
はじめに
こんにちは。技術部技術基盤グループのharukin,drumatoです。
カラーミーでは従来Data Firehose(旧Kinesis Data Firehose)を用いて、Amazon RDSの監査ログをS3に保存する仕組みを運用していました。 しかし、運用していく中で継続的に大きいコストがかかっていることがわかったため、それを改善する取り組みを行いました。 本記事では、発見された課題と解決策、それによって得られたメリットについてご紹介します。
以後、このプロジェクトを colorme-rds-audit-logs-s3 と呼称します。
背景
カラーミーショップは国内最大級のECサイト作成サービスです。 現在の総流通額は3兆円、総導入店舗は22万件を超えており、多くのユーザの方々に使っていただいております。 わたしたち技術基盤グループは事業横断的な組織であり、このカラーミーショップに対してもサービスの信頼性向上に責任を持って取り組んでいます。
カラーミーショップでは主となるデータベースにAmazon RDS for MySQLを採用しています。 このデータベースには、商品情報や受注管理情報など、膨大なデータ量を蓄積しています。
参考: カラーミーショップDB構成
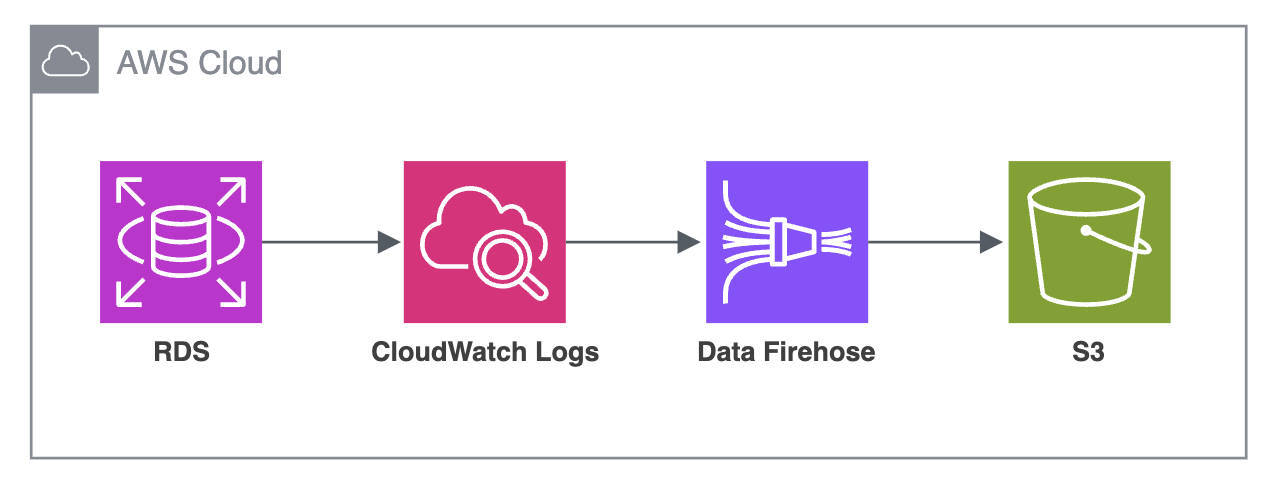
このRDSインスタンスに対し、監査ログを有効にし、インシデント発生時や内部監査時に調査できるようにしていますが、 日々大量のクエリが処理されるため、監査ログのデータは非常に大きくなっています。
これまで監査ログはRDSの設定でCloudWatch Logsへのエクスポートを有効化し、Data Firehoseを通じてニアリアルタイムでS3に保存していました。 しかし、「監査ログデータの調査」という目的に対し、この手法が適切であるかを再度検討した結果、以下の3つの課題がありました。
- 信頼性
- 監査プロセス
- コスト
信頼性
従来の仕組みでは、RDSの監査ログがCloudWatch Logsにエクスポートされ、その後Data FirehoseがS3に保存していました。 しかし、S3に正しく監査ログが保存されていることを保証する仕組みがなく、監査ログの保全プロセスがブラックボックス化しており、 チームが仕組みを把握していなかったことからメンテナンスされておらず、システムの信頼性に懸念がありました。
監査プロセス
監査対応ではS3に保存された監査ログを参照していますが、RDSのPrimaryとReplica のログが同じS3内で混在していたため、 特定のRDSインスタンスの特定の日時のログファイルを探しにくいという課題がありました。
また、実際の調査プロセスでは、S3に保存されたログデータを確認することから、CloudWatch Logsへの蓄積は不要と結論付けました。
コスト
私の環境において、CloudWatchのコストとなる要因は様々です。 今回問題化したRDSの監査ログ保存以外にも、EC2、ECS、LambdaなどのコンピューティングリソースのシグナルもCloudWatchに保存されています。 ですが実際に調査してみると、CloudWatch全体のコストのうち、RDSの監査ログを保存する仕組みによるコストが支配的(約9割)でした。
特に以下の3つが主要なコスト要因となっていました。
APN1-DataProcessing-Bytes(CloudWatch カスタムログ | 収集 (取り込み))APN1-VendedLog-Bytes(CloudWatch 出力ログ | 配信 (Amazon CloudWatch Logs))APN1-CW:Requests(CloudWatch API リクエスト | API リクエスト)
参考: CloudWatch コストを分析、最適化、削減する - Amazon CloudWatch
