
ホスティング事業部 SREチームの @takumakume です。
11/21に「技術的負債に向き合う Online Conference」 が開催されました。 ペパボからは、技術責任者の @kenchan と @takumakume が登壇しました。
この記事では、@takumakume が登壇した「ソフトウェアの継続的アップデートをコンテナ化によって加速させる」というタイトルのLTについて紹介します。LTでは駆け足の説明でしたので、補足的な位置づけとなります。
簡単に説明すると
変更しにくいシステムは放置されるので、コンテナ化して変更しやすくした!
という話です。
以降で詳しく説明していきます。
ソフトウェアアップデートの必要性について


ソフトウェアを継続的にアップデートしなければシステムは徐々に壊れていきます。予想外のタイミングと規模でアップデートを強制されることに繋がり、ビジネスに悪影響を及ぼします。
例えば「Ruby on rails のバージョンを上げたいが、 MySQL のバージョンも上げる必要がある。」「OpenSSLのバージョンを上げたいがパッケージが提供されていないため、OSを上げるか自前でビルドするか選択する」といったケースです。
事業部のアプリケーションを取り巻く状況と課題

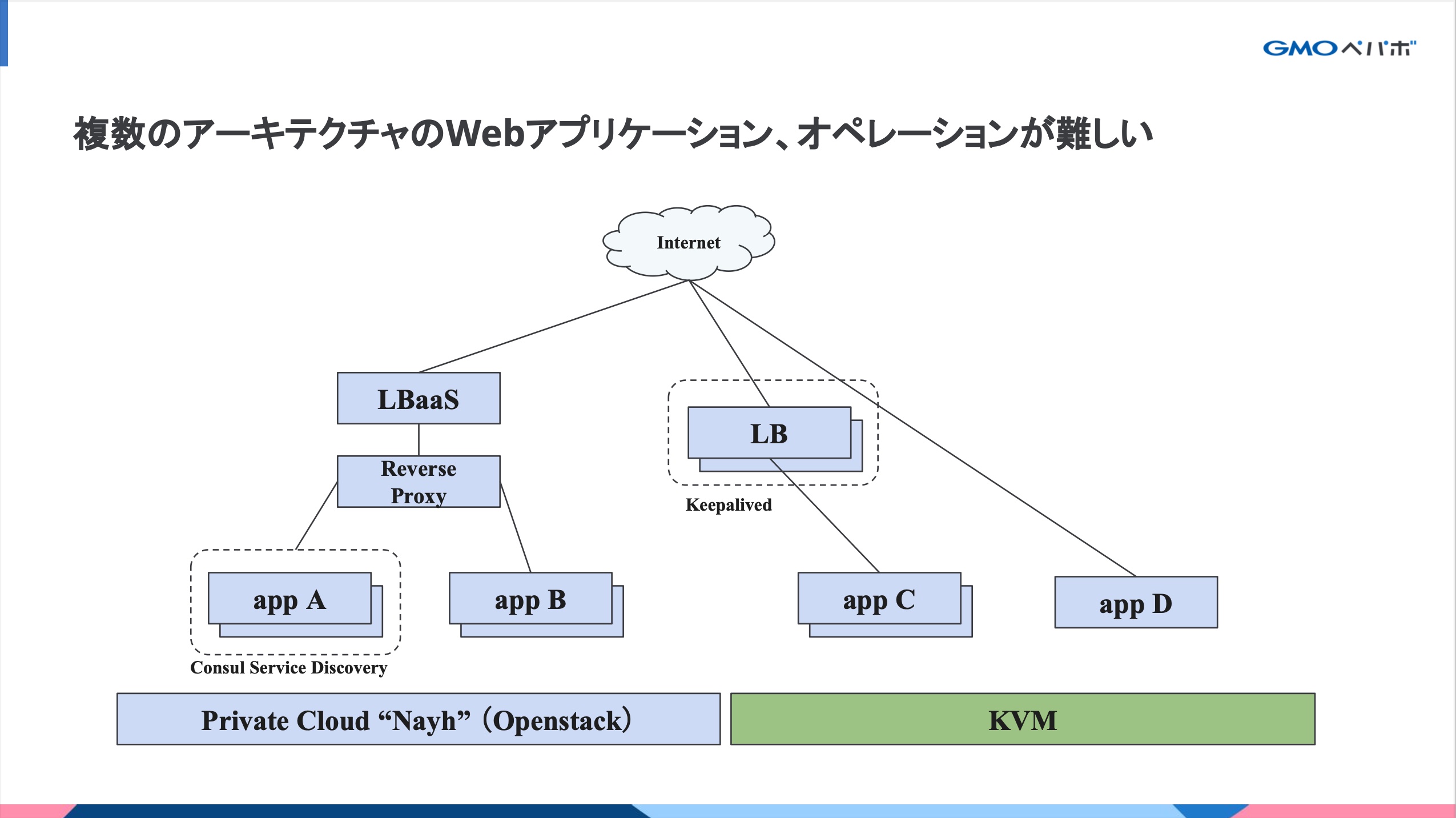

さまざまな歴史を持つ40種類のWebアプリケーションがVMかつ複数のアーキテクチャで稼働しており、技術的な課題がありました。
