
はじめに
こんにちは、私はminne事業部でwebアプリケーションエンジニアをしている、kazuです。(過去の執筆記事はこちら)
minneでは、購入者が作品検索をする際に利用する検索機能を、OpenSearchを使って実装しています。また、searchkickというgemを使って、OpenSearchを扱いやすくしています。
そして今回、購入者が触る画面ではなく、作家・ブランドが自身の作品を管理する管理画面(以下、「作品管理画面」と呼称します)において、キーワードや作品IDで検索できる機能を実装しました。今回は、その機能の実装について紹介します。

何を伝えるものか
作品管理画面で検索機能を実装する際に、どのようなことを考えたか、どのような実装をしたかを伝えたいと思います。
その際につまづいた点にも言及し、その解決策を紹介します。
まずOpenSearchとは何か
OpenSearchはオープンソースの検索・分析スイートであり、データストア・検索エンジンであるOpenSearchと、データの可視化を可能にするOpenSearch Dashboardsから構成されています。
ref: 『Amazon OpenSearch Serverless -AWS Black Belt Online Seminar- p8』
また、minneでは、主に作品データの検索用途でOpenSearchを利用していますが、サービスのメトリクスやログなどをOpenSearchに格納する用途もあります。そうすると、OpenSearch Dashboardsを利用して、メトリクスの可視化を行うことができます。
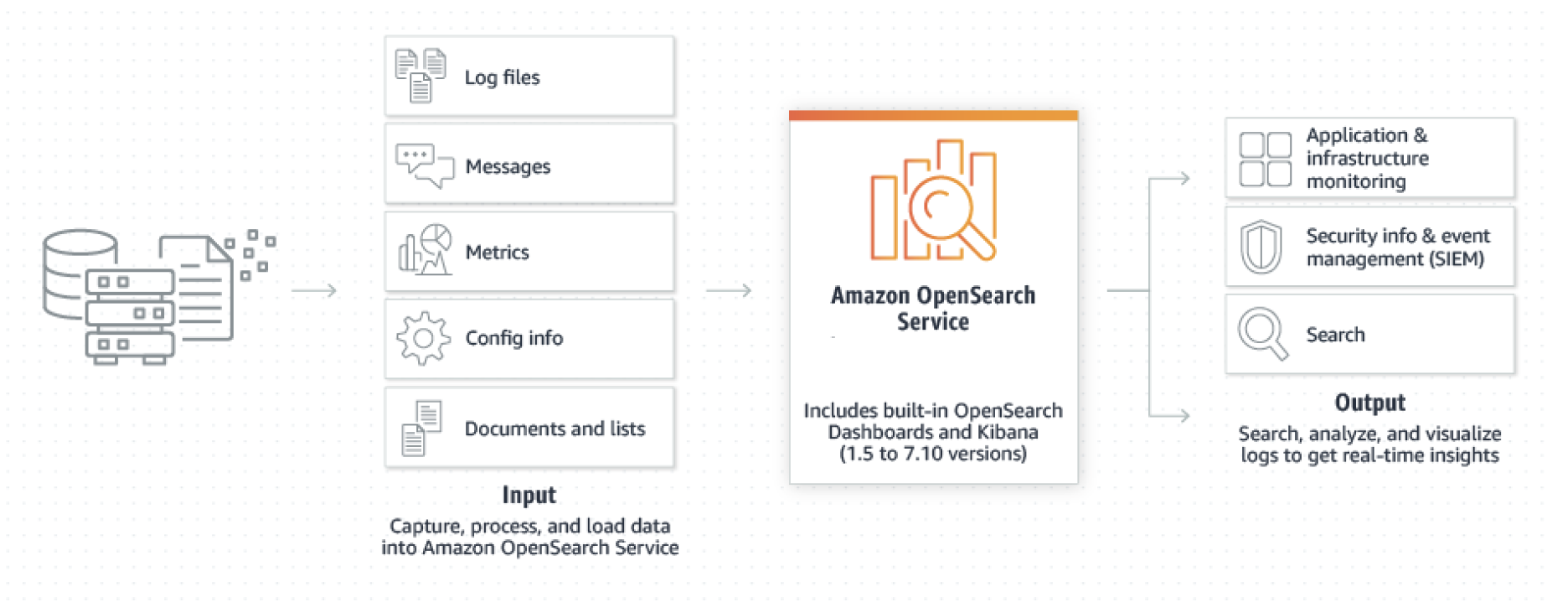 ref: 『Amazon OpenSearch Service とは?』
ref: 『Amazon OpenSearch Service とは?』
作品管理画面に検索機能をつける上で必要だったこと
前提となる知識
OpenSearchに触れる上で、基本知識として以下のことを知っておく必要があります。
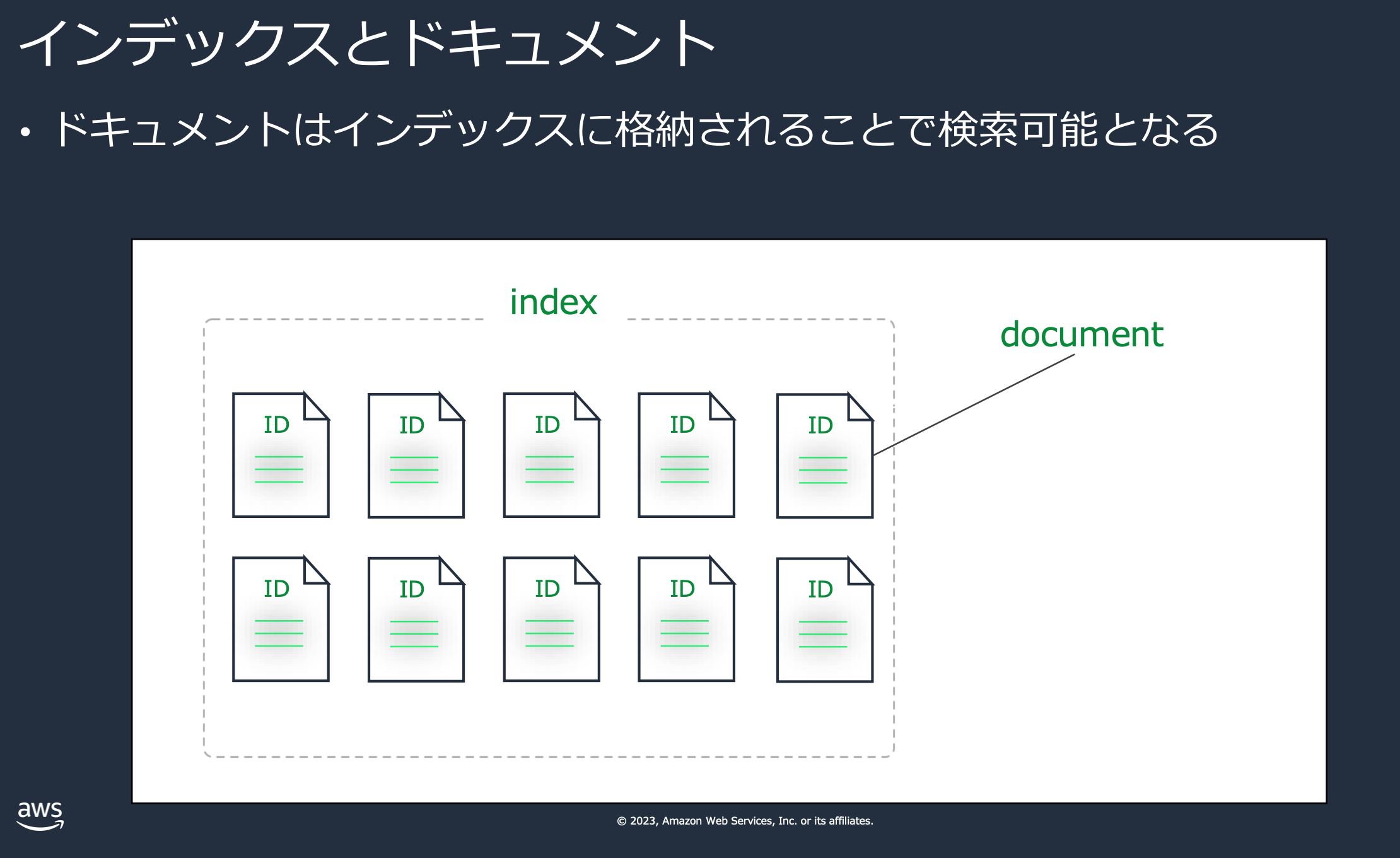
- document
- OpenSearchに格納する1つの文章の単位を、ドキュメントと呼びます。これは、RDBでいうところのレコードのようなものと解釈して良いです。
- field
- ドキュメント内の項目名(key)および値(value)の組みをフィールドと呼びます。これは、RDBでいうところのカラムのようなものと解釈して良いです。
- mapping
- フィールドについて、どのような形式で値を格納するか、について定義するものをマッピングと呼びます。これは、RDBでいうところのスキーマのようなものと解釈して良いです。
- index
- ドキュメントを保存する場所のことをインデックスと呼びます。これは、RDBでいうところのテーブルのようなものと解釈して良いです。
以下は、AWSが発表している資料(それぞれ、p11・p12)から引用 AWS Black Belt Online Seminar

minneにおけるindexの設計
前提知識を踏まえた上で、minneにおけるindexの設計について説明します。
minneにおいて、作品は「公開」(この中で更に「販売中」作品、「展示」作品に分類される)・「限定公開」・「非公開」というステータスを持ちます。そして、その作品を格納するためのindex(以下ではProduct indexと呼称します)を運用していました。
