はじめに
こんにちは。2024年度新卒エンジニアのはるおつ、てつを、どすこいです。普段の事業部の開発から離れて、事業部や職種を跨いでチームを組んで、2日間かけてプロダクトを作るイベントである、お産合宿(こちらは2023年のものです)で開発したプロダクトについてブログを書きます!
今回のテーマは”配信”で、昨今伸びている配信業界にアプローチしたプロダクトを各々開発しました。
上記テーマのもとで私たちが開発したプロダクトをwaiwai-aiと名付けました。視聴者と同様にコメント投稿することで配信を盛り上げるAI botです。新規の配信者は視聴者が少なく、配信が寂しくなってしまうという課題があります。waiwai-aiが配信を盛り上げることで、新規配信者でも配信を楽しめるようにすることが目的です。
技術選定
本アプリケーションは以下のような技術を用いて実現しました。
入力部分
- pyaudio
- speech_recognition
- VB-Cable
- OBS の仮想カメラ機能
わいわいをAIで生成する部分
- Dify
- LLMマルチエージェントモデル
- ハイパーパラメータのチューニング
生成した内容の出力部分
- Slack API
- 正規表現 (Python)
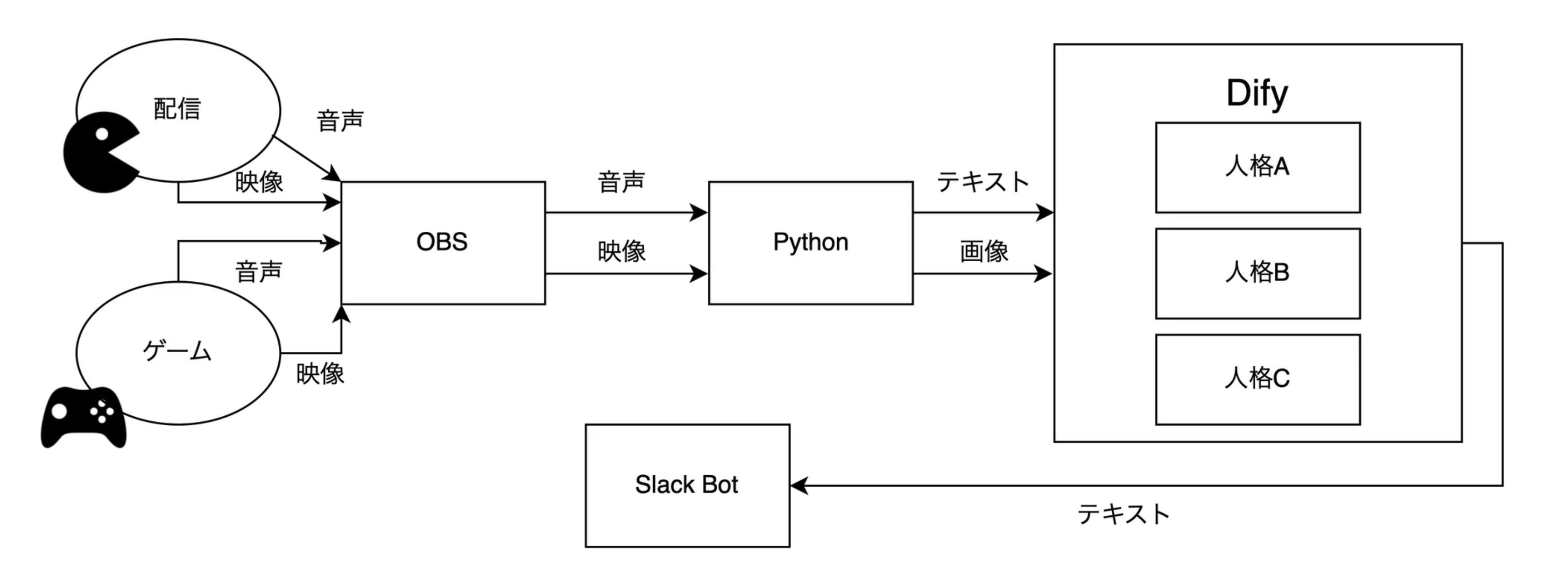
以降ではそれぞれが担当した、各コンポーネントの詳細を説明します。
任意の音声/映像から文字起こしをする技術 @てつを。
こんにちは!入力部分を担当したてつをです!!