サービス運用に必要なコスト全体のうち、CloudWatchのコストが無視できない割合を占めていたため、 コスト削減施策として取り組むべき課題だと判断しました。
上記の課題を踏まえて、わたしたちは新たに監査ログを保全する仕組みを作ることにしました。 システムを作るうえでRDSの監査ログを保存するという目的に対し、高い信頼性を実現するために、以下のような要件を定義しました。
要件
機能要件
まず実現すべき機能要件として、 ログデータの完全性 を定義しました。 RDSインスタンスにはユーザの方々に関するデータが保存されており、RDSインスタンスが適切に保護され、不正アクセスされていないことを保証し続ける必要があります。 監査ログはインシデント発生時の調査に用いるだけでなく、内部監査でも利用されるため、 その完全性はきわめて重要であるといえます。
次に、 ログデータの検索性 にも着目しました。 今回の例では、「特定時点において実行されていたログ」を適切に取得できることを主なユースケースとし、 それを担保できるような状態でログデータを保存し、解析できる状態を目指しました。 このように、分析するためのデータを保存する際には、そのデータがどのように使われるかを考える必要があります。
まとめると、以下のようになります。
- 監査ログの完全性
- RDSの監査ログの内容と、S3に保存する監査ログの間に差分が生じないことを保証する
- RDSの監査ログが欠損せずに、S3に保存されることを保証する
- 監査ログの検索性
- 各ログのオブジェクトパスを明確に設計し、監査対応およびインシデント対応で活用しやすいようになっていること
- 各RDSインスタンスごとに調査できるようになっていること
非機能要件
監査ログの保全を実現するシステムは、上記機能要件に記載した通り監査プロセスで利用されるため、非常に高い信頼性を持つ必要があります。 一方で、カラーミーショップを使うユーザに対する本質的な価値提供に割けるコストを最大化するため、 できるだけ少ないコストで堅牢なシステムを構築する必要があります。
上記事項を実現することをプロジェクトのゴールと設定し、 以下のように非機能要件を定義しました。
- コスト削減
- 従来の仕組みと比較して、必要最低限のコストに抑える
- 事業成長に予算を多く割けるようにしたい
- 従来の仕組みと比較して、必要最低限のコストに抑える
- 障害対応とワークアラウンド
- 監査ログの欠損という避けなければいけない事態に対して、堅牢なシステムを構築する
- 監査ログ欠損の恐れのある事象に迅速に気づける仕組みを構築する
- アラートに対するアクションをあらかじめ定義しておく
- 監査ログの欠損という避けなければいけない事態に対して、堅牢なシステムを構築する
設計
colorme-rds-audit-logs-s3の全体像を以下に示します。
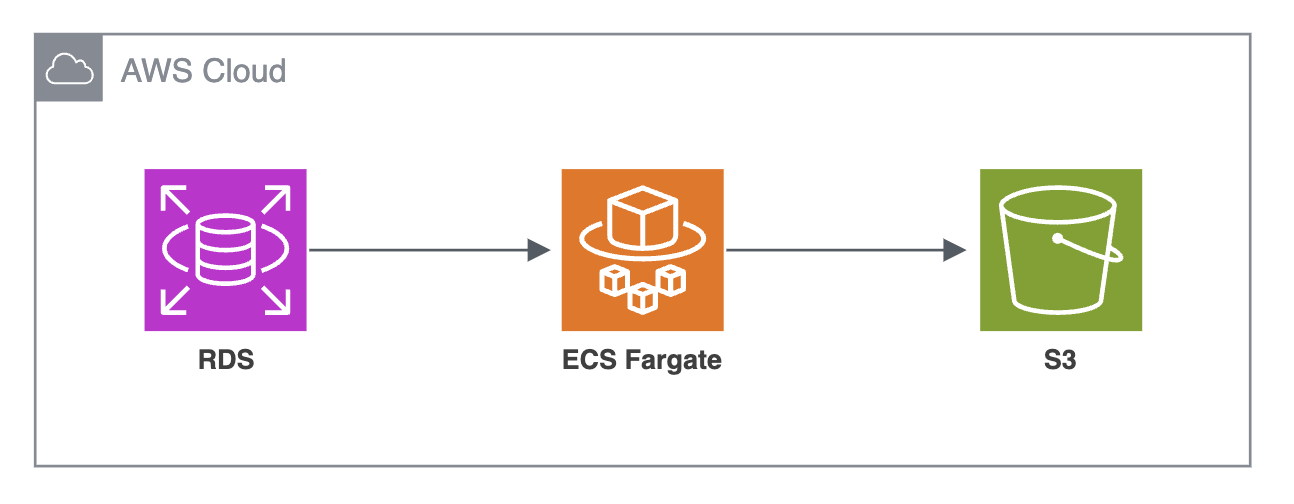
新しい仕組みでは、RDSの監査ログを直接S3に保存するために、ECS Fargate、Step Functions、EventBridge Scheduler、CloudWatchアラームを組み合わせて構成しました。
各構成要素の詳細な設計を解説します。
システムの構成要素
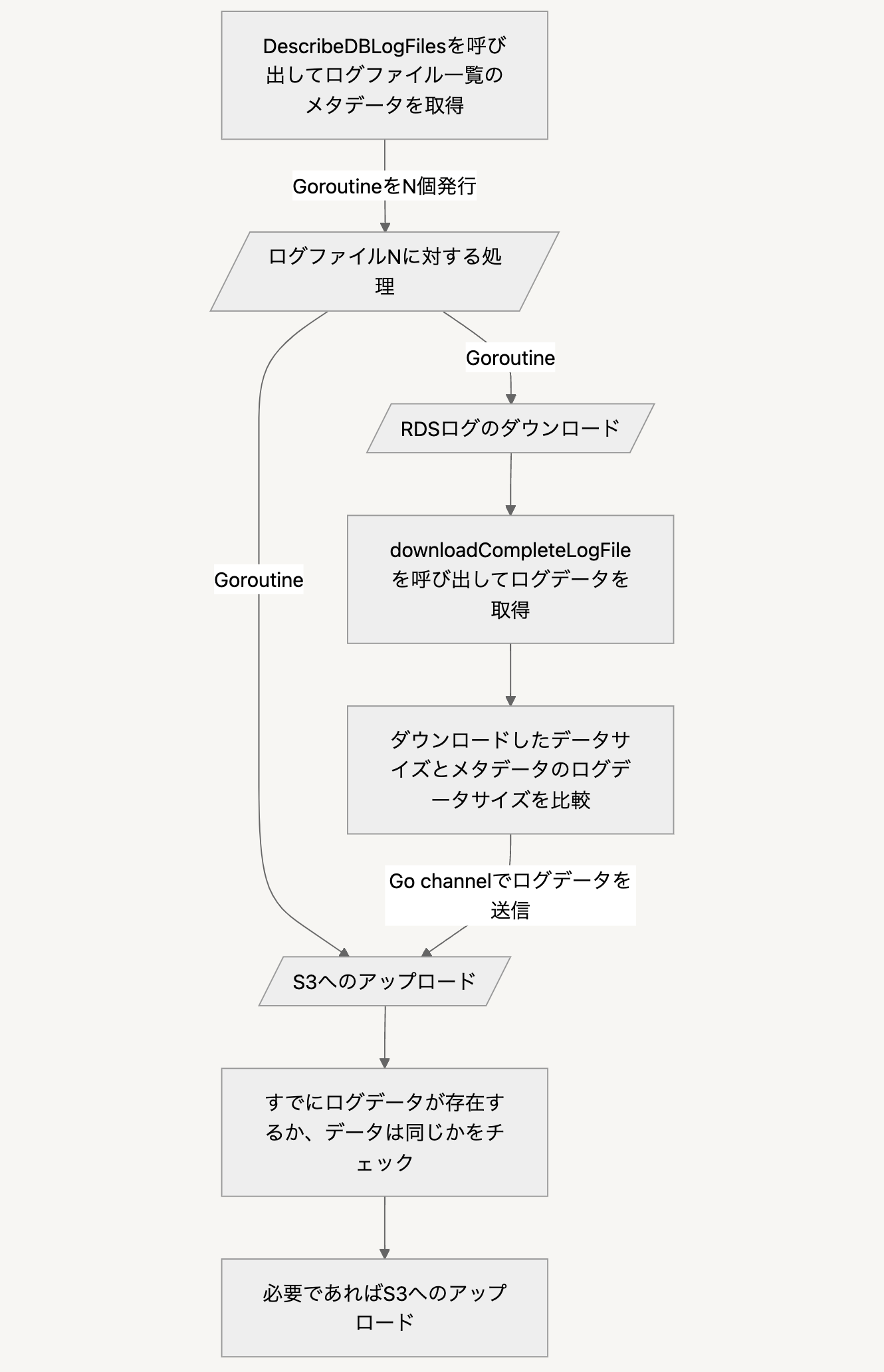
ECS Fargate
監査ログ保全のメインとなるコアロジックであり、 Goで内製したプログラムをコンテナで動かしています。 詳細は省略しますが、大まかな動作を以下のフローチャートに図示します。
Step Functions
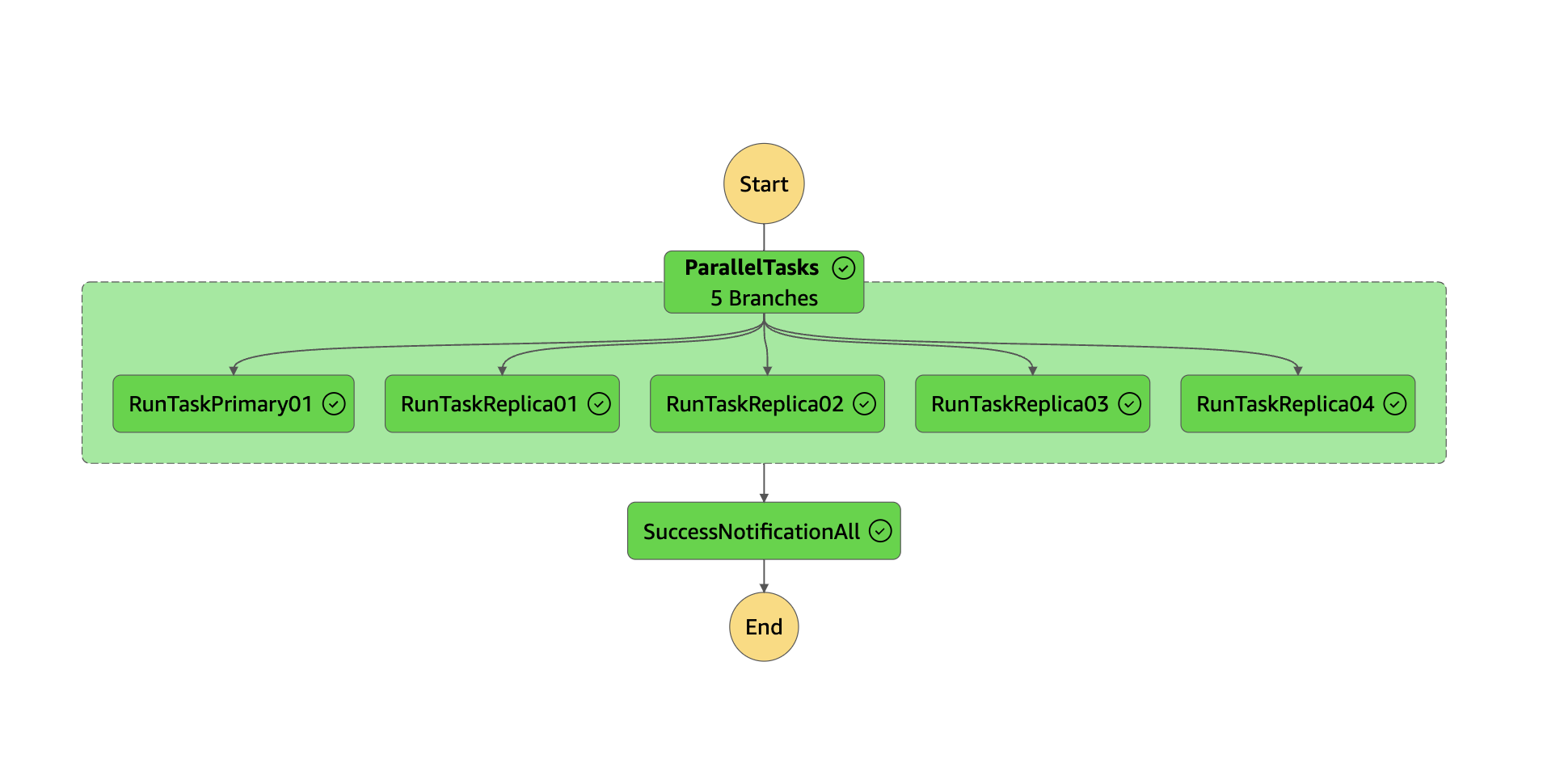