これまで提供していた購入者向けの作品検索機能においては、公開作品のみが検索対象であるため、Product indexには、公開作品のみが格納されていました。
しかし、作家・ブランドが利用する作品管理画面での検索機能においては、公開作品だけでなく、限定公開作品や非公開作品も検索できる必要があります。そのため、Product indexには、公開作品だけでなく、新たに限定公開作品や非公開作品も格納する必要がありました。
何をしなければいけなかったか
1. 作品の状態を示すstatusfieldを、Product indexに追加する
まず、Product indexの設計について、1つのindexに2つの役割(購入者による作品検索、作家・ブランドによる作品管理画面での検索)を担わせるか、役割ごとにindexを分けるか、という問題がありました。
1つのindexを共用のものとすることで、シーンごと(購入者が検索するシーンなのか、作家・ブランドが作品管理画面で検索するシーンなのか)にどの作品が検索可能であるかという点に細心の注意を払う必要が生じます。一方で、2つのindexに分けるアプローチでは、2つのindex間のデータの一貫性を確保するための運用コストが上昇すること、そしてindex間で重複するデータ(公開作品については、購入者も作家・ブランドも検索できる必要があるので、どちらのindexにおいても公開作品を保持しておく必要がある)が生まれてしまうのでその分冗長なデータが増えてしまうことが懸念されました。
結論としては、シーンごとにどの作品が検索可能であるかという点に細心の注意を払なければいけないという点を受容し、1つのindexを共用のものとすることにしました。2つのindexに分けるアプローチによる運用コストの上昇の方が避けたいことであり、また既存のindexをそのまま利用することでより速く価値を提供できると判断したためです。
そこで、購入者が非公開作品や限定公開作品を検索できないようにするため購入者に対しては公開作品のみ検索時に取得できるようにしないといけませんでした。となると、非公開・限定公開作品と公開作品を見分けるための目印となるデータが各作品に必要です。
よって、今回、新たにProductのindexに、statusというfieldを追加し、作品の状態を示す値を格納する必要がありました。
2. デフォルトの検索対象を公開作品にする
最も避けなければならないことは、公開されてはならない情報を含む非公開作品・限定公開作品が、購入者にとって検索可能な情報となってしまうことです。
故に、Searchkickを使いOpenSearchにリクエストを送る際に明示的に非公開作品・限定公開作品を示すstatusを指定しない限り、公開作品のみ検索結果のレスポンスとして得られるようにする必要がありました。そうすることで、うっかり非公開・限定公開作品が検索結果に含まれることを防ぐことができます。
悩んだこと
新たにProductのindexにstatusfieldを追加する際に、full reindexをする必要があるか
full reindexとは、既存のindexに格納されている全てのドキュメントを、新たなindexにコピーする動作のことをいいます。通常、旧indexは削除されます。
searchkickでは、以下のようにしてfull reindexをすることができます。
Product.reindex
今回、新たにProductのindexにstatusfieldを追加する際に、full reindexをする必要があるかどうかを悩みました。なぜ悩んだかというと、searchkickのREADMEにおいて、以下のように書かれていたためです。ref: To Reindex, or Not to Reindex