はじめに、私が担当した waiwai-ai の「入力部分」の実装について、音声入力と映像キャプチャ機能を中心に解説します。特に、リアルタイムの音声からテキストの生成、そして映像のキャプチャ方法に至るまでのライブラリの選定理由と工夫点について触れていきます。
配信中は雑音やBGM、効果音などさまざまな音声が混在する環境であり、精度の高い文字起こしを実現するためにpyaudio、speech_recognition、そして仮想オーディオデバイスとしての VB-Cable を組み合わせ、マルチデバイス対応とノイズの多い環境でも安定した文字起こしを目指しました。 これによってOBSからの音声をリアルタイムで取得し、音声データを統合的に扱うことができます。また配信者自体は話していなくても、流れている音楽やゲーム音に対してもコメントを返してくれるようになります。 また、今回採用したwaiwai-aiのLLMは動画を入力することができなかったためOBSのモニターを画像としてキャプチャすることでLLMに読み込ませました。画像をLLMに入力することでLLMはより的確なコメントを返してくれます。キャプチャをするためのライブラリには cv2 を採用しました。
音声入力部分
音声入力部分の目的は、配信者の音声やゲーム音をリアルタイムで取り込み、それをテキスト化することです。以下のツール、ライブラリを用いて実装し、以下の順で処理していきます。
音声の取得
配信者が使用するマイクやOBSからの音声出力を取得します。これは pyaudio を使用して任意のマイクデバイスを選択し、音声を録音することで実現します。
OBSとの連携
OBSの音声出力(配信者の声、ゲーム音、BGM)を仮想オーディオデバイスとしてPythonに取り込むために VB-Cable を使用します。
- 使用ツール: VB-Cable(仮想オーディオケーブル)
音声の文字起こし
取り込んだ音声を speech_recognition を使ってリアルタイムで文字起こしします。Google Speech Recognition APIを活用し、日本語に対応しています。 以下はspeech_recognitionを使用した文字起こしのコード例です。
# 音声ファイルを文字起こしする関数
def transcribe_audio(file_path: str) -> str:
recognizer = sr.Recognizer()
with sr.AudioFile(file_path) as source:
audio = recognizer.record(source)
try:
text = recognizer.recognize_google(audio, language="ja-JP")
return text
except sr.UnknownValueError:
raise AudioError("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
