6 畳 1K にセミダブルベッドと Yogibo、どうも todacchi です。
最近の悩みはセラミックファンヒーターが電気代を Plus Ultra することです。
先日、SUZURI のデジタルコンテンツ販売の事前登録機能の事前登録機能を無事にリリースしました。
SUZURI のデジタルコンテンツ販売とは、簡単に言うとデジタルデータを SUZURI 上で販売・購入できる機能です。
詳しくは LP ページをご覧ください。
基本的に実際に手を動かす開発は僕を含めたエンジニア 2 人とデザイナー 1 人で行っており、ウイルスチェック周りはサービス横断のプラットフォームグループ(PFG)に所属するエンジニアの 2 人に進めていただきました。
設計や実装をしていく中でいろいろと知見もたまってきたので、今回はその中でもファイルアップロードについて説明しようと思います。
この記事でわかること
- ActiveStorage などを使用しない S3 へのダイレクトアップロード(ダイレクトアップロードすることで Rails サーバーをファイルが経由しないのでさまざまなメリットがあります)
- MinIO を用いたテスト手法
- アップロードしたファイルを kt-paperclip(paperclip の fork)で管理する方法(やらなくても良い)
前提
SUZURI ではもともと、一部の画像の管理に paperclip を使用しており、現在ではメンテナンスが継続されている kt-paperclip を使用しています。
ファイルアップロードを作るにあたり ActiveStorage への移行も検討しましたが、早くリリースしたいという要望もあり、現時点で移行する工数を取るべきでないと判断し AWS SDK を基本的に使いつつ、kt-paperclip と連携することもできる方針にしました(kt-paperclip の機能はファイルの削除などにしか使わない予定なので、最終的には使用しないかもしれません)。
ファイルアップロード機能を作るにあたってパフォーマンスやセキュリティの観点から、S3 へダイレクトアップロードすることにしました。以下、細かい理由です。
- アップロードできるファイルは拡張子や Content-Type などで制限しないとします。アップロードされるファイルはウイルスなどが含まれる可能性があるので、そういったファイルを個人情報のある Rails サーバーに一時的にも置くことはリスクがあります。
- アップロードできるファイルサイズは 1GB 程度を想定していて、ファイルサイズが大きい場合に Rails サーバーのリソースを圧迫させたくありません。
- SUZURI の Rails アプリは Heroku で動作しています。Rails サーバーを経由してしまうとアップロードに時間がかかったとき Heroku がタイムアウトしてアップロードに失敗してしまいます。
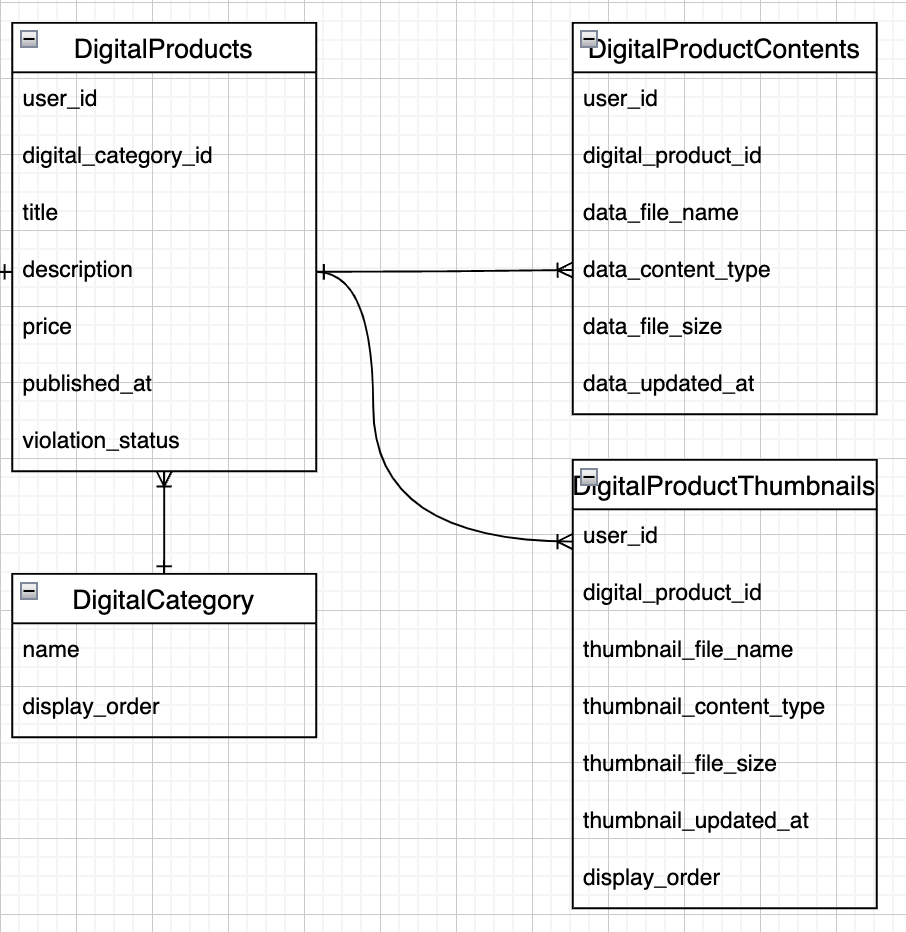
テーブル設計としては 1 つの DigitalProduct テーブルは複数の DigitalProductContent を持っています。
DigitalProductContent はアップロードされた販売用ファイル情報を保持するテーブルです(1 レコードにつき 1 ファイルに対応しています)。
AWS SDK を使ったコードをテストするために MinIO の導入
開発を始めた時点で AWS SDK を使用したコードをテストを書く仕組みがありませんでした。
作ろうとしているのは販売用ファイルをアップロードして管理するという重要度の高い機能なので、コードの品質を担保するためにローカル環境と CI(継続的インテグレーション)環境に MinIO を導入してテストをかけるようにしました。
導入によって、大きく生産性や安全性を高めることができたと思います。