Step Functions は複数の ECSタスク を並列に実行し、それぞれが RDSインスタンスと対になっています。 今後、Replica の増加が予想されるため、Replica の数が変動しても柔軟に対応できる仕組みを Terraform で構築・管理しています。 これにより、ECS Fargate を活用した Replica の監査ログ取得が容易になっています。
EventBridge Scheduler
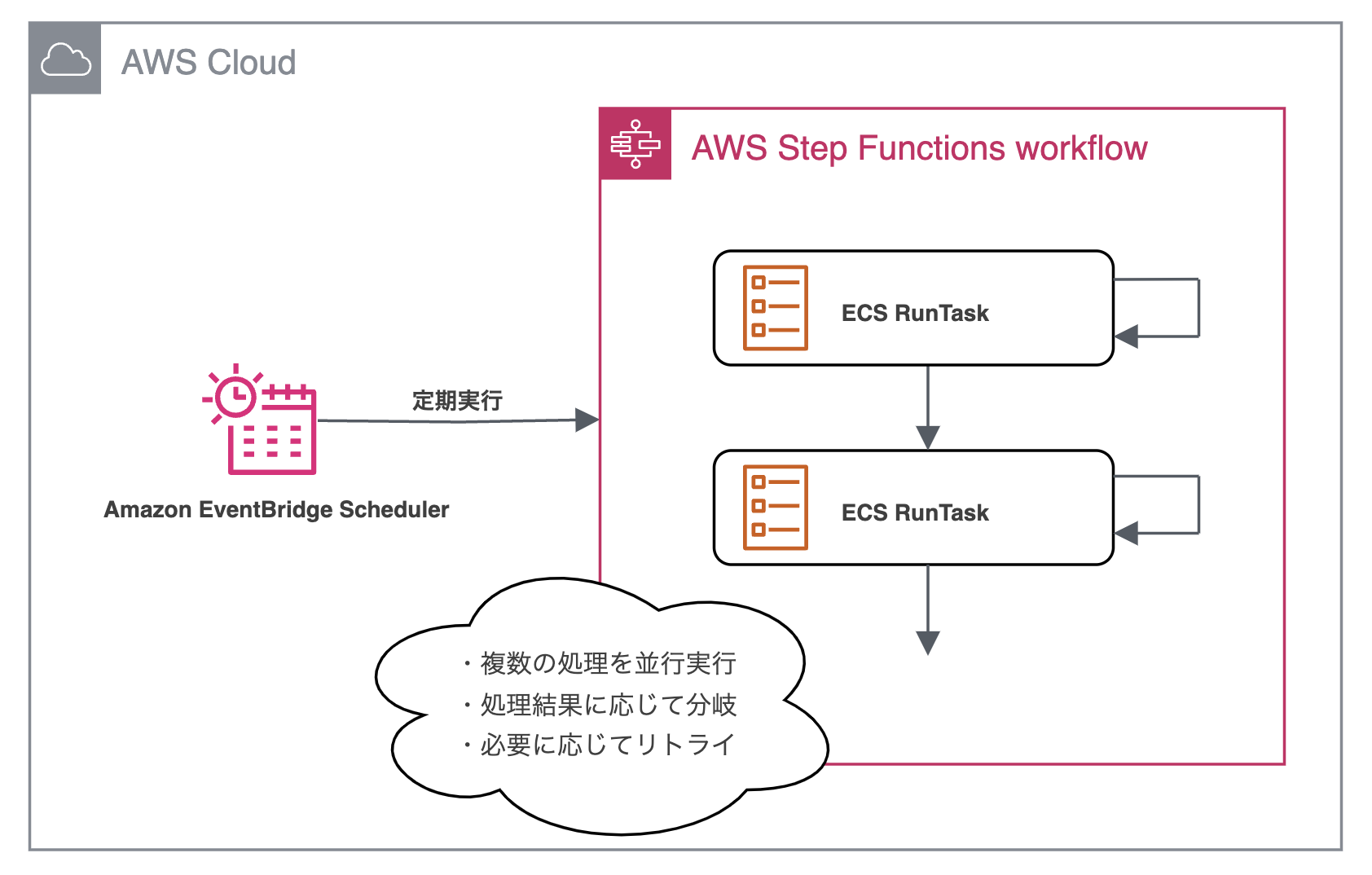
EventBridge Schedulerが定期的にStep Functionsを呼び出し、ECS Fargateが実行されます。また、再試行ポリシーも設定しています。
CloudWatchアラーム
CloudWatchアラームは、Step FunctionsのステートマシンでECS Fargateの実行が失敗した場合や、EventBridge Schedulerが一定期間実行されなかった場合に通知を送ります。 管理者はPagerDuty Incidentによって異常状態を検出することができるようになっています。
なぜECSを選んだのか
カラーミーショップではAWSを中心とするパブリッククラウドの積極的な活用を推進しています。 とくに、LambdaやECSのようなコンテナ技術やサーバレス技術をを新規コンピューティングリソースの利用先として第一に検討することで、VMの管理に伴う運用負荷を下げる取り組みを行っています。
新しい仕組みの導入にあたり、RDSの監査ログをS3に保存するための手段として、まずはLambdaを使用してPoCを実施しました。 しかし、カラーミーショップのRDSはクエリ発行頻度が非常に高く、監査ログの生成量も多いため、Lambdaの最大実行時間(15分)では処理が完了しないケースが発生するリスクがありました。 この課題を解決するため、今回のケースにおいて最大実行時間をシビアに検討する必要がないECS Fargateを採用しました。
ECS Fargateの採用により運用知見が貯まることが、新規ワークロードの実行先の選択肢が増えるという点でメリットがあると判断したことも、採用理由のひとつです。
監査ログ保全における適切なリソース管理
RDSインスタンスの監査ログを取得する際、各ECSタスクごとのログファイルの責任範囲として、以下2つが考えられます。
- 複数のRDSインスタンスの監査ログを1つのECSタスクでまとめて処理する方法
- 各RDSインスタンスの監査ログを個別のECSタスクで処理する方法
前者では、保存するログファイルの対象が複数個になるため、タスクの実行単位の処理時間がログファイルの数に対し線形に増加する問題があります。 このような問題はGoの並行処理パターンを導入し、N個のタスクを非同期的に処理することで解決しますが、 一方でメモリに一時的に保持されるログデータ量が多くなり、結果としてメモリ使用量の要求が大きくなります。 このように対象とするログファイルの数を増やすと、メモリ使用量と処理時間はトレードオフの関係にあります。
一つのECSタスクが処理するログファイルの数を増やすと、 ECSによるコンテナの起動が一時的に失敗したり、あるいはスケジュールできないタスクが生まれてしまった際に保全できないログの対象が増えることになります。 タスク単位のログファイル数を少なくすることで、同時に起動するタスクのうち一部のみが起動失敗したケースにおいて、 障害発生時に別手段による保全を行わなければいけない対象が少なくなるため、迅速に対応を完了させることができるようになります。
逆に、一つのECSタスクが処理するログファイルの数を減らすと、 ECSタスクはログファイルの変更検知によりキックされるのではなく、EventBridge Schedulerを契機とするポーリング方式を採用しているため、 そのECSタスクでログファイルを捕捉できるタイミングが少なくなることになります。 これにより、プログラムのバグや一時的な失敗によりログの完全性を担保できない可能性が高まります。
