
こんにちは!SUZURI事業部デジタルコンテンツチームのyukunです。
最近、SUZURIの一部の機能に使っているNode.jsのアプリケーションが重くなりエラーやタイムアウトが頻発するという事象が起こりました。 そのアプリケーションはpuppeteerを使ってHTMLのスクリーンショットを撮りPNG画像として返すExpressサーバーです。
しかし、開発環境やステージング環境では動作していたので、原因はコードの変更によるものではなく、アクセス数の増加によるものだと推測しました。 まずは、水平スケーリングを行いコンピューティングリソースを増やすことを検討しましたが、アプリケーションの処理自体はそんなに遅くないはずだと思い最適化を試みました。
Node.jsのプロファイリングツールの0xとChatGPTを活用して、数時間で重い処理を特定してレスポンスを2倍速くする改善ができたので紹介します!
この記事はGMOペパボエンジニア Advent Calendar 2023の9日目になります🎄
おもしろい記事がたくさんあるので、ぜひご覧ください!!
測定ツールの紹介
今回の対象のアプリケーションはあまり積極的に開発されているものではなかったので、自分は内部の処理について詳しくありませんでした。 そこで、コードを読み始めるのではなく、どの処理が重い原因になっているのかを突き止めるために計測をすることにしました。
まずは使った2つのツールを紹介します。
heyでベンチマーク
hey はApacheBenchのようなURLに対してリクエストをして負荷をかけたり、レスポンスを測定してくれるCLIツールです。 使い勝手や測定結果が見やすいことから個人的に好んで使っています。
GitHubリポジトリ: https://github.com/rakyll/hey
例えば、次のようなコマンドで100回のリクエストを50並列で引数に渡したURLに対してリクエストを送ることができます。また、実行結果を集計して、レスポンスタイムやステータスを分かりやすく表示してくれます。実際の測定結果はベンチマークの項目に示します。
$ hey -n 100 -c 50 http://localhost:4000/image.png?id=123456
0xでプロファイリング
今回のアプリケーションは本番環境にDatadogやNewRelicなどAPMを導入していなかったので、開発環境でプロファイリングを計測してフレームグラフを表示できるツールを探しました。 Node.jsの公式ガイドのフレームグラフのページで 0x というパッケージが簡単に使うことができると紹介されていたので採用しました。
https://nodejs.org/en/guides/diagnostics-flamegraph#use-a-pre-packaged-tool
GitHubリポジトリ: https://github.com/davidmarkclements/0x
簡単に使い方を紹介すると、npmでグローバルにインストールし、計測対象のJavaScriptのファイルを node コマンドの代わりに 0x を指定するだけです。
$ 0x index.js
この状態でNode.jsのアプリケーションが実行されているので、何度か計測したい対象にアクセスを繰り返し、実行を止めます。コマンドを実行したディレクトリに、計測された結果のjsonやフレームグラフを表示するためのhtmlファイルが出力されます。これをブラウザで開くことでフレームグラフの表示と、拡大や表示対象の絞り込みなどの操作ができます。 実際の画像は次の項目に示します。
アプリケーションのパフォーマンスを計測する
重い処理を特定する
実際に0xでアプリケーションを実行しながら、heyでベンチマークをかけます。ここでheyを使いベンチマークをするのは計測という意味ではなく、手動でやるよりもプロファイラーの改善の前後の比較をより正確にするためです。