開発環境に MinIO を導入する手順
MinIO は S3 互換で Docker image が配布されています。
導入にあたりこちらの記事を参考にさせていただきました。深く感謝します。
以下のようにサービスコンテナを追加し、docker-compose up するだけでローカル環境では起動します。
SUZURI では DB(データベース) や Redis はサービスコンテナで立ち上げ、Rails サーバーはコンテナで起動するかローカルで起動するか選択できるようになってます。
追加したホスト名は S3_HOST という環境変数に入っている前提で説明していきます(Rails サーバーをローカルで動かしている時は S3_HOST は localhost であり、Rails サーバーから MinIO へアクセスする時はhttp://localhost:9000になります。Rails サーバーをコンテナで動かしている時は S3_HOST は s3 であり、Rails サーバーから MinIO へアクセスする時はhttp://s3:9000になります)。
バケットの追加は AWS SDK を使ってもいいですし、9001 ポートにアクセスすると GUI が用意されてます。
# docker-compose.yml
version: "2"
services:
# 省略
s3:
image: minio/minio:latest
ports:
- "9000:9000"
- "9001:9001"
volumes:
- s3:/data
command: "server /data --console-address :9001"
environment:
MINIO_ROOT_USER: user
MINIO_ROOT_PASSWORD: password
volumes:
# 省略
s3:
テスト実行前にテスト用のバケットを作ったり、バケット内のデータを削除したりできるようにします。
今回は以下の様な helper を作りました。
# spec/support/s3_test_helper.rb
class S3TestHelper
def resource
@resource ||= Aws::S3::Resource.new(
region: "ap-northeast-1",
access_key_id: "user",
secret_access_key: "password",
endpoint: "http://#{ENV['S3_HOST']}:9000",
force_path_style: true,
)
end
def bucket_name
"dummy-bucket-#{Rails.env}"
end
def bucket
@bucket ||= resource.bucket(bucket_name)
end
def create_bucket
begin
resource.create_bucket(acl: 'private', bucket: bucket_name)
rescue Aws::S3::Errors::BucketAlreadyOwnedByYou
puts "#{bucket_name} already exists."
end
end
def clear_bucket!
bucket.clear!
end
def object_exist?(object_key)
object = bucket.object(object_key)
object.exists?
end
end
RSpec.configure do |config|
s3_test_helper = S3TestHelper.new
s3_test_helper.create_bucket
s3_test_helper.clear_bucket!