raise AudioError("Could not request results from Google Speech Recognition service")
音声入力部分の処理は「音声/映像の取得 → 文字起こし → わいわいをAIで生成する部分へ渡す」のループを30秒単位で繰り返しています。
映像入力部分
映像入力部分の目的は、配信映像をキャプチャしてフレーム単位で保存することです。これにより実況中の特定のシーンを自動的に記録できます。
OBSとの連携
OBSの映像を仮想カメラ機能を使ってPythonに入力します。この仮想カメラ機能により、配信者が意図した画面レイアウトをそのまま処理可能です。
フレームのキャプチャと保存
cv2 を使用してフレームをキャプチャし、任意のタイミングで画像として保存します。30秒間隔でのキャプチャを設定しています。
import cv2
cap = cv2.VideoCapture(0)
# フレームをキャプチャ
ret, frame = cap.read()
if ret:
# スクリーンショットを保存
cv2.imwrite('screenshot.png', frame)
else:
print("フレームの取得に失敗しました")
cap.release()
わいわいをAIで生成する部分 @どすこい
こんにちは!AIが好き好き人間のどすこいです!私はわいわいを生成する部分を担当しました。ここでいう”わいわい”とは、配信を盛り上げるコメントのことです。わいわい生成部は、入力部分で受け取った配信の情報を、LLM(大規模言語モデル)アプリケーションの入力として用いて”わいわい”を生成させ、出力部に渡すことが責務となっています。
ここでは、そのLLMアプリケーションの構成について説明します。
生成AIアプリ開発基盤について
配信を盛り上げる”わいわい”を生み出すために、LLMを用いることにしました。そこで、当時少しずつ盛り上がり始めていたDifyを用いてLLMアプリを開発することにしました。DifyはオープンソースのLLMアプリ開発プラットフォームで、LLMの設定や処理、ハイパーパラメータ設定をGUI上で簡単に操作することができます。
今回の話とは別に、DifyとSlackbotの連携についてはこのブログでまとめて書いたので、ぜひみてください。 https://zenn.dev/ctk64/articles/f7e6cf44bf4be7
入力部分とのインターフェースについて
入力部分から受け取るデータは、配信者の発言内容を抽出したテキストデータを、用いることにしました。具体的には、配信者の発言やそれに関連する情報をテキスト形式で受け取ることを想定しています。この仕様を早い段階で定義したことで、わいわい生成部ではダミーデータを用いた開発が可能となり、チームメンバーが独立かつ並列して作業を進められる体制が構築できました。
また、このテキストデータはノイズ処理などをせずにそのまま用いることにしました。この判断の理由として、以下の点が挙げられます:
- 入力部分で取得されるテキストデータの精度が実証済みで十分高いこと。
- 使用するLLMアプリケーションが、ある程度のノイズを処理できる性能を有していること。
このため、入力部分から受け取ったテキストデータをそのままLLMに渡して処理する設計としました。
なお、将来的に以下の状況が生じた場合には、入力部分とわいわい生成部分の間にデータの前処理を行う仕組みが必要になると考えられます:
- 入力部分から送られるデータにノイズが多く含まれる場合。
- 使用するLLMアプリケーションがノイズに対して脆弱な場合。
出力部分とのインターフェースに関しては、別途「出力部分の仕様」で詳述します。
コメント生成部分のLLMアプリケーションについて
LLMのユーモアに関する研究はいくつかあり、その中で手軽で効果の高そうな手法を応用することにしました。それは、異なる人格のLLMをいくつか用意して、ランダムなLLMにユーモアを生成させるものです。
今回の開発では、3種類の異なるキャラクターを持つLLMを用意しました。それぞれ、 ①視聴者を積極的に褒めてくれるLLM ②状況を整理して褒めるLLM ③自分のことを面白いと思っている少し自信過剰なLLM という特徴を持たせています。
また、複数のLLMモデルを用いたマルチエージェントモデルを用いることで、単一のLLMを使うよりも人間に近いコメントを出せるように工夫しました。
コメント生成部分のハイパーパラメータのチューニングについて
さらに、LLMのハイパーパラメータを調整して、発言にランダムさを加え、配信ごとに異なるリアクションを楽しめるようにしました。これにより、視聴者が配信に参加するたびに新しい体験ができるようになっています。 LLMのハイパーパラメータは以下のような値です。詳しくはOpenAIのドキュメントも参考にみてください!
-
Temperature
応答のランダム性やクリエイティビティを制御する。 -
Top P
上位P%の確率のトークンを選択する。 -
Presence Penalty
応答内で既に使用されたトークンの再利用を抑制する。 -
Frequency Penalty
応答内で同じトークンが繰り返される頻度を抑える。 -
Max Tokens
応答に含められるトークン(単語や記号など)の最大数を指定する。 -
Seed
ランダム性の再現性を確保するためのシード値。実験のために主に利用する。
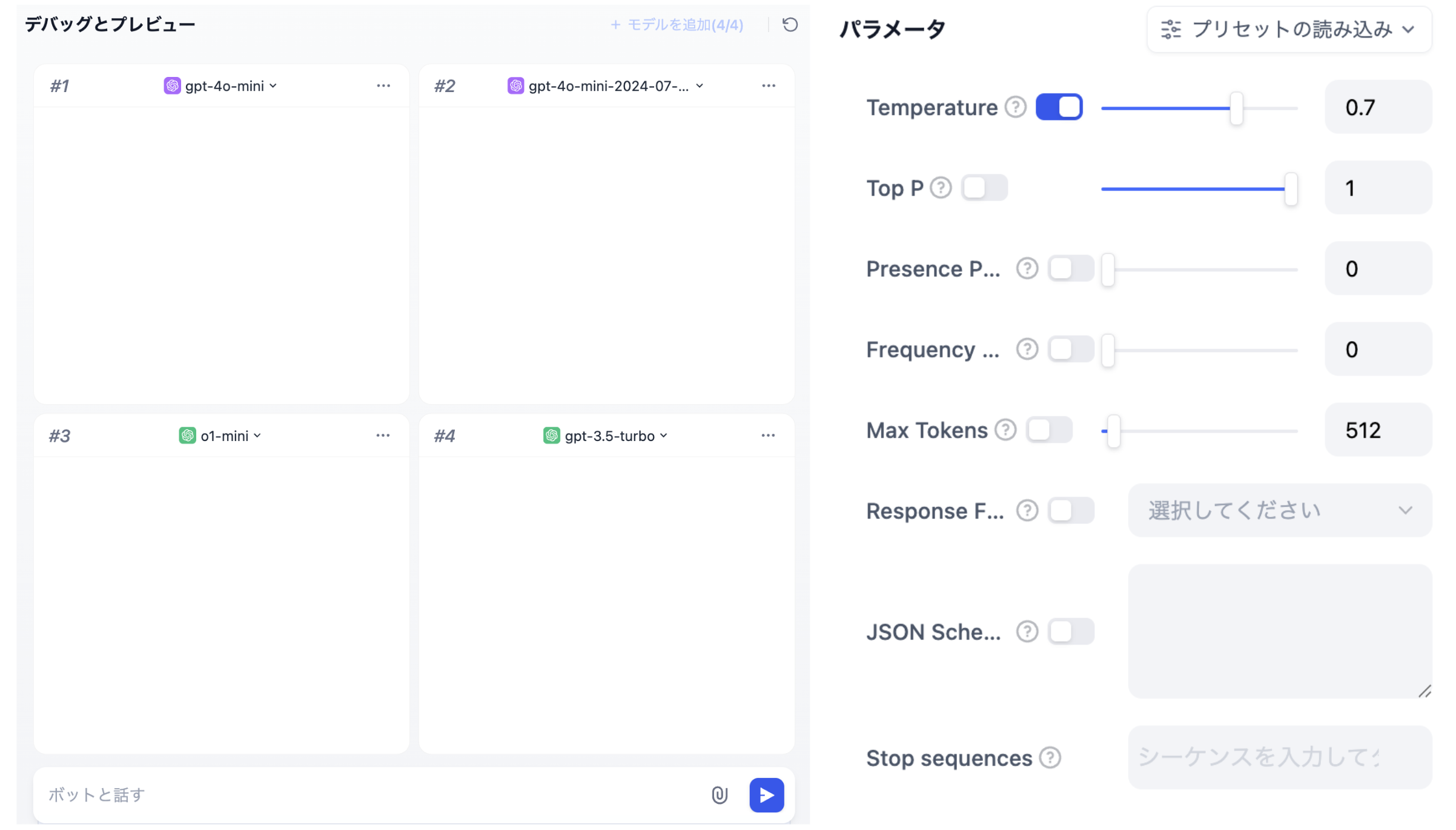
Difyでは、LLMのプロンプティングやハイパーパラメータを変えて試行錯誤する実験が非常にやりやすかったです。ChatGPTのAPIを用いた場合と比較すると、Difyでは下記の画像のように、プロンプトやハイパーパラメータのチューニングの検証が非常にやりやすく、短時間で多くの検証を行うことができました。
生成した内容の出力部分 @はるおつ
こんにちは。waiwai-aiの生成した内容の出力部分を担当したはるおつです。