また、後者では、ECS Fargateが各RDSインスタンスに専用のリソースを割り当てて処理を行うため、メモリリソースの逼迫を抑え、安定した運用が可能です。
これらを踏まえて、新実装では一つのECSタスクが3つのログファイルを担当するように決定しました。 Goプログラムは何度実行されても同じ結果に収束するように冪等性を持った実装にし、 複数のファイルを対象に、何度も実行することで理想状態に収束するようなシステムとして設計しました。
私達のユースケースに合わせたオブジェクトキー
従来の仕組みでは、RDSの監査ログはS3保存時に分割されることで、RDSインスタンス上のログファイルと、S3上のオブジェクトが1対1に対応していませんでした。またS3上のオブジェクトは、日付ではじまるものとなっていました。具体的には <日付>/<RDSインスタンス名>-<時刻> のような形式です。
従来の形式は我々のユースケースとマッチせず、必要なオブジェクトを探し出すときに不便が生じていました。たとえば複数日にわたって特定のインスタンスのログを取得したり、RDSインスタンスに保存されていた監査ログのファイルと同じ単位で取得する場合などです。
新しい仕組みでは、RDSの監査ログをS3に保存する際に、各RDSインスタンスごとにオブジェクトパスを分け、
RDSインスタンス監査ログの最終更新日時をファイル名に含める形式に変更しました。
具体的には、保存先を<S3バケット名>/<RDSインスタンス名>/YYYY-MM-DD-HH-MM-SSとすることで、各RDSインスタンスの監査ログを分離し、
RDSの監査ログとS3に保存された監査ログファイルが一対一で対応するようにしました。
この変更により、監査対応時に特定のインスタンスのログを、日付を跨いで検索しやすくなり、利便性が向上しました。
実装と検証を繰り返しフィードバックループをまわす
本番環境で安定して運用するためには、実装を繰り返し改善し、発生した問題を一つずつ解決していく必要がありました。
以下、動作検証で発見された課題とそれにどのように解決したかを解説します。
ログが途中で途切れる
プロトタイプを開発し動作させてみたところ、ログファイルのダウンロードの際、行の途中で途切れてしまう問題が発生しました。
# 正( AWS コンソールからダウンロードした、完全なログデータ )
20241001 12:34:56,ip-xxx-xxx-xxx-xxx,test_rds_user, ...
# 誤(ログ行頭が途切れているパターン)
ip-xxx-xxx-xxx-xxx,test_rds_user, ...
# 誤(AWS RDS APIが特殊なメッセージを入れて、レスポンスするパターン)
[Your log message was truncated]
xxx-xxx,test_rds_user, ...
課題
PoCでは、RDSの監査ログを取得するために DownloadDBLogFilePortion API を使用していました。
このAPIは1リクエストあたり最大1MBまでしか取得できないという制約があります。
ログデータ全体を取得するためには、ページネーション方式で複数回のリクエストを送信する必要があります。
DownloadDBLogFilePortion APIには、Markerというオプションが用意されており、
このオプションを使用して、レスポンスに含めるログデータのオフセットを指定します。
参考: DownloadDBLogFilePortion - Amazon Relational Database Service
初期実装ではこの DownloadDBLogFilePortion APIを利用して実装していましたが、
動作検証を進めていたところ、以下のエラーを観測しました。
これはレートリミットによるものですから、閾値に触れないように待ちながら実行すれば回避できますが、待つ処理を加えると全体の処理時間が長くなる懸念があります。