end
実際に S3 ファイルを操作する各テストの前に、clear_bucket!を使用してバケット内のファイルを消す運用にしています(Redis のキャッシュをクリアするRails.cache.clearと同じように使えます)。
仮想ホスト形式がうまく設定できなかったので、force_path_styleをtrueにしてパス形式で使用しています。
パス形式はドメインの後にスラッシュでバケット名を繋ぐ形、仮想ホスト形式はサブドメインにバケット名を置く形です。
http://s3-ap-northeast-1.amazonaws.com/<bucket-name> # パス形式
http://<bucket-name>.s3-ap-northeast-1.amazonaws.com # 仮想ホスト形式
パス形式は 2020 年にサポート終了してますが、以前作られたバケットのサポートは続く様で機能自体も当分存続しそうなので、テストとローカルで使用するだけなら問題ないと判断しました。
RSpec.configureのブロックはテスト実行時の最初に、バケットを作成する処理をしています。
GitHub Actions 環境に MinIO を導入
GitHub Actions(以下 Actions) を使った CI(継続的インテグレーション)への導入も、開発環境とほぼ同じようにできます。
唯一の問題は MinIO の配布されてるイメージはサービスコンテナとして追加しただけでは起動しません。
先述した docker-compose.yml の command のように起動コマンドを実行しなければならないのですが、Actions にはそれをできる機能がありません。
そこで、イメージを追加するだけで起動する Dockerfile を作成し、その Dockerfile から作成した Docker Image を Actions で使用するようにします。
これで Actions でもテストができるようになりました。
# Dockerfile
FROM minio/minio:latest
RUN microdnf upgrade -y && microdnf clean all
CMD ["minio", "server", "/data"]
# .github/workflows/ci.yml
# 省略
jobs:
rails_test:
# 省略
services:
# 省略
s3:
# imageには上記のDockerfileから作ったimageを指定する
image: containers.git.pepabo.com/suzuri/images/minio:latest
ports:
- "9000:9000"
env:
MINIO_ROOT_USER: user
MINIO_ROOT_PASSWORD: password
container:
env:
S3_HOST: s3
S3_CDN_HOST: s3
# 省略
ファイルのダイレクトアップロード
実は最初、ファイルアップロードは「ファイルをアップロードした後、DB に対応するレコードを追加する手法」で実装をしていました。
しかし、途中でウイルススキャンした方がいいよねという話になり、スキャンとの相性を考慮し「DB に対応するレコードを追加した後、ファイルをアップロードする手法」に変更しました。
どちらにするかはプロダクトの性質によると思うので両方解説をしていきます。
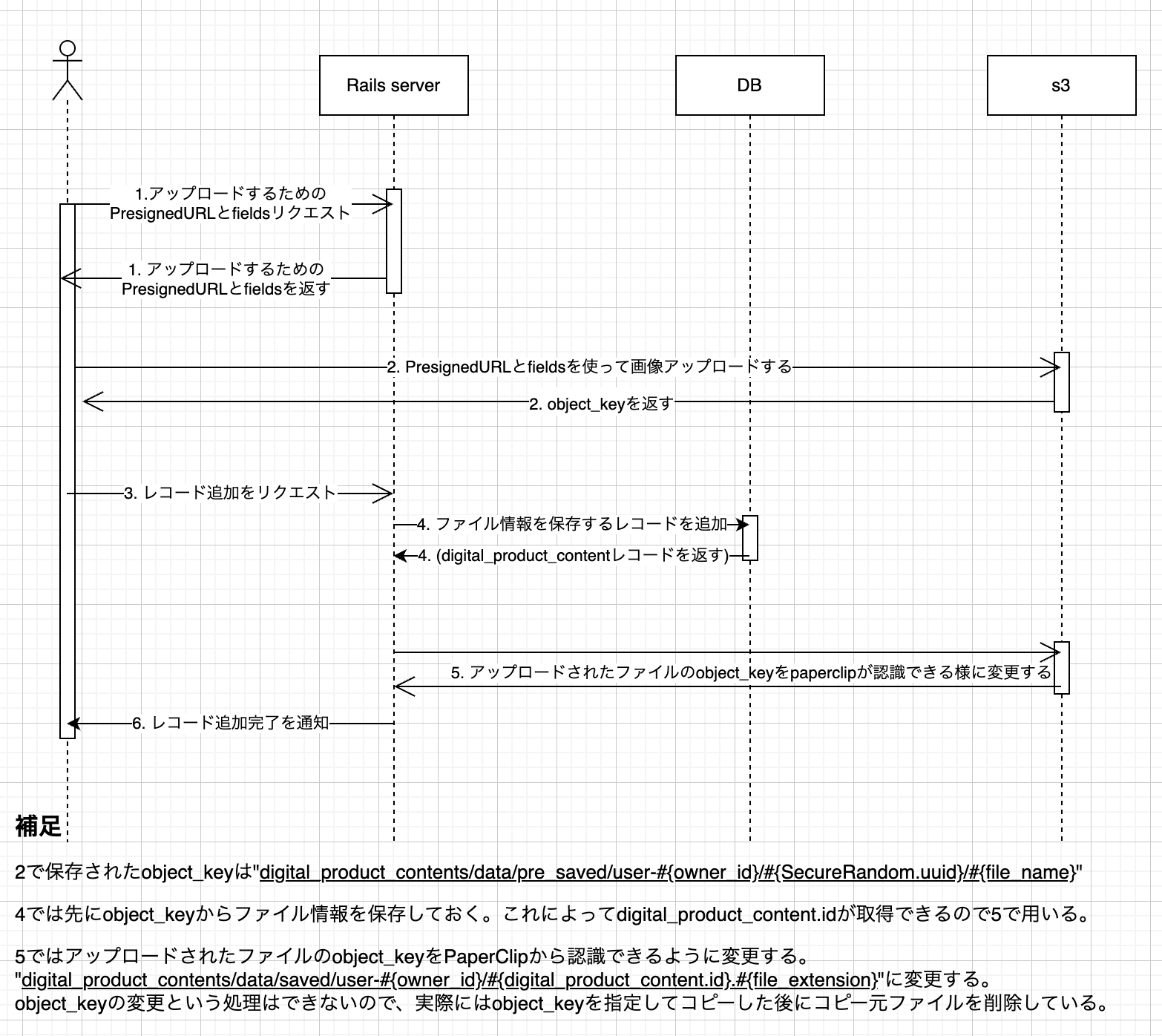
仕様 1(ファイルをアップロードした後、DB に対応するレコードを追加する手法)
こちらの手法のメリットは、アップロード未完了ファイル用のレコードが作られないことです。
デメリットは object_key の変更が必要など処理が相対的に複雑になること。また、後述するウイルススキャンのように S3 ファイルの変更を察知して走る処理があると object_key が変更されるタイミングでも実行されるので、無駄な処理となってしまうことです。アップロードできるファイル数を制限しようと思った時などに、ファイルアップロードする段階でレコードが存在しないためロジックが複雑になる可能性もあります。
全体の流れを示すシーケンス図です。
最終的に使用することはありませんでしたが、この手法を実装する上でこちらの記事が参考になりました。深く感謝します。
1. ファイルをアップロードするための presigned_url と fields を発行します。
presigned_url と fields を用いることで S3 に直接ファイルをアップロードすることができます。
AWS SDK にある presigned_post メソッドを使うことで発行できます。
コードは以下のようになります。
class DigitalProductS3Client
def resource
@resource ||= Aws::S3::Resource.new(
region: ENV['AWS_REGION'] || 'ap-northeast-1',