今回は、AIコメントで配信を盛り上げる「waiwai-ai」の開発において、出力部分をどのように実装し、Slack APIとの繋ぎ込み、そして今後の拡張についてどのように取り組んだかをご紹介します。
実装の手順
waiwai-aiの生成した内容の出力部分を実装するにあたり、以下の3つのステップに分けて開発を行いました。
- 基本的な動作確認とデバッグを容易に行える環境を整えるため、コンソールへの出力を実装する。
- Slack APIの仕様を把握し、実際のユーザー環境での動作を確認するために、特定のチャンネルに出力する。
- ユーザーとの自然なインタラクションを実現するため、スレッドのリンクを指定して返信できる機能を実装する。
このように、段階的にタスクを分解することで、開発の進捗を管理しつつ、それぞれのステップで直面する課題を明確にしながら作業を進めました。
それでは、実際の開発について述べていきたいと思います。
コンソールへの出力
まず最初に、waiwai-aiの基本となるコンソールへの出力と、AIから出力されたコメントの受け渡し形式を検討しました。特に、チーム開発における連携のしやすさと、将来の拡張性を考慮した設計を心がけました。
実装内容
以下のようなシンプルなクラスを作成し、answers リストに含まれるコメントをコンソールに出力するメソッドを実装しました。
class Outputs:
answers: list[str]
def __init__(self, answers):
self.answers = answers
def outputConsole(self):
for answer in self.answers:
print(answer)
データ形式の設計と選択
コメントの受け渡しには様々な方法がありますが、わいわいをAIで生成するチームと密に連携し、以下のような配列(リスト)形式での渡し方を採用しました。
answers = [
"ピザと寿司と肉が好きなところ、もう最高ですね! #食べ物仲間",
"自己紹介してくれて嬉しいです!音声合成技術、すごく興味深いですね😊",
"草"
]
この配列を用いて、各コメントを順にコンソールへ出力するようにしました。この形式を選んだ理由は主に以下の3点です。
- 複数行コメントや順序付きの発言を扱いやすい
- チーム間でのデータ受け渡しがシンプル
- SlackやYouTubeなど、異なる出力先への拡張が容易
Slackの特定のチャンネルにそのまま出力する
次に、Slackの特定のチャンネルに直接出力する機能を実装しました。これは、実際のユーザー環境でコメントがどのように表示されるかを確認するための重要なプロセスです。
実装内容
Outputs クラスに outputSlack メソッドを追加し、Slack APIを利用して指定したチャンネルにメッセージを投稿できるようにしました。
def outputSlack(self):
import os
import requests