例えば、サーバーをメンテナンスするときに稼働中のサーバーをサービスアウトするオペレーションだけでも複数種類のオペレーションが必要でした。
- Keepalived(IPVS)の操作
- Nginxの操作
- Consul のサービスディスカバリの操作
- プライベートクラウドの LBaaSの操作
他にはOSや言語のバージョンを上げる時に、ChefやPuppetといった構成管理ツールの大きめの開発をしたり、VMを作って移行したりと作業量が多く専門スキルが必要でした。
1度作ったVMを構成管理ツールを用いて手動で数年に渡って継ぎ足し運用をしており、構成ドリフト(構成管理ツールと実サーバの設定が異なっている)が発生してしまってオートメーション恐怖症になってしまうこともありました。
ソフトウェアアップデートの初手「コンテナ化」
アプリケーションエンジニアに親しみがある Dockerfile を書くことができれば特別なオペレーションをせずにアプリケーションの変更ができるようにしました。
初手でコンテナ化をすることで、ソフトウェアアップデートの作業ができるエンジニアの幅を広げつつ、デリバリー速度を上げることが狙いです。
ソフトウェアアップデートを支える技術
“変更しやすいシステム” を実現するための工夫について紹介しています。
徹底したGitOps
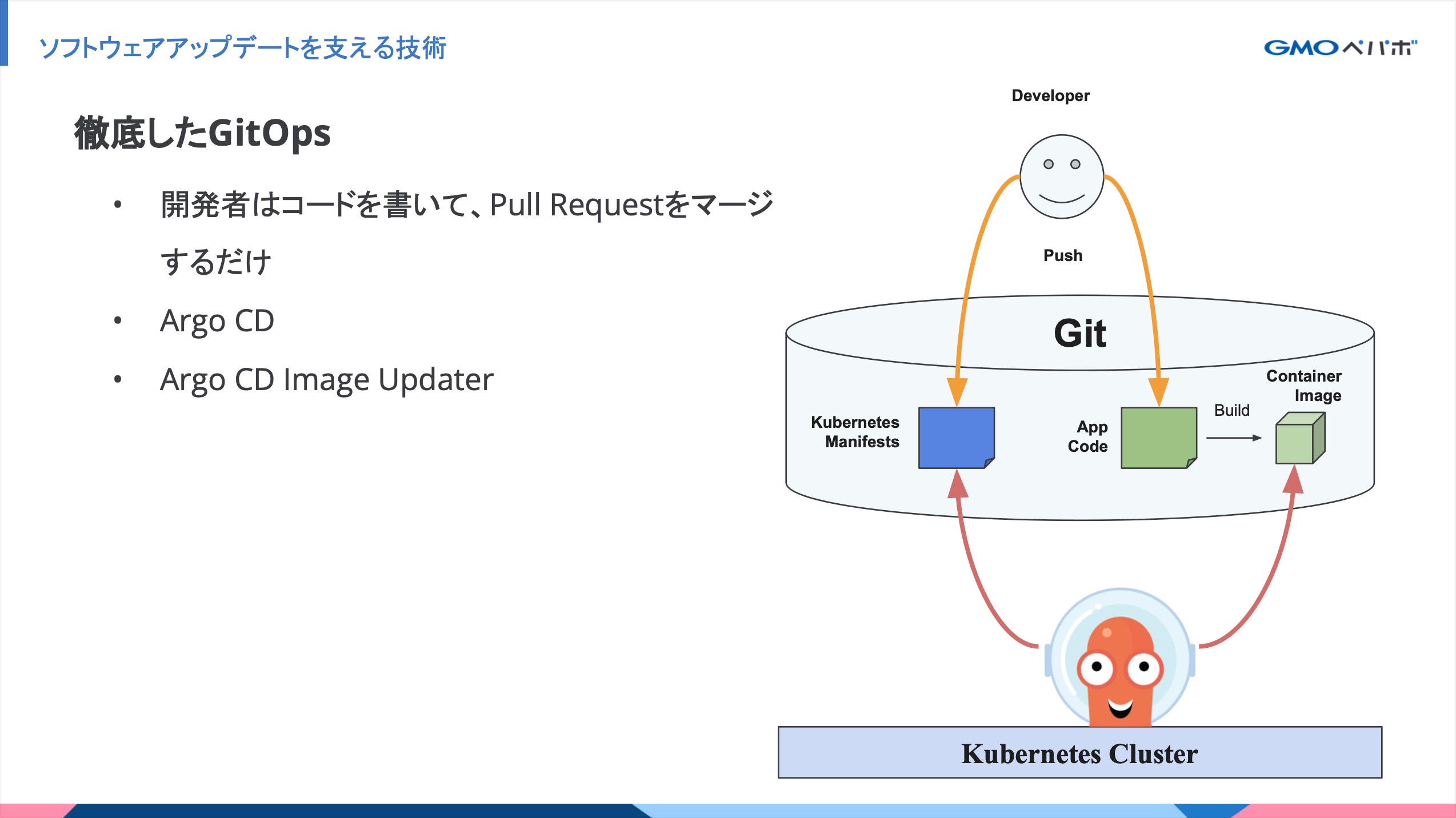