access_key_id: ENV['AWS_ACCESS_KEY_ID'] || 'user',
secret_access_key: ENV['AWS_SECRET_ACCESS_KEY'] || 'password',
endpoint: ENV['AWS_ACCESS_KEY_ID'] ? "https://#{ENV['S3_HOST']}" : "http://#{ENV['S3_HOST']}:9000", # AWS_ACCESS_KEY_IDがあるときはS3に繋ぐ
force_path_style: Rails.env.development? || Rails.env.test?,
)
end
def bucket
@bucket ||= resource.bucket(
ENV['S3_BUCKET'] || "dummy-bucket-#{Rails.env}"
)
end
# AWS SDKのpresigned_postと混同しないようにmy_presigned_postとしました
def my_presigned_post(content_type, file_name, owner_id)
res = bucket.presigned_post(
key: "digital_product_contents/data/pre_saved/user-#{owner_id}/#{SecureRandom.uuid}/#{file_name}",
success_action_status: '201',
acl: 'private',
content_type: content_type,
metadata: {
'original-filename' => file_name
}
)
{
# Railsをdocker上で動かしている場合、Railsからs3(minio)へアクセスする時のホスト名はs3になる
# しかし、フロントエンドからアクセスする時のホスト名はlocalhostを使わなければならない
url: Rails.env.development? ? res.url.gsub('http://s3', 'http://localhost') : res.url,
fields: res.fields
}
end
end
ポイントは
- レコードの一意な id がないので uuid を Object_key に含めています。これによって object_key が重複することは基本ありません。
- presigned_url は S3(MinIO)の URL ですので、開発環境で Rails サーバーがコンテナで動いている時、Rails から MinIO にアクセスする時のホスト名は s3 になります。しかし、ブラウザからアクセスする時のホスト名は localhost なので置換しています。Rails サーバーがローカルで動いているのであれば置換は必要ないです。
- ファイルアップロードに成功したら 201 を返すようにします。
- object_key にファイル名を入れてますが、別に入れる必要はないです(むしろ入れない方がいいかも)。ただ、拡張子はあった方が便利なのでファイル名から拡張子だけ取り出すと良さそうです。
あとはコントローラーなどで my_presigned_post で発行した presigned_url と fields をクライアントに返します。
digital_product_s3_client = DigitalProductS3Client.new
presigned_post = digital_product_s3_client.my_presigned_post(content_type, file_name, current_user.id)
# 以下をクライアントに返す
{ presigned_url: presigned_post[:url], fields: presigned_post[:fields] }
さて、せっかく MinIO を導入してるので RSpec で実際にテストしてみましょう。
発行した presigned_url と fields を用いてファイルをアップロードする helper メソッドをテストに追加します。
# spec/support/s3_test_helper.rb
class S3TestHelper
# 省略
def post_file(image_file_name, presignedUrl, fields)
image_file = File.open(image_file_name)
begin
data = fields
data['file'] = image_file
uri = URI.parse(presignedUrl)
http = Net::HTTP.new(uri.host, uri.port)
req = Net::HTTP::Post.new(uri.request_uri)
