データ基盤チームの @udzura です。今回は、昨年の後半にかけてデータ基盤チームで取り組んできた、開発者の生産指標である Four Keys の可視化についてお話をします。
Four Keysとは何か
始めに、Four Keysについての説明をします。
Four Keysとは、GoogleのDevOps Research and Assessmentチームが6年間の研究の結果割り出した、ソフトウェア開発チームのパフォーマンスを示す4つの指標のことです。
詳細はGoogle Cloudのブログ記事「エリート DevOps チームであることを Four Keys プロジェクトで確認する」などをご確認いただければと思いますが、指標自体の定義について以下に引用します。
デプロイの頻度 - 組織による正常な本番環境へのリリースの頻度
変更のリードタイム - commit から本番環境稼働までの所要時間
変更障害率 - デプロイが原因で本番環境で障害が発生する割合(%)
サービス復元時間 - 組織が本番環境での障害から回復するのにかかる時間
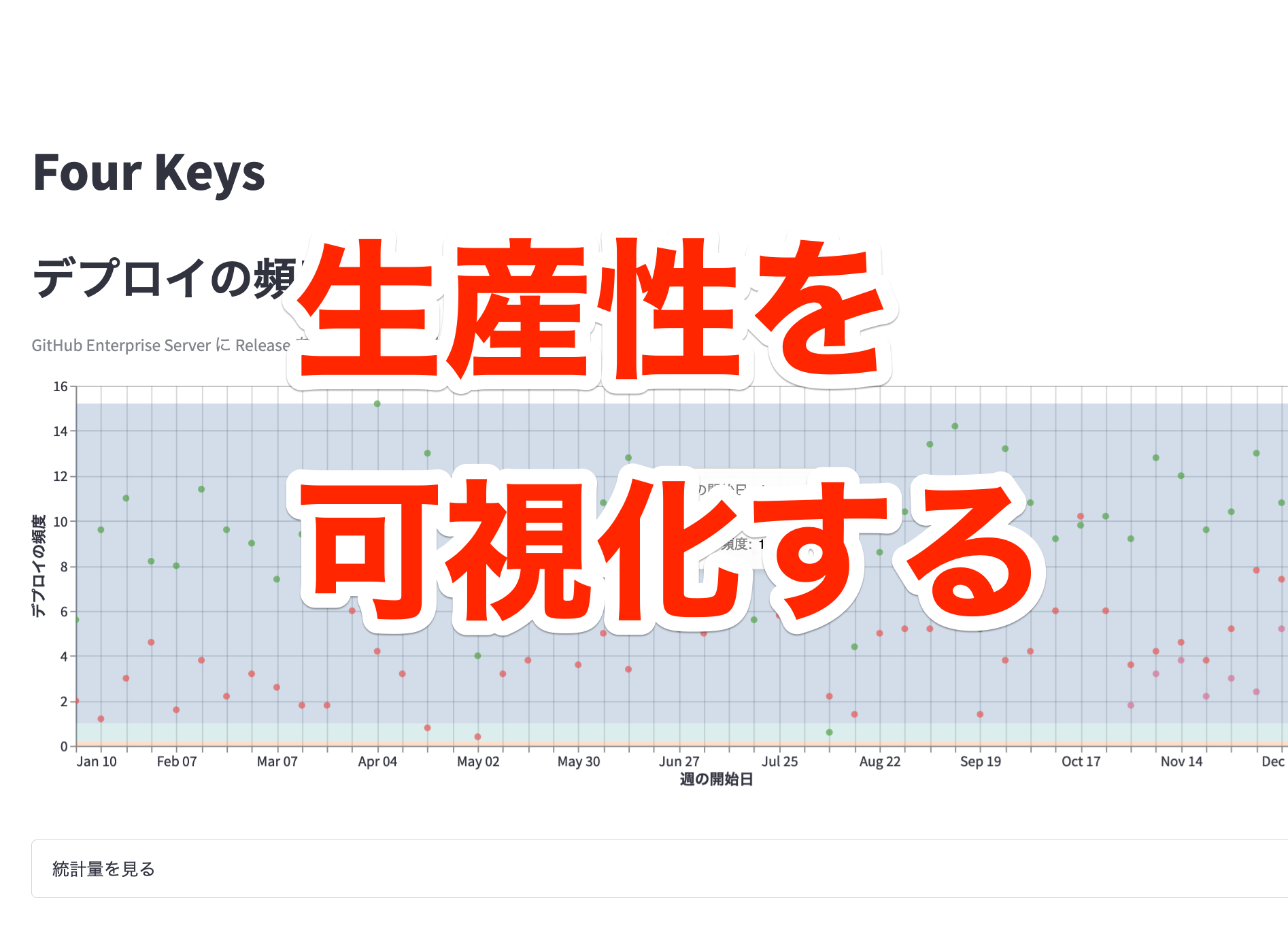
データ基盤チームでも、LeanとDevOpsの科学で説かれているような開発チームの生産性を計測、可視化することをミッションの一つとして取り組んできました。具体的には「生産性ダッシュボード」と社内で呼んでいる可視化基盤を作り、そこでFour Keysのトラッキングができるようにしました。
生産性ダッシュボードプロジェクトの全体図
まず、今回の生産性ダッシュボードプロジェクトのアーキテクチャの全体像を図に示します。
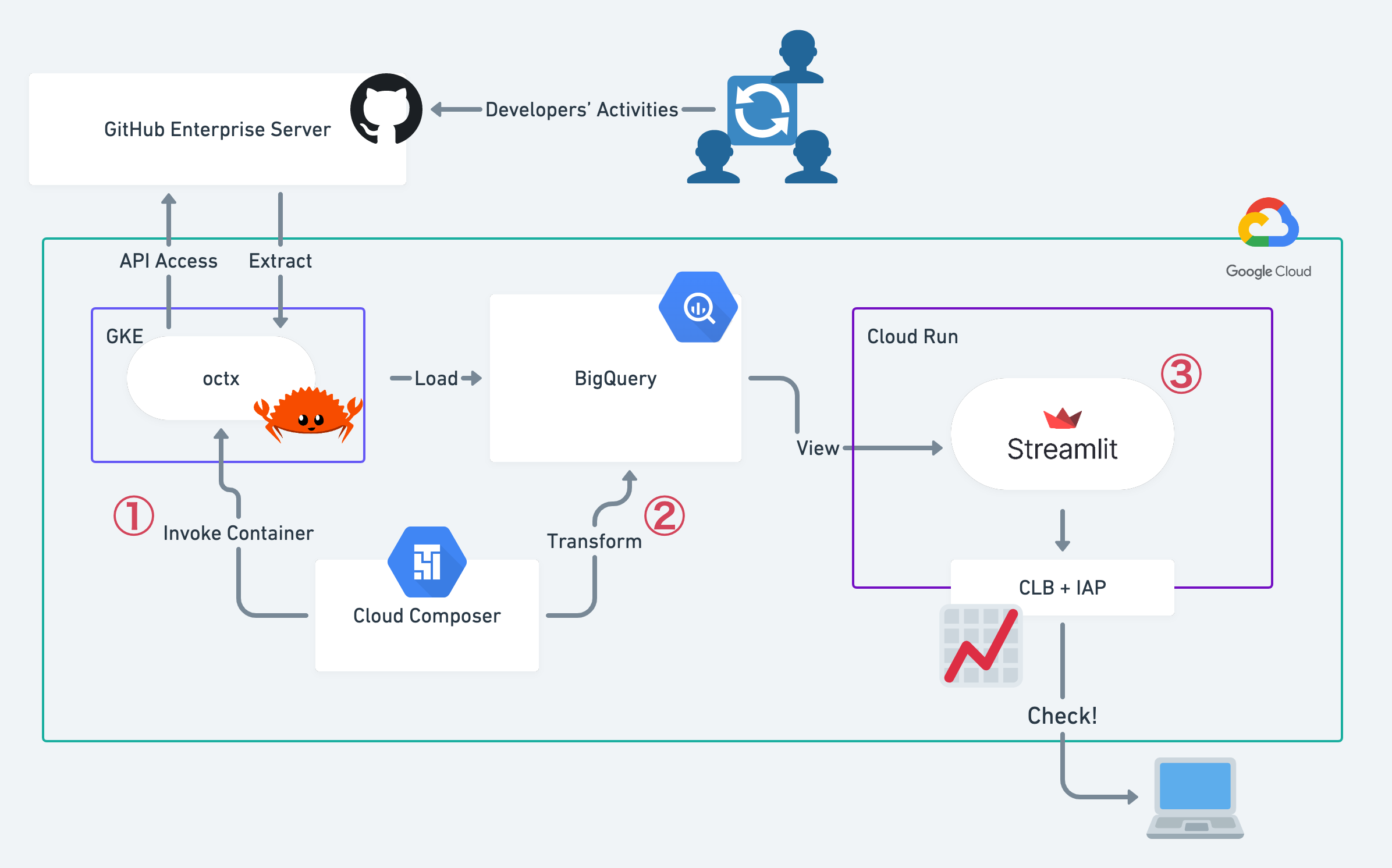
生産性ダッシュボードのアーキテクチャ
この節ではそれぞれのパートについて技術的内容を説明していきます。
開発活動のExtractとLoadパイプライン
最初に、Four Keysのための生データである開発活動の情報を取得する必要があります。いわゆるELT(Extract, Load, Transfer)の中の「E」と「L」の部分で、先ほどの図で言うと①の部分です。
今回は、データソースとして会社で利用しているGitHub Enterprise Server(GHES)での活動情報を利用することにしました。GHESはパブリック版のGitHubと同じくRESTfulなAPIが整理されており、例えばリポジトリに紐づくIssue、コメント、コミットやWorkflowの実行の記録などをまとめて取得することが可能です。