これまでは、構成管理ツールによるサーバーのプロビジョニングと、Capistranoによるアプリケーションのデプロイを行っていました。
これからは、各アプリケーションの Kubernetes manifests と Dockerfile、アプリケーションコードを同一リポジトリ内で管理してアプリケーションエンジニアやSREがコミットします。
リリースには特にオペレーションは必要なく、Pull Requestのマージのみです。
Staging環境をPull Request毎に自動生成
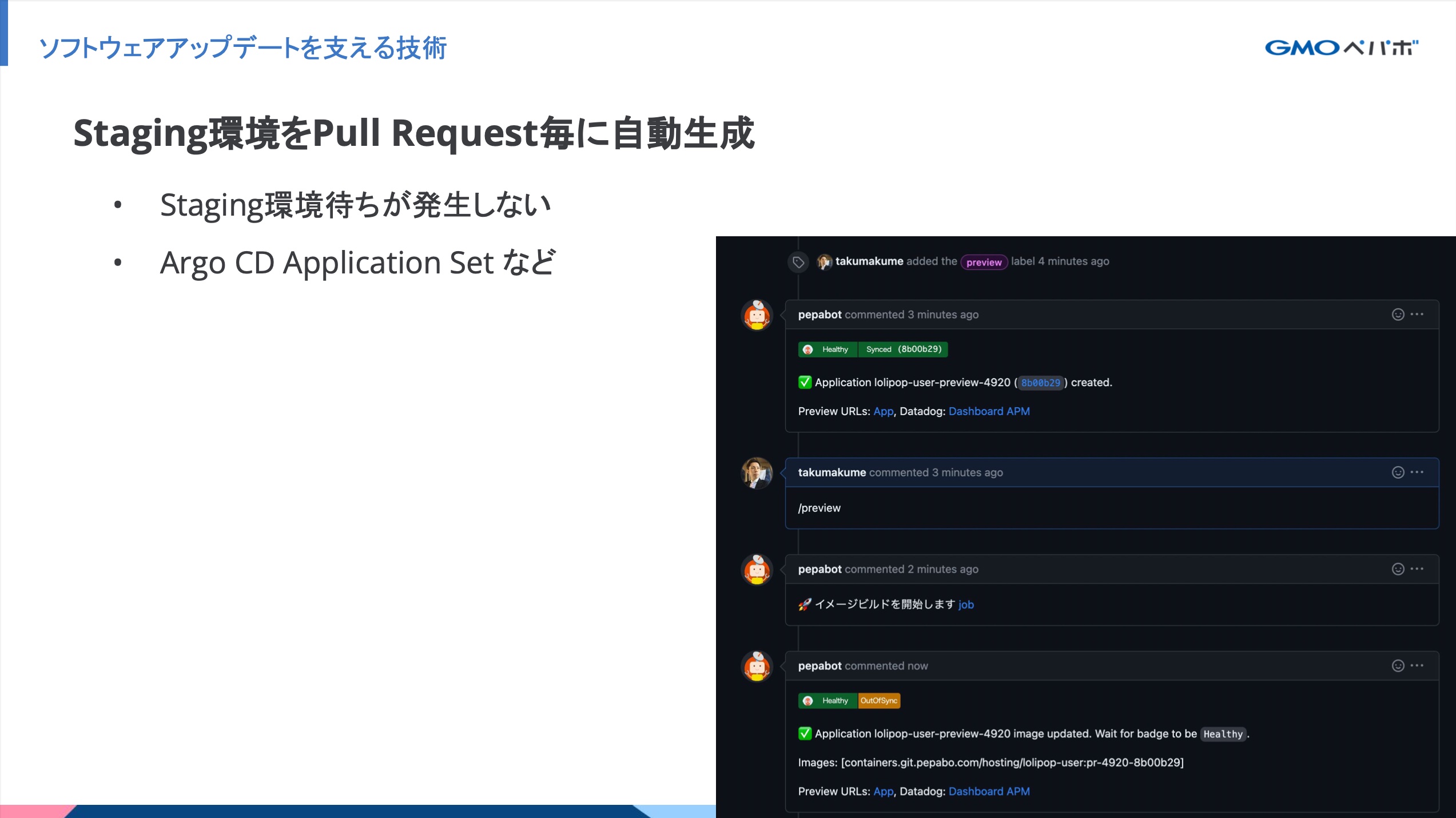
システムやコードに変更を加える前に、 Production 相当の Staging を用いて動作確認をしています。ホスティング事業部のアプリケーション開発では、Pull Request毎に Staging 環境を自動生成できます。以下のメリットがあります。
- Staging 環境を共有しないため、他の開発者の作業が影響しない
- レビュイーとレビュアーが同じ環境で動作確認ができる
Pull Requestごとの環境生成はさまざまな方法があると思いますが、私が採用している方式はProductionとほぼ同じKubernetes manifestsでありインフラ構成であるため、Productionに限りなく近い環境であることが売りの1つです。さらにアプリケーションコードのみならず、Kubernetes manifestsの動作確認もPull Request毎に行うことができます。