req.set_form(data, "multipart/form-data")
response = http.request(req)
ensure
image_file.close
response
end
end
end
このメソッドを使って、一例として以下の様なテストが書けます。
fields の内部をチェックしてますが、ここまでやる必要は特にないと思います。 テストが書けることが嬉しくて書いちゃいました。
require 'spec_helper'
describe DigitalProductS3Client do
let!(:digital_product_s3_client) { DigitalProductS3Client.new }
let(:s3_test_helper) { S3TestHelper.new }
let!(:clear_bucket) { s3_test_helper.clear_bucket! }
describe '#presigned_post' do
let(:user) { create(:user) }
let!(:presigned_post) do
digital_product_s3_client.my_presigned_post('image/jpeg', 'sample.jpg', user.id)
end
let!(:url) { presigned_post[:url] }
let!(:fields) { presigned_post[:fields] }
it 'presigned_urlとがfieldsが返る' do
expect(url).to be_truthy
expect(fields['key']).to match(/digital_product_contents\/data\/pre_saved\/user-[0-9]*\/[0-9a-z-]*\/sample\.jpg/)
expect(fields['success_action_status']).to eq('201')
expect(fields['acl']).to eq('private')
expect(fields['Content-Type']).to eq('image/jpeg')
expect(fields['x-amz-meta-original-filename']).to eq('sample.jpg')
expect(fields['policy']).to be_truthy
expect(fields['x-amz-credential']).to be_truthy
expect(fields['x-amz-algorithm']).to eq('AWS4-HMAC-SHA256')
expect(fields['x-amz-date']).to be_truthy
expect(fields['x-amz-signature']).to be_truthy
end
it 'presigned_urlとfieldsを使ってs3にファイルがアップロードでき、201が返る' do
response = s3_test_helper.post_file('spec/fixtures/sample.jpg', url, fields)
expect(
s3_test_helper.object_exist?(fields['key'])
).to eq(true)
expect(response.code).to eq('201')
end
end
end
2. ファイルを Direct アップロードする
JS でサーバサイドから presignedUrl と fields を受け取った後、fields から formData を作ってそれを body に入れて送るだけです。
これで S3 にファイルがアップロードされます。
<input type="file" id="file-selector" />
// サーバサイドからpresignedUrlとfieldsを受け取ってるものとします
const element = document.getElementById(
'file-selector'
) as HTMLInputElement
const file = element.files?.[0]
const formData = new FormData()
for (const key in fields) {
formData.append(key, fields[key])
}
formData.append('file', file)
const res = await axios.post(
presignedUrl,
formData
)
if (res.status === 201) {
// 成功した時の処理
}
3~4. ファイル情報を DB に追加して、アップロードしたファイルの object_key を変更します
以下の様なメソッドを作って S3 からファイルの情報を取得します。