今回のアプリケーションはTypeScriptで書かれているためJavaScriptにプリコンパイルした上で実施します。また、0xの結果が保存されるディレクトリ名がデフォルトでPIDとなっており、複数回やると分かり辛いので --output-dir オプションで任意の名前を指定します。また、 -o オプションをつけることで、計測後にブラウザで計測したHTMLファイルを開いてくれます。
$ 0x --output-dir before -o dist/index.js
🔥 Profiling::1 - - [28/Nov/2023:06:53:59 +0000] "GET /iamge.png?id=1234 HTTP/1.1" 200 117609
::1 - - [28/Nov/2023:06:54:00 +0000] "GET /iamge.png?id=1234 HTTP/1.1" 200 117609
::1 - - [28/Nov/2023:06:54:00 +0000] "GET /iamge.png?id=1234 HTTP/1.1" 200 117609
::1 - - [28/Nov/2023:06:54:01 +0000] "GET /iamge.png?id=1234 HTTP/1.1" 200 117609
::1 - - [28/Nov/2023:06:54:01 +0000] "GET /iamge.png?id=1234 HTTP/1.1" 200 117609
::1 - - [28/Nov/2023:06:54:02 +0000] "GET /iamge.png?id=1234 HTTP/1.1" 200 117609
::1 - - [28/Nov/2023:06:54:02 +0000] "GET /iamge.png?id=1234 HTTP/1.1" 200 117609
::1 - - [28/Nov/2023:06:54:03 +0000] "GET /iamge.png?id=1234 HTTP/1.1" 200 117609
::1 - - [28/Nov/2023:06:54:03 +0000] "GET /iamge.png?id=1234 HTTP/1.1" 200 117609
::1 - - [28/Nov/2023:06:54:04 +0000] "GET /iamge.png?id=1234 HTTP/1.1" 200 117609
🔥 Flamegraph generated in
file:///Users/yukun/dev/node-app/before/flamegraph.html
ここで生成されたフレームグラフは次のようになりました。右上の凡例にあるように重い(hotな)処理ほどピンク色で表示されます。
しかし、大量に処理が積み上がっており重い処理を探すのが困難です。ここで便利な機能があり、下の方にある「app」や「deps」というボタンを操作することでグラフに表示するコードの対象を切り替えることができます。
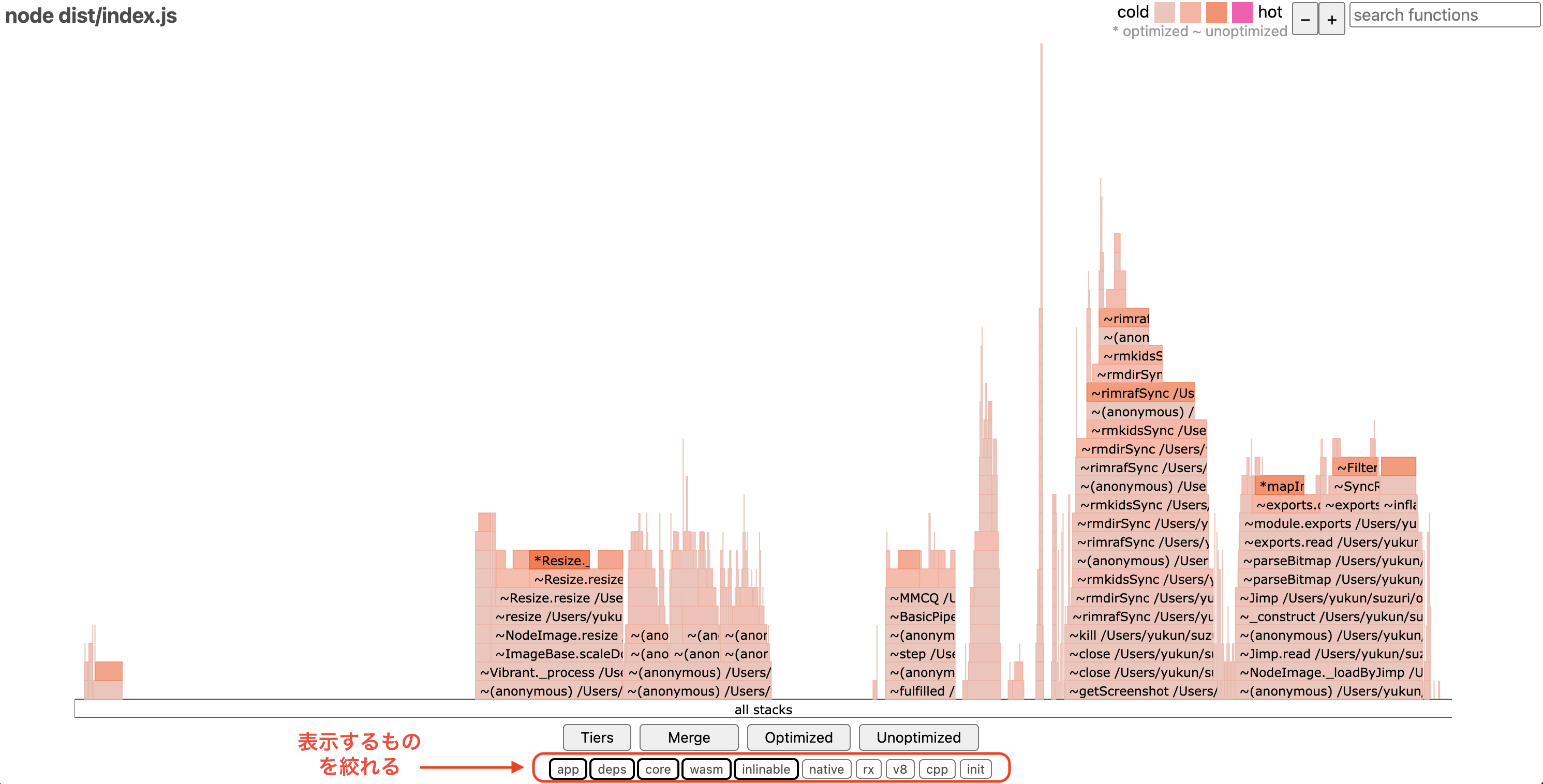
依存パッケージである「deps」の表示をオフにした結果が以下のグラフです。一気にシンプルになり、実際のアプリケーションの重い処理が一目瞭然になりました。ここでは browser.js に記述してある getScreenshot という関数の実行時間が長く、ピンク色になっていることから、重い処理であると特定できます。

重い処理を改善する
ChatGPTにやってもらう
重い処理の関数が判明したので、とりあえずそのコードを用いてChatGPT(GPT-4)と以下のようなやりとりをしました。
自分:
nodejs, Express, puppeteerを使って、スクリーンショット画像を返すWebサーバーを開発しています。CPUの使用時間が少なくなる様に最適化してください。
import puppeteer, { Browser } from 'puppeteer'
export async function getScreenshot(html: string) {
let browser: Browser
let screenshot: string | void | Buffer
const args = [
'--enable-font-antialiasing',
'--no-first-run',
'--no-sandbox',
'--no-zygote',
'--disable-gpu',
'--disable-dev-shm-usage',
'--disable-setuid-sandbox',
'--single-process'
]
try {
browser = await puppeteer.launch({ args })
const page = await browser.newPage()
await page.setViewport({ width: 1200, height: 630 })
await page.setContent(html)
screenshot = await page.screenshot()
} finally {
if (browser) {
await browser.close()
}
}
return screenshot
}
ChatGPT:
Node.js、Express、およびPuppeteerを使用したWebサーバーでスクリーンショット画像を効率的に取得するために、いくつかの最適化を行うことができます。以下に、パフォーマンス向上に役立つ提案をいくつか挙げます。
ブラウザの再利用: 現在のコードでは、getScreenshot関数が呼び出されるたびに新しいブラウザインスタンスが作成されています。これはCPUとメモリの使用率を増加させる要因となります。ブラウザインスタンスを再利用することで、リソースの使用量を減らすことができます。
キャッシュとリソースの制限: PuppeteerはデフォルトでWebページのキャッシュやその他のリソースをロードしますが、これらはスクリーンショット取得時には不要です。page.setCacheEnabled(false)を使用してキャッシュを無効化し、不要なリソースのロードを回避します。
ページの設定の最適化: ページのビューポートやその他の設定は、必要最小限に保つことが重要です。例えば、スクリーンショットのサイズが小さければ小さいほど、処理にかかる時間とリソースが少なくなります。
同時実行の制御: 多数のリクエストが同時に発生した場合、サーバーのリソースが枯渇する可能性があります。リクエストの同時実行数を制限することで、サーバーの安定性を保つことができます。
以下に、上記の提案を取り入れた改良版のコード例を示します。
import puppeteer, { Browser } from 'puppeteer'
let browser: Browser
async function getBrowserInstance() {
if (!browser) {
const args = [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-gpu',
'--disable-dev-shm-usage',
'--single-process',
// その他の必要な引数
]
browser = await puppeteer.launch({ args })
}
return browser
}
export async function getScreenshot(html: string) {
