認できます。
※本記事では、Cursorに特定のキーワードによって指示を出すことを「詠唱」と呼んでいます。デモのキャプチャ内でも、ユーザーが「詠唱」することでAIが自動的にSQLやテストを生成し、集計結果を返す様子を確認できます。
分析デモ
Cursor上でまず最初に「get stars!」というキーワードを入力してシステムを起動します。 その後は知りたいことを自然言語で質問するだけで、CursorやMCP Server、dbtなどの各コンポーネントが連携し、以下の情報を自動で出力します。
出力される内容
- 質問に答えるクエリ定義(model)
- 使用されたテストデータ(given)
- 期待される集計結果(expect)
- 実際にコンパイルしたSQL
商品分析
「最も多く売れた商品は?」
「最も売上の大きいブランドは?」
行動分析
「最もアクティブなユーザーは誰?」,
「ユーザー別に一番多いイベントは何?」
技術的な詳細
このシステムは以下のコンポーネントで構成されています。
- dbtプロジェクト
クエリを dbt model として管理することでテスト可能にする - stars-mcp-server
外部からのリクエストに応じてdbtコマンドを実行し、その結果を返すAPIサーバ。FastMCPを利用している。 - Cursor
ユーザーからの自然言語入力を受け付け、外部のLLMサービスに問い合わせ、SQL生成や解析を行う。
処理の流れ
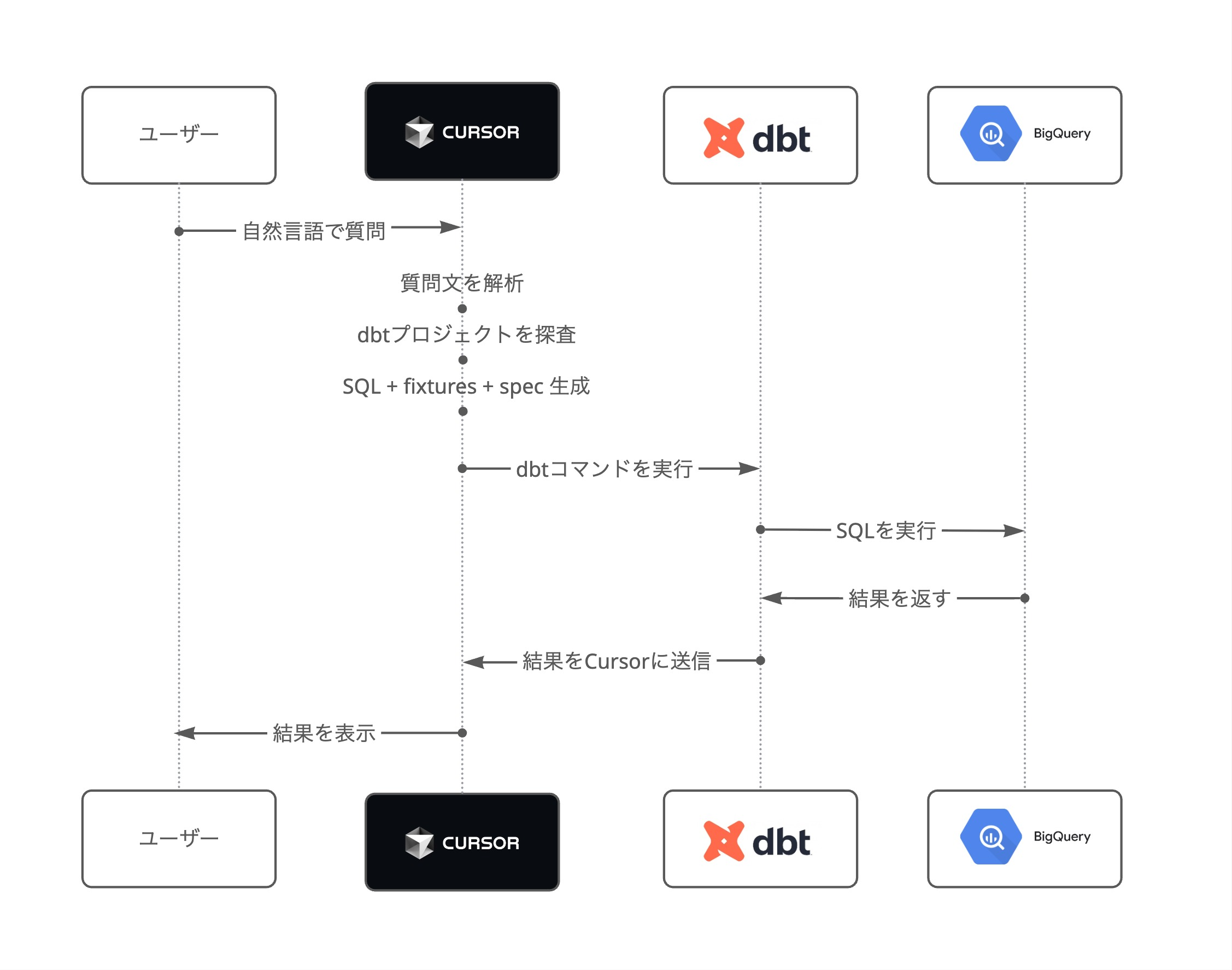
下図は、ユーザーの自然言語による質問から、Cursor・dbt・BigQueryを経て結果が返るまでの一連のやりとり(シーケンス)を示しています。
各コンポーネント間の動的な連携の流れを時系列で表現しています。
- ユーザーがCursorに自然言語で質問
- Cursorが質問を外部のLLMサービスに送信し、質問を解析・dbt modelを生成
- 生成されたdbt modelやリクエスト内容をMCP Serverに送信
- MCP Serverがリクエストに応じてdbtコマンドを実行
- 結果がCursorを通じてユーザーに返される
技術スタック
- dbt
- BigQuery
- stars-mcp-server(FastMCP利用)
- Cursor(LLM連携)
今後の展開
現在はテストデータでの動作確認が完了した段階で、今後は以下のような展開を予定しています。
- 各サービス・事業の実際のデータでの集計・分析
- 既存の事業データを今回紹介した仕組みで活用できるよう整備
- より多様な集計・分析ニーズへの対応
- 複雑な分析や時系列分析など高度なケースへの対応
- ケーススタディの結果のプロンプト化
- 実際のユースケースで作成したモデル構成をプロンプトに落とし込み
- 新しいユースケースへの汎用的な対応を可能にする
まとめ
今回は、BigQuery のデータマートと Cursor Agent を使った信頼性の高い dbt model の生成機能についてご紹介しました。 今後もデータ利用者にとって最高のデータ基盤を提供し、各職種パートナーが大きな価値をユーザーに届ける支援ができるよう、ユースケースの拡大に取り組んでいきます。
データやAIを使った仕組みづくりに興味がある方、ぜひ↓からご応募ください!