DownloadDBLogFilePortion, exceeded maximum number of attempts, 3, https response error StatusCode: 400, RequestID: XXXXXX, api error Throttling: Rate exceeded
また、1MBずつデータを取得したとしても、[Your log message was truncated]というメッセージがレスポンスに含まれてしまい、正しいログデータのダウンロードができないケースを発見しました。
対策として、リクエストにはMaxLinesというパラメータも含めることができ、これを利用することで長いログでも切り詰められずにダウンロードできますが、
様々なクエリが実行されるため、ログの長さが異なりこの値を固定値で設定できませんでした。
以上の理由より、DownloadDBLogFilePortion API を使うプログラムには実装の複雑性を伴うことがわかりました。
参考:
解決
AWS コンソールからRDSの監査ログをダウンロードできることに気づき、Webブラウザの開発者ツールでどのようなAPIリクエストが送信されているかを確認したところ、
DownloadCompleteLogFile API が使われていることが確認できました。
このAPIはAWS SDKには実装されていませんが、APIドキュメントが存在します。
参考: Reading log file contents using REST - Amazon Relational Database Service
このAPIリクエストをGoプログラムから送信できるようにすることで、 プログラムの実装を簡素化し、またデータの一部欠損を防ぐことができるのではと考えました。
AWS SDKを利用せずにAPIリクエストを送信する方法は公式のブログ記事やドキュメント紹介されています。
- AWSのAPIを理解しよう!中級編 ~ リクエストの署名や CLI/SDK の中身を覗いてみる - aws.amazon.com
- API リクエストに対する AWS Signature Version 4 - docs.aws.amazon.com
これらの記事と、AWS SDKのSignature V4の実装 を読みながら実装しました。 実際のGoのサンプルコードとして、拙著のブログもありますので参考にしていただけますと幸いです。
net/httpでAWS APIにGETリクエストするときのペイロードハッシュ
実際に検証環境でRDSのログファイルをダウンロードしてみましたが、とくに時間がかかることなく成功することを確認しました。
並行運用
手元でのアドホックな動作検証だけでなく、 本番環境のRDSから発行されるイベントをもとに実行する並行運用期間を設け、システムの動作の安定性を確認しました。 この間は従来のData Firehoseベースの仕組みと混在することになるため余計なコストがかかることになりますが、 信頼性のあるシステムを実現するために必要なステップであるとし、そのコストを許容することにしました。
結果として、検証段階で見えていなかった課題が浮き彫りになってきたので、以下で紹介します。
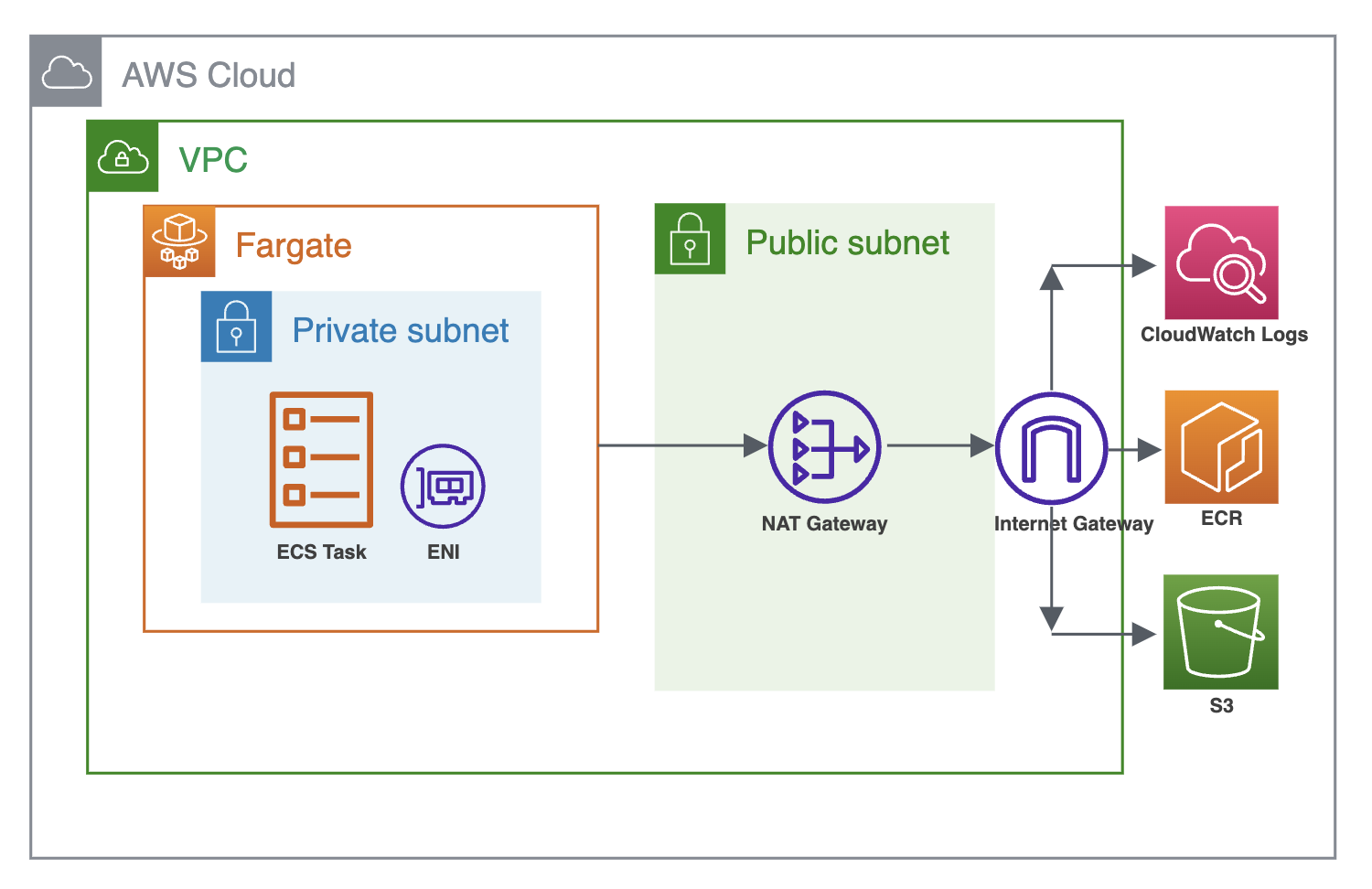
転送量のコスト増加
本番環境で継続して動作させた結果、ECRのPullやS3へのGET、PUTなどが増加し、NAT Gateway経由のトラフィックコストが増大していることが確認されました。 検証段階でもNAT Gatewayを経由する状態で動作させていましたが、タスク自体の実行頻度が低かったため顕在化していませんでした。 本番環境のRDSインスタンスに対して実行することで頻繁にタスクが起動し、それにより発見できたため、並行運用期間を設けてよかった事例の一つだと思います。