その情報をもとに DigitalProductContent レコードを追加しましょう。
クライアントからファイルサイズなどを受け取ると、改竄されている可能性があるので S3 から直接取得しています。
class DigitalProductS3Client
# 省略
def object_headers(object_key)
object = bucket.object(object_key)
{
content_length: object.content_length,
content_type: object.content_type,
file_name: object.metadata['original-filename'],
}
end
end
レコードを追加した時点で一意な id が手に入るので S3 にあるファイルの object_key を変更します。
object_key を変更するメソッドは AWS SDK にないので別ファイルとしてコピーした後に、コピー元を削除します。
class DigitalProductS3Client
# 省略
def copy_object(from_key, to_key)
from_object = bucket.object(from_key)
from_object.copy_to(bucket: bucket.name, key: to_key)
end
def delete_object(object_key)
bucket.object(object_key).delete
end
end
5~6. アップロードされたファイルが kt-paperclip から認識できるようにします
やらなくてもいいです。
今回は DigitalProductContent クラスにhas_attached_file :dataとしています。
そこに設定を追記します。
これは yml にまとめている前提で書いていますが、Model に直接書く場合は修正してください。
:storage: :s3
:url: ':s3_alias_url'
:s3_credentials:
<<: *s3_credentials
:path: ':class/:attachment/saved/user-:user_id/:id:dotextension'
:s3_protocol: <%= (Rails.env.development? || Rails.env.test?) ? "http" : 'https' %>
:s3_host_alias: <%= (Rails.env.development? || Rails.env.test?) ? "#{ENV['S3_CDN_HOST']}:9000/dummy-bucket-#{Rails.env}" : "#{ENV['S3_CDN_HOST']}" %>
:s3_region: <%= ENV['AWS_REGION'] || 'ap-northeast-1' %>
:s3_options:
:endpoint: <%= (Rails.env.development? || Rails.env.test?) ? "http://#{ENV['S3_HOST']}:9000" : "https://#{ENV['S3_HOST']}" %>
:force_path_style: <%= Rails.env.development? || Rails.env.test? %>
:s3_permissions: :private
path にuser_idカラムの値を使ってますね。
kt-paperclip がデフォルトで対応してないカラムなので、config/initializers/paperclip.rbに設定を追記します。
# config/initializers/paperclip.rb
Paperclip.interpolates :user_id do |attachment, style|
attachment.instance.user_id
end
これで kt-paperclip の機能を使ってファイルの削除などができるようになります。
補足
レコードと紐づかなかった S3 のファイルは AWS SDK を使って Worker などで削除しましょう。
object_key がdigital_product_contents/data/pre_saved/**/*のファイルで一定時間より前にアップロードされたファイルを削除すればいいはずです。
仕様 2(DB に対応するレコードを追加した後、ファイルをアップロードする手法)
ウイルススキャンをアップロードの実装を進めながら検討し始めたのですが、先ほど説明したアップロードの仕様 1 ではウイルススキャンと相性が良くないことに気づきました。
ウイルススキャンについては詳細を省きますが、S3 でファイルの create 系の動作されたことをフックにして、自動でウイルススキャンが始まるという理解をしていただければ OK です。