Reindex
- change the search_data method
すなわち、新たにmappingを追加するということは、search_dataメソッドに新たなfieldを追加することになります。そのため、full reindexが必要になるのではないかと考えました。
結論としては、必ずしもfull reindexをする必要はありません。indexのサイズが大きい場合、full reindexには少なからず時間がかかるため、full reindexをすることなく、新たなfieldを追加することができれば嬉しいですよね。以下では、update mapping APIを用いて、新たなfieldを追加するアプローチについて説明します。
踏むべきステップとしては以下の通りです。
- 既存のindexに対して、新たなmappingを追加するためにupdate mapping APIを叩く。
PUT /sample-index/_mapping
{
"properties": {
"status": {
"type": "long"
}
}
}
# もし成功すると以下のようなレスポンスが返ってくる
{
"acknowledged": true
}
- アプリケーションコードにおいて、mappingを定義している箇所にも、新たなfieldを追加する。
mappings: {
properties: {
status: { type: 'long' }, # ←追加
description: { type: 'text' },
search_dataメソッドに新たなfieldを追加する。これによって、このfieldにどんな値を挿入するかを定義することができる。
def search_data
{
status: status, # ←追加
description: description
}
end
statusfieldについてpartial reindexを行う。これによって、新たなfieldに値を挿入することができる。
fieldを追加する際には、必ずしもfull reindexをする必要はありません、と上で述べました。しかし、既存のfieldを削除する際には、full reindexが必要です。
この理由は、そもそもOpenSearchとして、fieldを追加・更新するためのupdate mapping APIは用意していますが、fieldを削除するAPIは用意していないためです。
また、3で言及したpartial reindex以外にも、既存のdocument群をindexし直すアプローチ(searchkickが提供する、bulk_indexというメソッドを用いることで可能です)もあります。 bulk_indexは、全てのドキュメントの全てのfiledについて更新する一方で、partial reindexは、全てのドキュメントの一部のfieldについて更新するため、partial reindexの方が高速です。
故に、どちらのアプローチでもfieldを追加することはできますが、partial reindexの方が高速であるため、要件には依るものの、単純に新規追加したfieldに値を挿入するためであるならば、partial reindexを利用する方がおすすめです。以下はsearchkickのREADMEから抜粋した、実装イメージです。
class Product < ApplicationRecord
def search_data
{
name: name,
category: category
}.merge(prices_data)