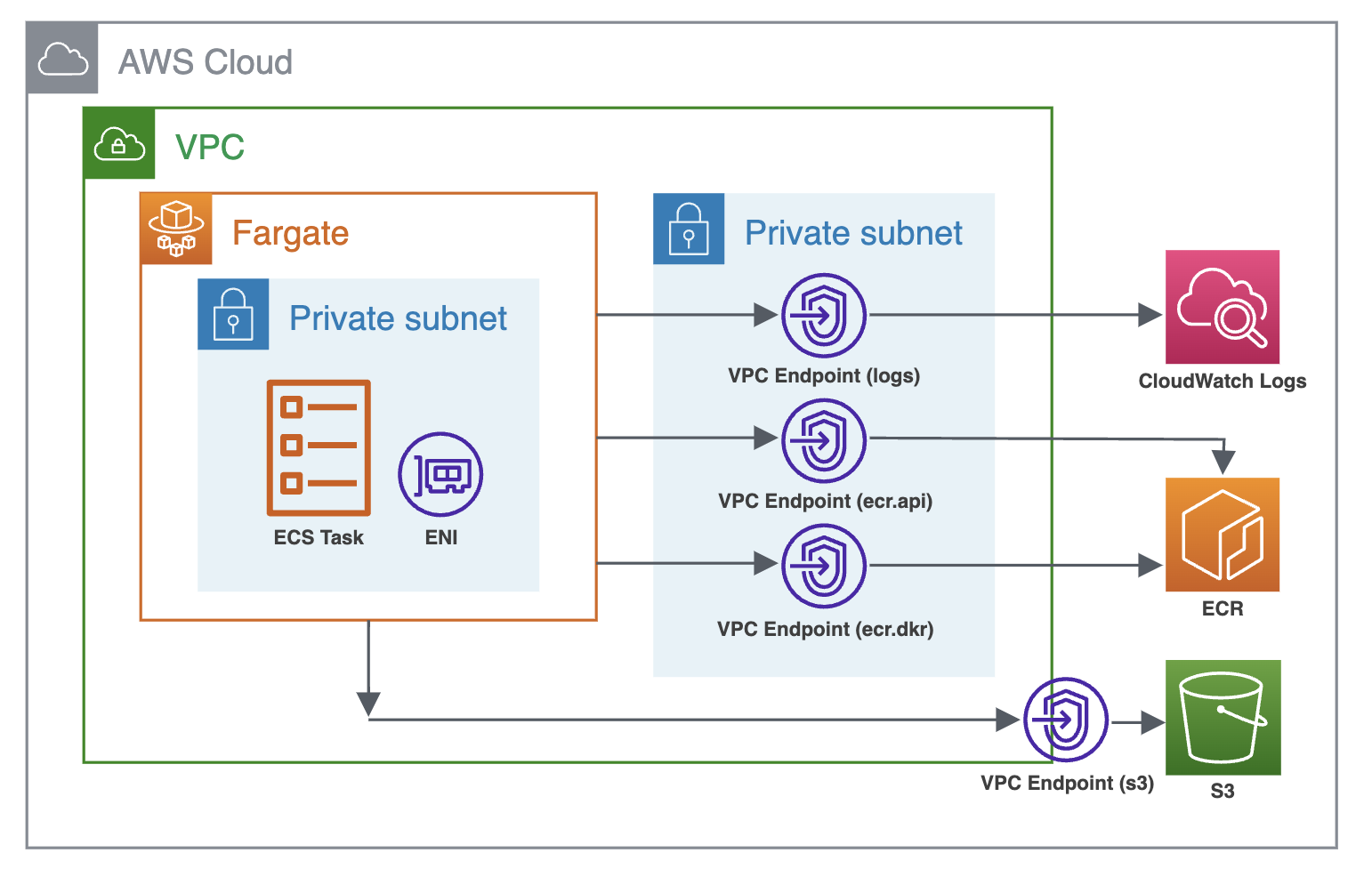
そのため、NAT Gatewayを経由しないようにVPC Endpointを作成し、ECRやS3などのサービスとの通信がVPC内で完結するようにしました。 これにより、NAT Gatewayを経由する必要がなくなり、転送量に伴うコストが削減されました。
ECS Fargateのキャパシティ不足
検証環境では実行頻度が数十分に1回程度だったため、顕在化していなかった問題として、ECS Fargateのリソース不足が挙げられます。 AWS側でタスク実行に必要なリソースが不足すると、「キャパシティ不足」というエラーが発生し、一時的にECS Fargateが起動できないことがありました。
ECS FargateではAvailablity Zone(以下AZ)ごとにリソースプールを用意しています。 検証段階では特定のAZでのみECSタスクを起動するように設定していましたが、 これを複数のAZで動作させるように変更し、リソース不足の可能性を低減するようにしました。
ログの整合性をチェック
私達のシステムではGoプログラムのエラーやその他、Step FunctionsでキャッチしたエラーによってPagerDutyに通知されますが、 実際にどのログが取りこぼされたのか、通知からは判断できません。
そのため、RDSの監査ログとS3に保存された監査ログを比較するスクリプトを実装し、どのログが取りこぼされたのかを知ることができるようにしました。 このスクリプトを実行すると、意図しないログの欠損がないかを検出できます。
以下にスクリプトが動作する様子を載せておきます。
# 正常に保存されていた場合の例
% rye run python src/check_log_missing/main.py --environment production --aws-region ap-northeast-1
YYYY-MM-DD HH:MM:SS - INFO - RDSのすべての監査ログファイルがS3に保存されているのが確認できました☕
# audit/server_audit.log.003が存在しない場合の例
% rye run python src/check_log_missing/main.py --environment production --aws-region ap-northeast-1
!!! audit/server_audit.log.003: 最終更新日時 'production-primary01/YYYY-MM-DD-HH-MM-SS' に対応するRDSログがS3に保存されていないのを確認しました !!!
YYYY-MM-DD HH:MM:SS - ERROR - 差分を検出したのでプログラムを異常終了します。colorme-rds-audit-logs-s3のCloudWatchログやオンコールのランブックを参照して対応してください。
この方法を用いることで、監査ログの欠落があった場合でも、速やかに補完できます。 このスクリプトを実行するように、後述するオンコールドキュメントを整備し、 アラート発火時のアクションを明確にしました。
ログローテーションサイズの変更
カラーミーショップの利用が増加する時間帯にログのローテーション頻度が高まり、EventBridge Schedulerの定期実行に対して過度にローテーションが起こり、 取りこぼすパターンが存在することがわかりました。
私達のサービスでは3〜4分に1回の頻度でローテーションが発生していました。 この頻度では、EventBridge SchedulerのトリガーからGoプログラムが完了するまでの時間を踏まえると、 たとえトリガー頻度を短くしてもログを取りこぼす懸念があります。 この懸念に対し、ログファイル単位のサイズを変更することで、ローテーション頻度を少なくすることにしました。 RDSの監査ログのローテーション設定では、ファイルサイズを1B〜1GBの範囲で調整可能です。