object_key を変更する仕様の場合、アップロード時と object_key の変更時に 2 回スキャンされてしまうので、アップロードの仕様を変更することにしました(ウイルススキャンの方で回避策はあるかもしれないという話でしたが、全体のフローがややこしくなりそうと思ったので変更することにしました)。
DB にレコードを追加した後でファイルを S3 にアップロードするようにします。
こちらの手法のメリットは、アップロード前にレコードが作られているので、1 日にアップロードできる合計ファイル数の制限などを行おうとしたときに保存されてるレコードの情報を使用できること。また、object_key の変更が必要ないことです。全体のコードも仕様 1 と比較して簡潔に実装できます。
デメリットは アップロード未完了ファイルのレコードが追加されることですが、困ることは特にないと思います。アップロードが完了しているかをレコードをみたときに判定できるようにしたいので、アップロード完了後に data_file_size と data_updated_at に値を入れます。
全体の流れを示すシーケンス図です。
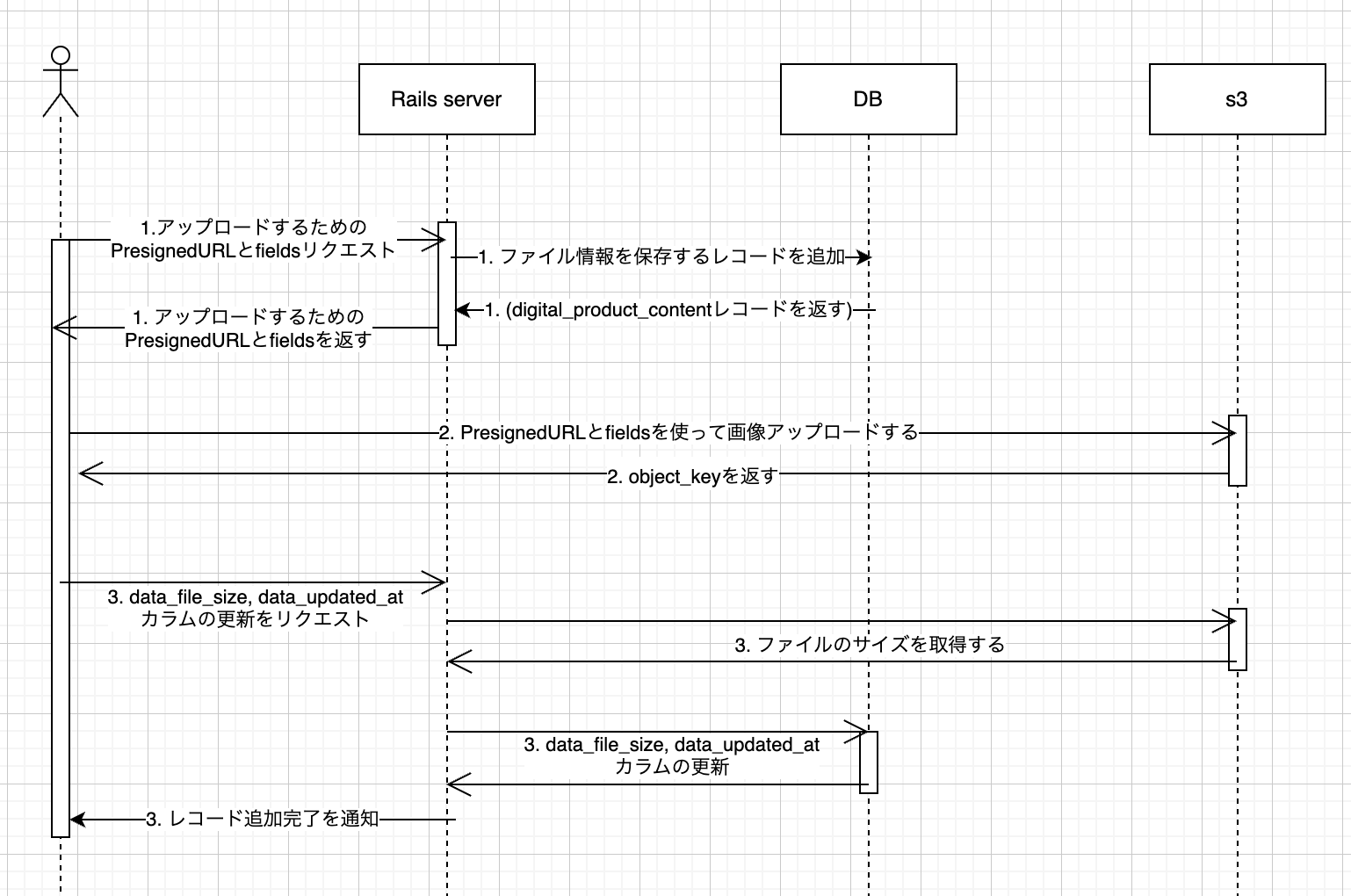
1. ファイルをアップロードするための presigned_url と fields を発行します。
ファイルのダイレクトアップロードの仕様 1 と同じように presigned_url と fields を発行していきます。
class DigitalProductS3Client
# 省略
# AWS SDKのpresigned_postと混同しないようにmy_presigned_postとしました
def my_presigned_post(key, content_type, file_name)
res = bucket.presigned_post(
key: key,
success_action_status: '201',
acl: 'private',
content_type: content_type,
metadata: {
'original-filename' => file_name
}
)
{
# Railsをdocker上で動かしている場合、Railsからs3(minio)へアクセスする時のホスト名はs3になる
# しかし、フロントエンドからアクセスする時のホスト名はlocalhostを使わなければならない
url: Rails.env.development? ? res.url.gsub('http://s3', 'http://localhost') : res.url,
fields: res.fields
}
end
end
変更点としては key を直接指定するようにしました。
コントローラーなどでレコードを追加したり、my_presigned_post を用いて presigned_url と fields を発行してクライアントに返します。
digital_product_content = DigitalProductContent.create!(
user_id: current_user.id,
data_file_name: file_name,
data_content_type: content_type,
)
digital_product_s3_client = DigitalProductS3Client.new
presigned_post = digital_product_s3_client.my_presigned_post(
digital_product_content.data_object_key,
digital_product_content.data_content_type,
digital_product_content.data_file_name,
)
# 以下をクライアントに返す
{
digital_product_content_id: digital_product_content.id,
presigned_url: presigned_post[:url],
fields: presigned_post[:fields]
}
指定する object_key はレコードの id を含めて重複しないようにします。
また、拡張子をつけるようにしています。下記の実装だと拡張子のないファイルやドットから始まるファイルは例外にしています。必要に応じて変更してください。
user_idはあってもなくてもいいです。
class DigitalProductContent < ApplicationRecord
class EmptyDataError < StandardError; end
class DotExtensionError < StandardError; end
# 省略
def data_object_key
if self.id.present? && self.data_file_name.present?