動作確認をしやすいシステムはソフトウェアの継続的なアップデートに一役買っています。
当日は紹介する時間がなかったのですが、以下のような仕組みで実現しています。
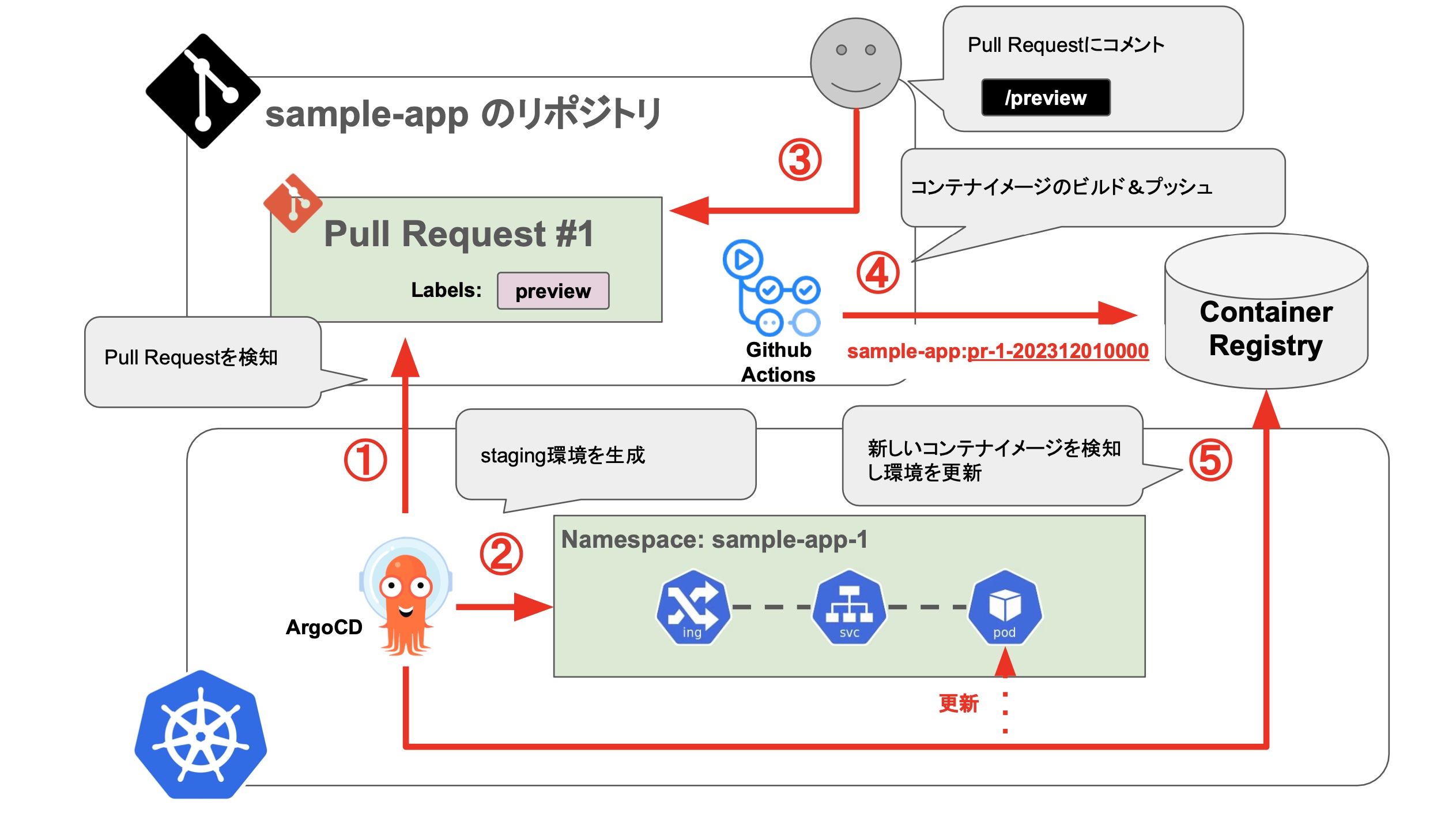
- Argo CD の ApplicationSet Controller の Pull Request Generator が特定のラベルが付与された Pull Request を検知する
- Pull Request の Branch の Kubernetes manifests を元に、Staging 環境を生成する
- Pull Request 内の
/previewコメントをトリガーに Github Actionsを実行する - Github Actionsでアプリケーションのコンテナイメージをビルド&プッシュする
- Argo CD Image Updater が
pr-${Pull Request Number}-YYYYMMDDHHMMSSタグのイメージを検知して環境を更新する
また、環境を更新したときの Pull Request への通知コメントは Argo CD Notifications を利用しています。
Ingressリソースのように、Pull Requestごとにドメインを設定したい場合は Kustomize を用いて埋め込んでいます。