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv("SLACK_OAUTH_TOKEN_FOR_TEST")
CHANNEL = 'HOGEHOGE' # チャンネルIDを指定
headers = {"Authorization": f"Bearer {TOKEN}"}
for answer in self.answers:
url = "https://slack.com/api/chat.postMessage"
data = {
'channel': CHANNEL,
'text': answer
}
r = requests.post(url, headers=headers, data=data)
print("chat.postMessage response:", r.json())
Slack APIの設定
Slack APIを利用するために、以下のOAuthスコープを設定しました。(2024/5/30時点の設定)
Bot Token Scopes:
- channels
- @waiwai-aiが追加されたパブリックチャンネル内のメッセージやその他のコンテンツを閲覧するための権限です。スレッドの存在確認やメッセージの取得のために設定しました。
- chat
- @waiwai-aiとしてチャンネルにメッセージを送信するための権限です。
- chat.customize
- @waiwai-aiとして、カスタマイズされたユーザー名やアバターでメッセージを送信するための権限です。waiwai-aiの見た目を変えることを想定して、設定しました。
User Token Scopes:
- chat
- ユーザーに代わってメッセージを送信するための権限です。現在はbotとして表示されますが、今後ユーザーの代わりになってユーザー権限でメッセージを送信する際に使用します。
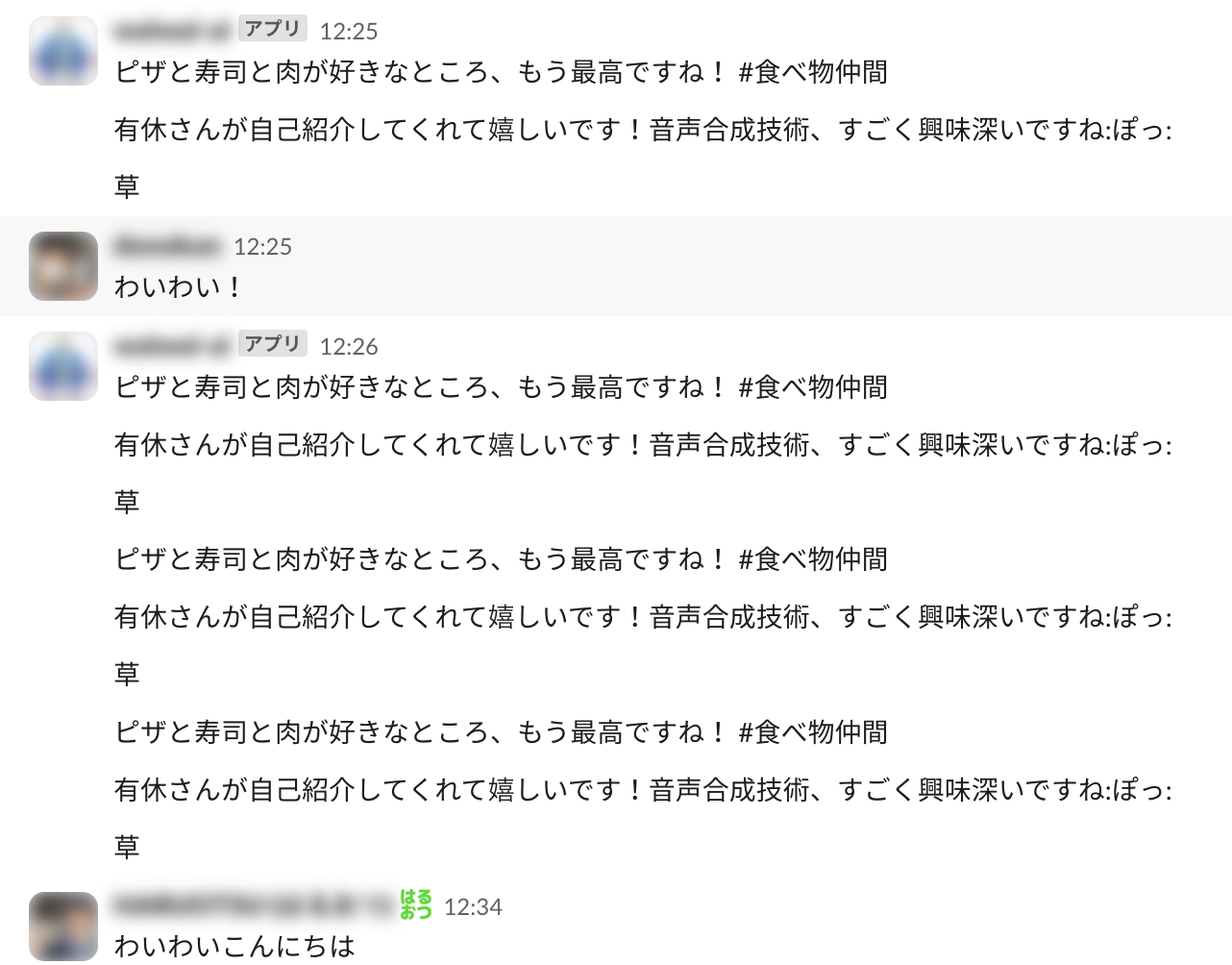
実際にSlackに出力した様子
実際にSlackに出力した様子は以下の通りです。配列で区切ったテスト用に作成したコメントが、そのままSlackに出力されていることがわかります。
Slackの特定のメッセージに対してスレッドで出力する
Slackのスレッドをリンクで指定できるように機能を拡張しました。
これにより、ユーザーはスレッドのURLを直接指定するだけで、そのスレッドに対してAIコメントを投稿できるようになりました。
実装の背景と工夫点
これまでの実装では、SlackのチャンネルIDとメッセージのタイムスタンプ(thread_ts)を個別に指定する必要がありました。しかし、ユーザーがこれらの情報を手動で取得して指定するのは手間がかかり、UXの観点から改善の余地がありました。
そこで着目したのが、SlackのスレッドURLに含まれる情報です。実は、SlackのスレッドURLの末尾には、そのスレッドのタイムスタンプが含まれており、この点を活用することでユーザーの利便性を向上させることができました。