object_key = "digital_product_contents/data/user-#{self.user_id}/#{self.id}#{dot_extension}"
else
raise EmptyDataError
end
end
private
def dot_extension
extname = File.extname(self.data_file_name)
raise DotExtensionError if extname == '.' || extname == ''
extname
end
end
kt-paperclip と連携する場合は設定を修正しておきましょう。
:path: ':class/:attachment/user-:user_id/:id:dotextension'
2. ファイルを Direct アップロードする
ファイルのダイレクトアップロードの仕様 1 と同じです。
js 側で presigned_url と fields を用いてファイルのアップロードを行います。
3. ファイルサイズを S3 から取得してレコードを更新する
object_key からファイルサイズなどを取得するメソッドを DigitalProductS3Client に追加しておきましょう。
class DigitalProductS3Client
# 省略
def object_headers(object_key)
object = bucket.object(object_key)
{
content_length: object.content_length,
content_type: object.content_type,
file_name: object.metadata['original-filename'],
}
end
end
コントローラーなどでレコードを更新します。
digital_product_content = DigitalProductContent
.where(user_id: context[:current_user].id)
.find(digital_product_content_id)
digital_product_s3_client = DigitalProductS3Client.new
object_headers =
digital_product_s3_client.object_headers(digital_product_content.data_object_key)
digital_product_content.update!(
data_file_size: object_headers[:content_length],
data_updated_at: Time.zone.now
)
これで完了です。
補足
アップロード完了後に別リクエストでファイルサイズを取得しているのは処理がシンプルになること、正確なファイルサイズを取得できること、同時に S3 にアップロード完了していることをレコードに保存できること(今回は data_file_size もしくは data_updated_at が埋まっていたら S3 にファイルがあるとしています)が理由です。
presigned_url を発行する段階でサイズ制限をつければ、その時点で data_file_size カラムを埋めることも可能です。
また、この仕様 2 ではアップロードされなかったファイル情報を保持したカラムが存在するので Worker などで定期的に削除しておきましょう。
アップロードできるファイル数、ファイルサイズ制限
アップロードできるそれぞれのファイルサイズに制限をつけたいことがあります。
制限しなくても post リクエストの仕様上の制限で無限に大きなサイズのファイルをアップロードされることはないのですが、S3 の容量節約やセキュリティ対策としてつけておく方が良さそうです。
その場合はpresigned_postメソッドのcontent_length_rangeでバイトサイズを指定することで設定できます。
class DigitalProductS3Client
def my_presigned_post(key, content_type, file_name, content_length_range)
res = bucket.presigned_post(
key: key,
success_action_status: '201',
content_length_range: 0..1.gigabyte,
acl: 'private',
content_type: content_type,
metadata: {
'original-filename' => file_name
}
)
また、現状だといくつでもファイルをアップロードできてしまいます。
その対策として、1 日にアップロードできるファイル数を制限すると良さそうです。
例えばファイルのダイレクトアップロードの仕様 2(DB に対応するレコードを追加した後、ファイルをアップロードする手法)では、以下の様なコードで 1 日にアップロードされたファイル数を取得できます(厳密にはアップロード未完了でもカウントされますが問題はないでしょう)。
class DigitalProductContent < ApplicationRecord
def self.count_in_today(user_id)
DigitalProductContent
.where(
user_id: user_id,
created_at: Time.zone.today.all_day
)
.count
end
1 日のアップロードできるファイルサイズも制限したい場合は、presigned_url発行前にクライアントからファイルサイズを受け取り、それをcontent_length_rangeに使い、data_file_sizeに保存すると良さそうです。
こうすることでファイルアップロード前にファイルサイズを該当レコードに保存しておけます。
まとめ
個人的にはファイルのダイレクトアップロードの仕様 2(DB に対応するレコードを追加した後、ファイルをアップロードする手法)の方がメリットが大きかったと感じています。
SUZURI のデジコンのウイルススキャンのように S3 にファイルがアップロードされたことを条件に処理が走る場合は、処理が複数回実行されないのでコストを抑えられます。
コード量はファイルのダイレクトアップロードの仕様 1 より少なく、全体的にわかりやすいコードになったという印象です。
デメリットとしては繰り返しになりますが、S3 にファイルの存在しないレコードが存在するので常にそれを除外して使わないといけないことですね。
この記事が参考になれば幸いです。