詳細は、GHESのAPIリファレンスを参照してください。
今回は、APIからのデータ抽出部分をRustのコマンドラインツールとして実装しました。その成果はoctxという名前のOSSにして公開しています。
octxは、「APIを経由して、データをCSVの形で出力する」ことのみを高速に行うコマンドとして、割り切って実装しています。CSVから先のLoadやTransformは、例えばbqコマンドであったり、後述するCloud Composerに任せる設計思想をとっています。
Extractジョブの具体的な実行は、そのoctxを含むDockerコンテナを作成し、Cloud Composer(Airflow)にあるKubernetesPodOperatorを利用して、毎日定刻にGKEの上で走らせています。そこで抽出したCSVについては同じくコンテナ内部でbqコマンドを発行しそのままロードしています。
また、octxコマンドは --days-ago オプションで「何日前までに更新されたデータを取得する」という指定が可能となっています。日次のジョブでは、差分のみを取得すればいいので、実行時間の微妙なズレを考慮して「2日前から現在まで」という指定をしています。
以下は擬似的なシェルスクリプトです。実際には、これらの処理を簡単なRubyスクリプトでラップして変更が容易なようにしています。
#!/bin/bash
if ! bq show pepabo.github_issues_tmp; then
bq mk --table pepabo.github_issues_tmp /path/to/schema_issues.json
fi
octx pepabo target_repo --issues --days-ago 2 > /tmp/github_issues.csv
bq load --skip_leading_rows=1 \
--replace \
--source_format=CSV \
--allow_quoted_newlines \
pepabo.github_issues_tmp \
/tmp/github_issues.csv
ちなみにoctx自体はオンプレミス版のGHESを想定したツールで、例えばAPIのレートリミットなどの処理を十分に考慮していません。利用の際はご留意いただきたく思います。また、必要な機能のPull Requestも歓迎します。