const browser = await getBrowserInstance()
const page = await browser.newPage()
await page.setCacheEnabled(false)
await page.setViewport({ width: 1200, height: 630 })
await page.setContent(html)
const screenshot = await page.screenshot()
await page.close()
return screenshot
}
このコードでは、ブラウザインスタンスを再利用し、ページのキャッシュを無効化しています。また、各リクエストで新しいページを作成し、スクリーンショット取得後にはそのページを閉じています。これにより、リソースの使用効率が向上します。
4つの改善の提案と改良後のコードを示してくれたので、アプリケーションコードを関数を置き換えた結果、特に問題なく動作していました。
ただ、puppeteerの起動の際に指定するオプション args の項目が少なくなっていたのでそこは修正しました。
そして、0xで再度プロファイリングをした結果が次のようになります。
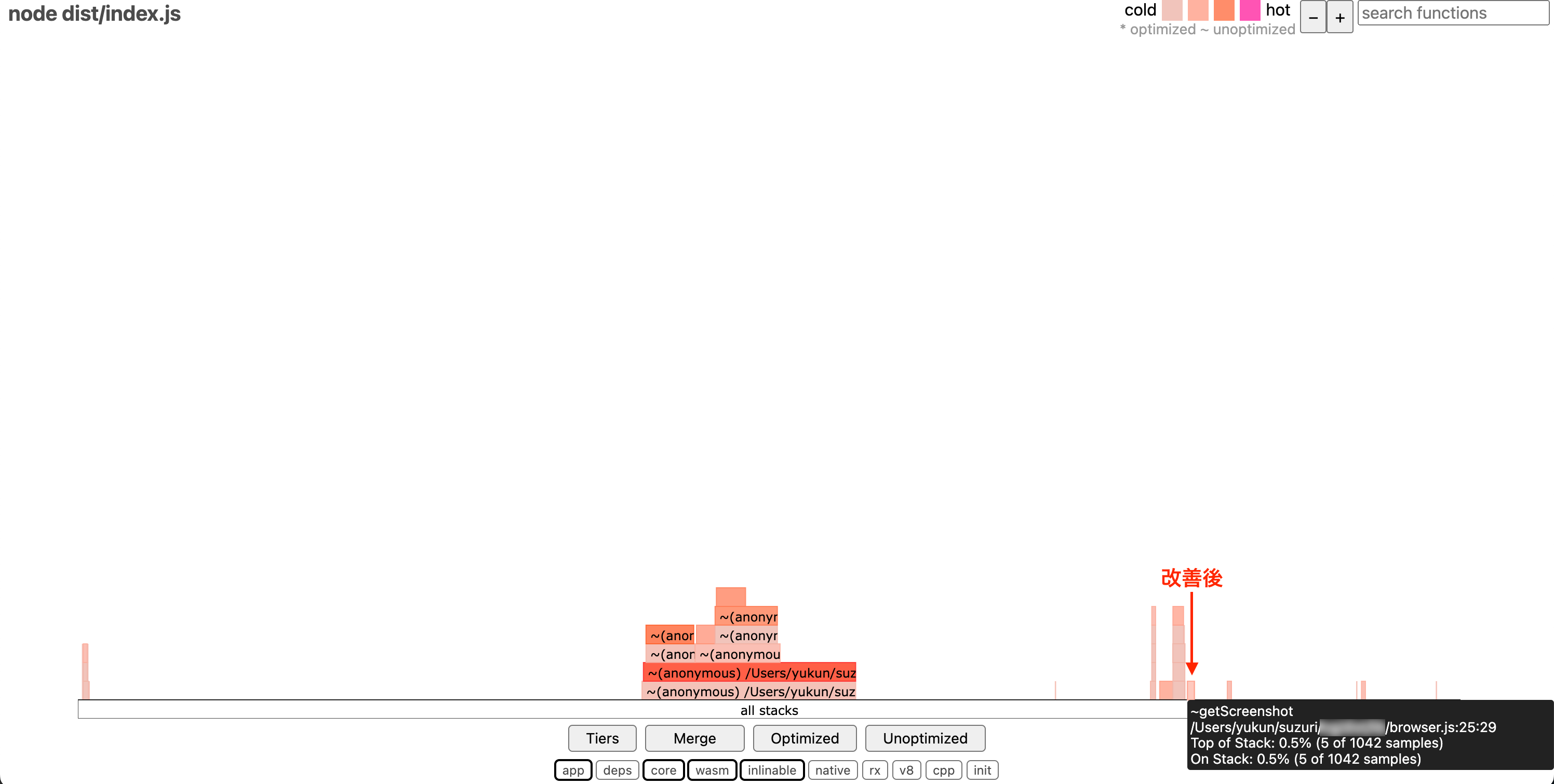
改善前に比べて getScreenshot の処理時間が短くなり、hotとして表示されなくなりました。ChatGPTの提案通りにブラウザインスタンスを使い回すようにしたことが大きく改善につながったようです。単純な改善ではありますが、あまり慣れていない技術やコードベースで、一から自分でコードリーディングをして特定するよりも圧倒的に速くこの改善策に辿り着くことができました。
ベンチマーク
改善前と改善後のコードにheyでベンチマークをかけて、実際にレスポンスがどのくらい改善されたかを検証します。 同じURLに100リクエストを50並列で実行しています。
改善前のベンチーマークは以下の通りで、トータルで15.2秒、平均で5.9秒かかっています。
$ hey -n 100 -c 50 http://localhost:4000/image.png?id=123456
Summary:
Total: 15.2360 secs
Slowest: 8.3189 secs
Fastest: 1.1257 secs
Average: 5.9729 secs
Requests/sec: 6.5634
Total data: 11760900 bytes
Size/request: 117609 bytes
Response time histogram:
1.126 [1] |■
1.845 [7] |■■■■■■
2.564 [4] |■■■■
3.284 [5] |■■■■
4.003 [4] |■■■■
4.722 [4] |■■■■
5.442 [6] |■■■■■
6.161 [6] |■■■■■
6.880 [4] |■■■■
7.600 [45] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
8.319 [14] |■■■■■■■■■■■■
Latency distribution:
10% in 2.4469 secs
25% in 4.9068 secs
50% in 7.1909 secs
75% in 7.3942 secs
90% in 7.6566 secs
95% in 7.8064 secs
99% in 8.3189 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0125 secs, 1.1257 secs, 8.3189 secs