参考:
- MariaDB のログのローテーションと保持 - Amazon Relational Database Service
- MariaDB データベースエンジンのオプション - Amazon Relational Database Service
最大の1GBに設定することで、ローテーション間隔を最大20分まで伸ばすことができ、 ログを取りこぼさず確実に処理できます。 しかし、RDSにアタッチされているEBSのストレージを圧迫してしまう上、Goプログラムのメモリ使用量が増加する問題があります。 監査ログは最大100ファイル保持されるため、RDSインスタンスにマウントされたストレージのうち最大100GBが監査ログの保存に使われることとなります。我々の環境ではそれにあわせたEBSストレージの拡張が必要となり、コストも増加します。 これらを加味して、現状のRDSインスタンスの構成を変更せず、ストレージに余裕を持たせ、かつローテーション頻度を下げれるような監査ログのファイルサイズを決定しなければなりません。
結果として、監査ログのファイルサイズは400MBとし、ローテーション頻度を1/2まで下げることにしました。 変更後は、RDSのEBSストレージのFreeStorageSpaceを監視し、適切に対応できることを確認しました。 また、RDSのオプション変更やEBSストレージの追加は、いずれもダウンタイムなしで動的に適用可能であるため、この構成変更はオンラインでおこなわれました。
参考: 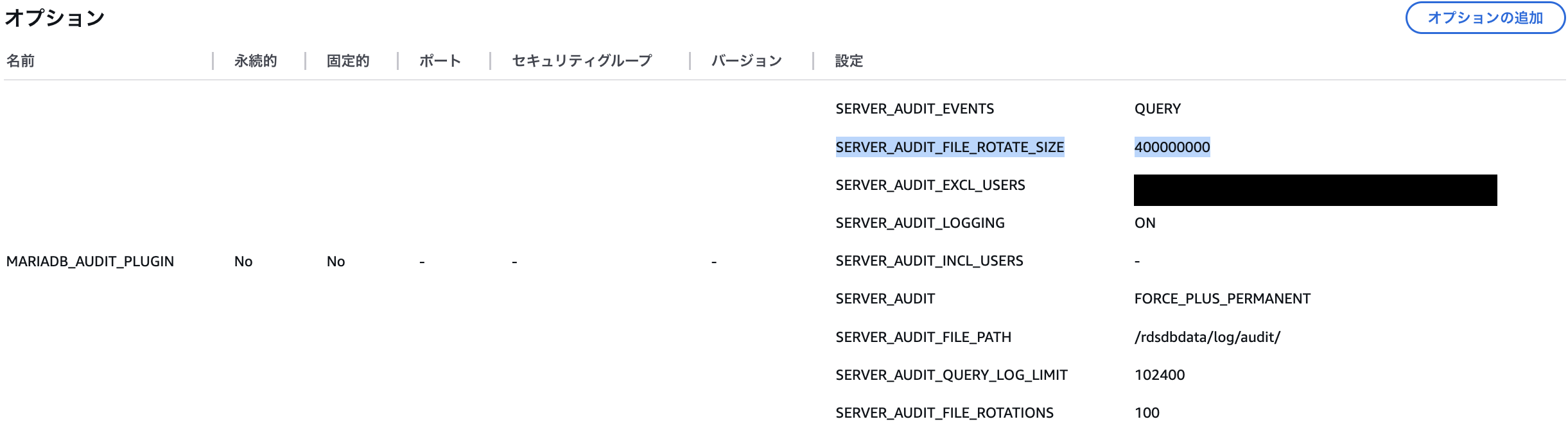
オンコールドキュメントを作成
これらの内容をオンコールドキュメントにまとめて、オンコールを受け取った担当者が対応をできるようにしました。 すべてのアクションによって復旧できなかったエッジケースでは、最終手段として従来のData Firehoseの仕組みに切り戻すことを手順に組み込んでいます。 colorme-rds-audit-logs-s3 のプログラムに問題がなく、特定のケースでECS Fargateでのみ正常に動作しなかった場合は、Goプログラムをローカルで動かせるようにしているので一時的な回復作業が実施可能になっています。
成果
今回の改善により、CloudWatchのコストは日額約90ドルから10ドル未満へと大幅に削減されました。 これまでCloudWatchのコストはS3に次いで高額でしたが、今回の変更で大幅に抑えられました。
監査対応においては、監査ファイルの検索が容易になり、運用の効率が向上しました。 さらに、この仕組みは社内の別プロダクトにも採用されることになり、RDSインスタンス以外にも、Auroraインスタンスの監査ログ取得に適用されています。
Future Works
実装したソフトウェアシステムを放置するだけでなく、継続して改善し続けることが重要です。 colorme-rds-audit-logs-s3も例に漏れず、以下の課題が存在しています。
- 保存されたログを快適に分析するための基盤が整備されていない
- DuckDBやBigQuery, Athenaのようなデータ分析基盤を利用できるようになっていない
- ECSタスクのバグを検出した際のフローが人力となってしまっている
- 先述したように監査ログのローテーションはすごいスピードで回るので、対応の緊急度が高くなってしまっている
- ECSタスクが常駐し、定期的に処理を行うループパターンの導入
- EventBridge SchedulerによってECSタスクを定期的に起動した結果、ENIの作成が定期的に行われAWS Configの追跡によるコスト増加が引き起こっている