URLから情報を抽出する方法
SlackのスレッドURLは以下のような形式になっています。
https://<workspace>.slack.com/archives/<channel_id>/p<timestamp>
ここで、
<workspace>はワークスペースの名前<channel_id>はチャンネルのID<timestamp>はスレッドのタイムスタンプ(小数点が省略された形式)
例:
タイムスタンプが 1622547803.000200 の場合、URLの末尾は p1622547803000200 となります。
このURLから以下の情報を抽出します。
- チャンネルID:
<channel_id> - タイムスタンプ:
<timestamp>を小数点を挿入して元の形式に戻す
実装内容
正規表現による情報抽出
URLからチャンネルIDとタイムスタンプを抽出するために、正規表現を使用しました。
def extract_slack_info(url):
import re
# 正規表現パターンを定義
pattern = r'https://[^/]+/archives/([A-Z0-9]+)/p(\d{16})'
match = re.match(pattern, url)
if not match:
raise ValueError("URLの形式が正しくありません。")
channel = match.group(1)
raw_ts = match.group(2)
# タイムスタンプの形式を修正(小数点を挿入)
thread_ts = f"{raw_ts[:10]}.{raw_ts[10:]}"
return channel, thread_ts
工夫点:
- 正規表現パターンの設計: ワークスペース名やドメイン部分を一般化し、どのSlackワークスペースでも対応できるようにしました。
- タイムスタンプの復元: URL中のタイムスタンプは小数点が除かれているため、適切な位置に小数点を挿入して元の形式に戻す必要があります。
- 具体的には、16桁の数字のうち、最初の10桁が秒、残りの6桁がマイクロ秒を表しているため、
raw_ts[:10] + '.' + raw_ts[10:]の形で復元します。
- 具体的には、16桁の数字のうち、最初の10桁が秒、残りの6桁がマイクロ秒を表しているため、
outputSlack メソッドの修正
抽出したチャンネルIDとタイムスタンプを用いて、指定したスレッドにメッセージを投稿します。
def outputSlack(self, url: str):
channel, thread_ts = extract_slack_info(url)
TOKEN = os.getenv("SLACK_OAUTH_TOKEN")
headers = {"Authorization": f"Bearer {TOKEN}"}
for answer in self.answers:
data = {
"channel": channel,
"text": answer,
"thread_ts": thread_ts
}
response = requests.post("https://slack.com/api/chat.postMessage", headers=headers, data=data)
print("Response:", response.json())
使用例
answers = ["素晴らしいアイデアですね!", "その点については賛成です!"]
h = Outputs(answers)
h.outputSlack('https://yourworkspace.slack.com/archives/C01ABCDEF/p1622547803000200')
このように、スレッドのURLを引数として渡すだけで、該当するスレッドに対してメッセージを投稿できるようになりました。
まとめ
以上が、waiwai-aiが生成した内容の出力部分を実装する際の各ステップとその背景、具体的な実装内容になります。段階的に機能を拡張することで、開発効率を高めつつ、ユーザー体験の向上を図ることができました。
結果
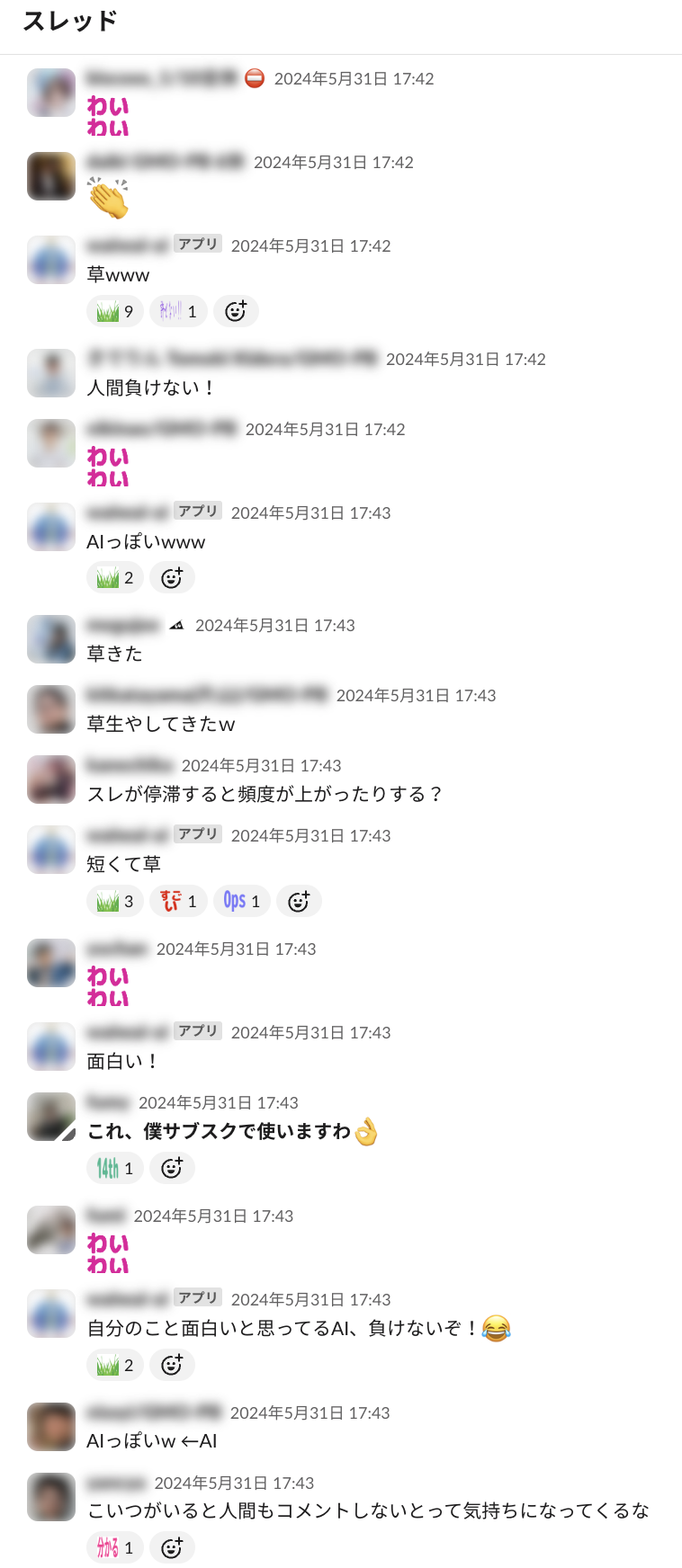
waiwai-aiを導入した結果、Slackのやり取りは大いに盛り上がりを見せました!画像にあるように、AIが生成したコメントが、視聴者のリアクションを引き出し、自然な会話の流れを作り出しています。例えば「なるほどw」や「AIっぽいwww」といったリアクションが飛び交い、AIがまるで本当の参加者のように受け入れられている様子が伺えます。
「人間もコメントしないとって気持ちになってくるな」という声が示すように、AIが視聴者のコミュニケーションを自然に促し、会話に活気を与えていることが大きな成果です。結果的に、わいわいAIは新規配信者でも視聴者とのやり取りが弾む楽しい配信空間を作り出すことができました。
感想
どすこい
自分たちがおもしろいと思えるプロダクトを開発できたこと、チームでわいわいかつ本気で開発できたこと、先輩エンジニアのすごさを目の当たりに体験できたことがとても勉強になりました!来年がすでに楽しみです!
はるおつ
それぞれが、それぞれの得意を活かして開発できたことがとても良い体験でした。チーム開発ならではの速度感や意見のぶつけ合いを研修の一環で経験できたことは大きな糧となりました。現時点で来年は何をつくろうかな。こんなのが面白いかな。のようなことを考えていて、次のお産合宿がとても楽しみです。
てつを
誰かと一緒にゲームがしたい、コメントを盛り上げてほしい。普段ゲームをしながら考えていたことを形にしました。やっぱりチーム開発、かつ0からプロダクトを作るのは本当に楽しいなと改めて感じ、各々の強みを活かして最高のものができました。業務でも、お産合宿のような熱量とこの楽しさを常に持って取り組みたいなと思いました!