具体的には2つのステップで実現しています。
ApplicationSet のテンプレート内でのkustomizeの設定でPull Requestの環境であるホスト名をAnnotationとして設定する。(例えば sample-app-1.example.com )
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: sample-app
spec:
template:
spec:
source:
kustomize:
commonAnnotations:
# 各リソースに対して、Pull Requestの環境であるホスト名をAnnotationとして設定する
preview-host: sample-app-{{number}}.example.com
:
Staging環境のKustomizeで、Pull Requestの環境であるホスト名をAnnotationから取得して、Ingressリソースに埋め込む。
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
replacements:
- source:
group: networking.k8s.io
version: v1
kind: Ingress
name: sample-app
fieldPath: metadata.annotations.[preview-host]
targets:
- select:
group: networking.k8s.io
version: v1
kind: Ingress
name: sample-app
fieldPaths:
# IngressのhostにAnnotationの値をを埋め込む
- spec.rules.0.host
- spec.tls.0.hosts.0
:
これによって、Pull Requestごとにホスト名が変わるIngressリソースを生成することができます。
プログレッシブデリバリーの導入
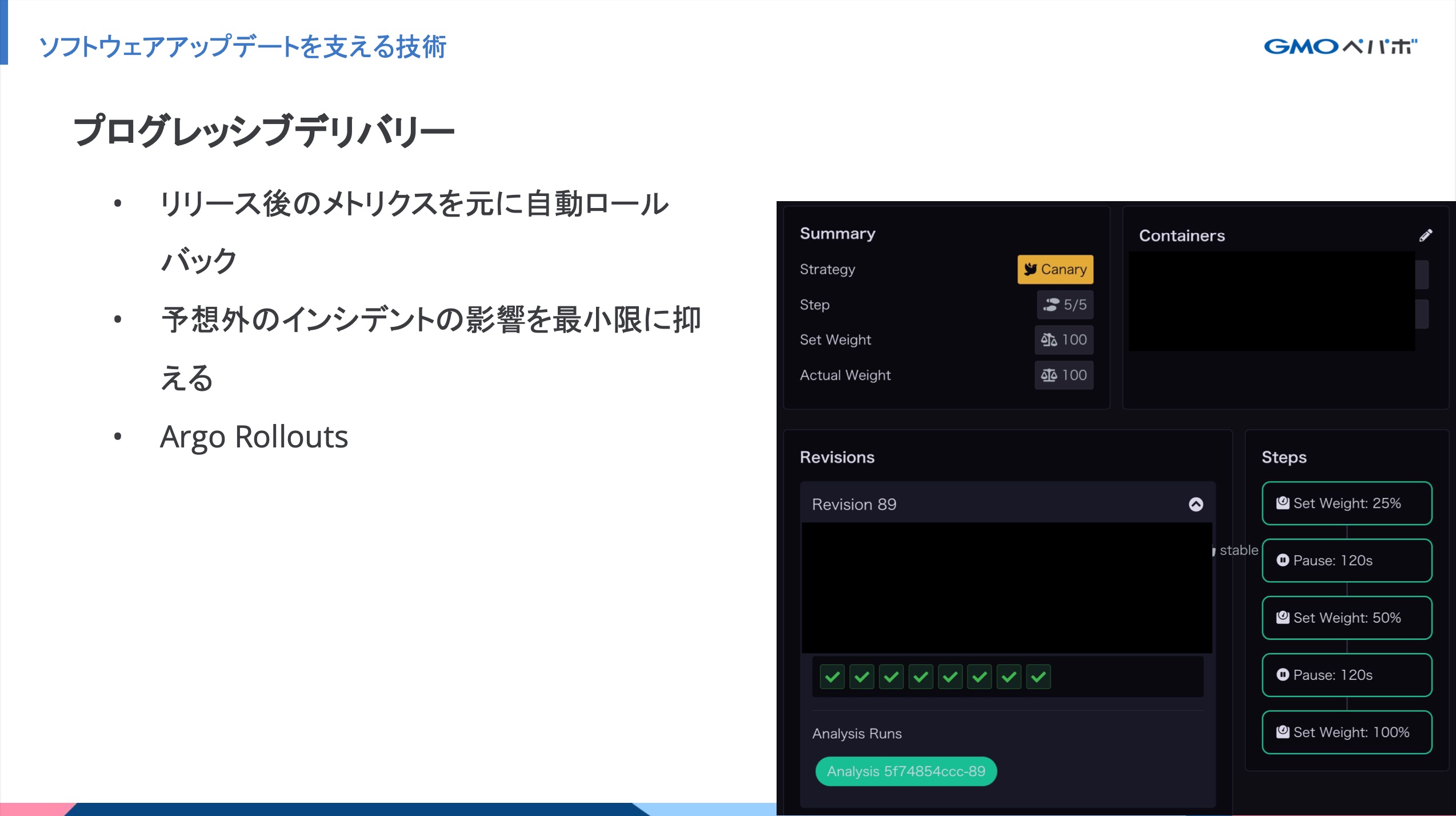
アプリケーションコードの変更を段階的にリリースをして特定の条件を満たすと自動ロールバックをする仕組みを入れています。システムに変更を加えると、想定外の障害が発生することがあります。その際のリスクを軽減する目的です。 プログレッシブデリバリーを実現するためにArgo Rollouts を利用しました。弊社のKubernentes ClusterのモニタリングツールとしてDatadogを採用しており、アプリケーションのエラーレートを元に一定の割合になるとリリースを中断してロールバックするようになっています。
脆弱性の対応
ホスティング事業部のWebアプリケーションだけで40個ほどあります。それらのアプリケーションの脆弱性をすべて対応するとなると大量の作業が必要になります。理想的にはすべて対応することですが、リソースが有限である以上は優先順位をつけざるを得ません。
そこで、コンテナ環境に関しては Kubernetes Cluster上で aquasecurity/trivy-operator を実行し、コンテナイメージのSBOM(Software Bill of Materials)を収集しています。SBOMとはソフトウェアのコンポーネントや依存関係をリスト化したものです。
収集したSBOMを Dependency Track に集約して脆弱性を管理しています。
脆弱性の中でも KEV(Known Exploited Vulnerabilities) に該当するものに絞って通知することで最優先で対応する運用をしています。KEVとは実際に悪用が確認された脆弱性のリストです。
この取り組みによって、無数の脆弱性の中から最優先で対応すべきものを見逃さないようにしています。
詳しくは、以下のスライドをご覧ください。
さいごに
アプリケーションのコンテナ化を進めることで「変更しやすいシステム」を構築し「開発者体験」を良くしていきました。その結果、メンテナンスが活発になりソフトウェアアップデートが加速するという内容でした。
技術的負債に向き合う Online Conference では、技術責任者の @kenchan が「負債と言わないことが負債と向き合うこと」というタイトルで登壇しています。ペパボにおける技術的負債の向き合い方について紹介していますので、ぜひご覧ください。