DNS-lookup: 0.0112 secs, 0.0000 secs, 0.0228 secs
req write: 0.0000 secs, 0.0000 secs, 0.0001 secs
resp wait: 5.9602 secs, 1.1018 secs, 8.2921 secs
resp read: 0.0001 secs, 0.0000 secs, 0.0001 secs
Status code distribution:
[200] 100 responses
そして、改善後のベンチーマークが以下の通りで、トータルで7.9秒、平均で3.1秒かかっています。
$ hey -n 100 -c 50 http://localhost:4000/image.png?id=123456
Summary:
Total: 7.9396 secs
Slowest: 4.3049 secs
Fastest: 0.7439 secs
Average: 3.1067 secs
Requests/sec: 12.5951
Total data: 11760900 bytes
Size/request: 117609 bytes
Response time histogram:
0.744 [1] |■
1.100 [4] |■■■
1.456 [5] |■■■■
1.812 [5] |■■■■
2.168 [5] |■■■■
2.524 [5] |■■■■
2.881 [5] |■■■■
3.237 [5] |■■■■
3.593 [7] |■■■■■
3.949 [53] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
4.305 [5] |■■■■
Latency distribution:
10% in 1.4903 secs
25% in 2.5670 secs
50% in 3.6467 secs
75% in 3.6946 secs
90% in 3.8101 secs
95% in 4.0181 secs
99% in 4.3049 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0128 secs, 0.7439 secs, 4.3049 secs
DNS-lookup: 0.0114 secs, 0.0000 secs, 0.0236 secs
req write: 0.0000 secs, 0.0000 secs, 0.0002 secs
resp wait: 3.0938 secs, 0.7194 secs, 4.2789 secs
resp read: 0.0001 secs, 0.0000 secs, 0.0002 secs
Status code distribution:
[200] 100 responses
平均値で比較すると、レスポンスタイムが約2倍高速化されたという結果になりました🔥
そしてレスポンスタイムが速くなると、スループットも上昇し、サーバーを水平スケーリングしなくても、エラーやタイムアウトが起こるという問題が解消されました。
さらに、サーバーに余裕ができて今まで水平スケールしていたサーバー(コンテナ)の台数を2割ほど減らしてもリクエストを捌けることが分かりコスト削減をすることもできました。
終わりに
プロファイリングでアプリケーションの重い処理を特定し、ChatGPTに最適化してもらうというフローは、パフォーマンス改善において非常に有効な手段になるという気づきを得ました。
もはや重い処理を特定するという作業もコードとプロファイリングをGPTなどのLLMにそのまま入力して、改善結果を出力するツールとかも実現できそうですね。
ChatGPTはうまく使うとエンジニアにとって強い武器になるので、これからも活用方法を模索していきます。