end
def prices_data
{
price: price
}
end
end
Product.reindex(:prices_data)
ちなみに、上ではfieldを新規追加する場合のことについて書きましたが、既存のfieldに新たにmulti field(ある1つのfieldについて、複数の解析方法の定義を可能にするもの)を追加する場合については、また別途注意すべきことがあるので、興味がある方はぜひ2023年のアドベントカレンダーに私が書いた記事(『mappingにてとあるfieldにmulti fieldを追加をした後、partial reindexではなぜ期待する挙動が得られないか』)をご覧ください。
新しく非公開作品および限定公開作品をindexに追加するにあたり、ストレージを追加する必要があるか
もし、OpenSearchに非公開作品および限定公開作品を追加する際に、ストレージが足りなくなってしまったら、購入者が使用する検索機能に支障が出てしまいます。minneは多くの方に利用されているサービスであるため、このようなことは避けなければいけませんので、ストレージが足りるかどうかは慎重に検討しました。
具体的な調査方法について、OpenSearchでは、任意のindexについて統計情報を確認するためのAPI(Stats API)が用意されているため、それを利用しました。
例えば、以下のようにcurlを使って確認することができます。
curl your-domain/your_index_name/_stats?pretty=true
レスポンスはjson形式で得られます。例えば、以下のようなレスポンスが返ってきた場合、indexに格納されているdocumentの数は123,456件で、サイズは87,654,321バイトであることがわかります。
"total" : {
"docs" : {
"count" : 123456,
},
"store" : {
"size_in_bytes" : 87654321,
},
}
合計のdocument数とindexのサイズが把握できるので、1documentあたりのおよそのサイズを計算することができます。 よって、今回indexに追加したい非公開作品と限定公開作品の合計レコード数を計上し、およそあとどれくらいのストレージ容量が必要になるかを計算しました。
1documentあたりのおよそのサイズ * (非公開作品と限定公開作品の合計レコード数) = 必要なストレージ容量
AWSコンソール上にて、OpenSearchの空きストレージ容量は確認でき、必要になるストレージ容量と空きストレージ容量を比較し十分なストレージ容量が確保されていることを確認しました。
最後に
今回は、作品管理画面に検索機能を実装した際に、何をして、どんな悩みがあったかを紹介しました。振り返ってみると複雑な道のりに見えないのですが、当時はOpenSearchあるいはsearchkickについて明るくなく、fieldを1つ追加するだけでも、full reindexが必要なのかどうか、といったことについて悩んでしまっていました。
しかし、今回の実装を通して、OpenSearchやsearchkickについての理解を深めることができ、fieldを新規で追加する際に取ることのできるアプローチや、新たに多くのdocumentをindexに載せるようにする際に確認すべきことについて学ぶことができました。
これからも、作家・ブランドが快適に作家活動に専念して、作品を作り続けられるように、サービス改善を続けてまいります!
読んでくださってありがとうございました!