このような課題に対し、実装したシステムを継続的に改善するループを回し続けることが重要であると考えているため、 これからも機能追加や安定性の向上に注力していきます。
まとめ
このプロジェクトは、AWSのコスト最適化を目指し、カラーミーショップの監査ログ保存の仕組みを改善するものでした。 新しい仕組みを導入することで、CloudWatchのコストを大幅に削減し、監査対応の効率を向上させることができました。
私達技術基盤グループは、サービスの信頼性を担保するために必要なことを、なんでも取り組んでいます。 今回のようなコスト削減を実施することで、ユーザの方々に対する本質的な価値提供(可用性の向上やパフォーマンスの向上、新サービスの提供など)にリソースを割くことができるようになるため、 これからも継続してこのような事例を増やしていくために、ペパボ全体で協調して取り組んでいきます。
最後に、このプロジェクトはharukinとdrumatoの二人が中心となって進めてきました。 設計の議論や意思決定においては、多くの方の協力があり、その支えがあったからこそ、ここまで形にすることができました。 ここでは、中心となって取り組んできた二人の振り返りを述べたいと思います。
harukin
2024年を通じて、AWSのコスト最適化を推進してきました。 その中でも「colorme-rds-audit-logs-s3」は、特に大きな挑戦でした。
このプロジェクトでは、要件を満たすための設計に最も試行錯誤しました。 AWSのアーキテクチャ設計やGoの実装について、チームメンバーと何度も議論を重ねる中で、 自分にはなかった視点に気づかされたり、考慮が不足していた点を補ったりすることができました。 その結果、細部まで妥協せずに作り上げることができたと思います。
AWSのアーキテクチャの実現に向けたIaC化などは、ほぼ独力で進めることができましたが、 Goの実装については、drumatoさんとのペアプロがなければ完遂は難しかったと思います。 ペアプロを通じて、Goの書き方だけでなく、ソフトウェア設計や実装における考え方を学び、幅広い知見を得ることができました。 とても貴重な経験となりました。
このプロジェクトを通じて、より多角的な視点を持ち、進める力が身についたと感じています。 ソフトウェア全般について学ぶとともに、サービス運用においてソフトウェアを活用し、課題を解決することの重要性を改めて実感しました。 今後も、中長期のプロジェクトを適切な期限内に確実に完遂し、成功事例を積み重ねられるよう、自己研鑽を続けていきます。
引き続き、SREとしてサービスの信頼性を支え、エンドユーザーファーストの視点を大切にしながら、より良いシステム運用の実現に取り組んでいきます。
drumato
本プロジェクトに対しては以下の貢献をしました。 ブログはほとんどharukinさんに書いてもらいました。
- プロジェクト全体のメンター
- インフラアーキテクチャの設計
- Goプログラムの開発/機能追加/テスト
- Pythonでのチェックスクリプトの開発
- などなど、プロジェクトを進めていくうえで生じた課題解決サポート
今回、このプロジェクトの多くの時間をペアプロ形式で実施しました。harukinさんとのペアプロは、Goの文法や書き方、実装のコツ、本番環境で動くソフトウェアを作り上げるにはどうしたらいいかなど、さまざまことを伝授する良い機会でした。今回のプロジェクトを通じて、harukinさんに0→1でソフトウェアを立ち上げることを経験してもらうことができ、無事に本番運用までやり切ってもらえたことを嬉しく思います。
このように「インフラの専門性を持ったエンジニアが、ソフトウェアを書いてサービス運用上の課題を解決する」という事例を増やしていくことが、 ペパボにおける私のミッションであると考えているため、このプロジェクトを進めている最中はとても楽しく、やりがいのあった仕事だと感じています。