取得したデータのTransform
さて、生データとして「2日前から現在まで」の活動の情報が取得できました。このデータをクレンジングして、漏れ・被りがないデータに加工する必要があります。先ほどの図で言うと②の部分です。
今回はデータの格納先を、集計先のデータマート的なテーブルと、日次のジョブで更新する生データのテーブルに分けることで、生データと集計先データとの重複分をSQLで削除する、いわゆる差分同期を実現しています。
具体的に、生データの格納テーブルを pepabo.github_issues_tmp 、実際に集計に使う整ったテーブルを pepabo.github_issues としましょう。実は、GitHub APIで取り扱われる情報は、必ず node_id というレコードごとに同一であることが保証されるIDが付与されています。したがってそれを軸にして、以下のようなSQLで重複を排除し、 updated_at が最新のものだけ残すことができます。
SELECT
* EXCEPT(rn)
FROM (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY node_id ORDER BY updated_at DESC) AS rn
FROM (
SELECT * FROM pepabo.github_issues_tmp
UNION ALL
SELECT * FROM pepabo.github_issues
)
)
WHERE
rn = 1
このSQLをCloud Composerの BigQueryOperator で実行し、実行結果の挿入先を pepabo.github_issues として、かつ更新の方式を WRITE_TRUNCATE に指定することで、差分同期を実現しています。
ビュー部分
こうして作成した活動データを、最終的に社内のそれぞれのエンジニアが参照できるダッシュボードを作って可視化します。先ほどの図で言うと③の部分です。
今回、ダッシュボードを作成する技術として、PythonのStreamlitというフレームワークを軸に置くことにしました。
Streamlitは比較的シンプルなPythonのDSLを記述することで、柔軟なダッシュボードを定義、なおかつそれをWebアプリケーションとしてデプロイするすることができる一種のフレームワークです。
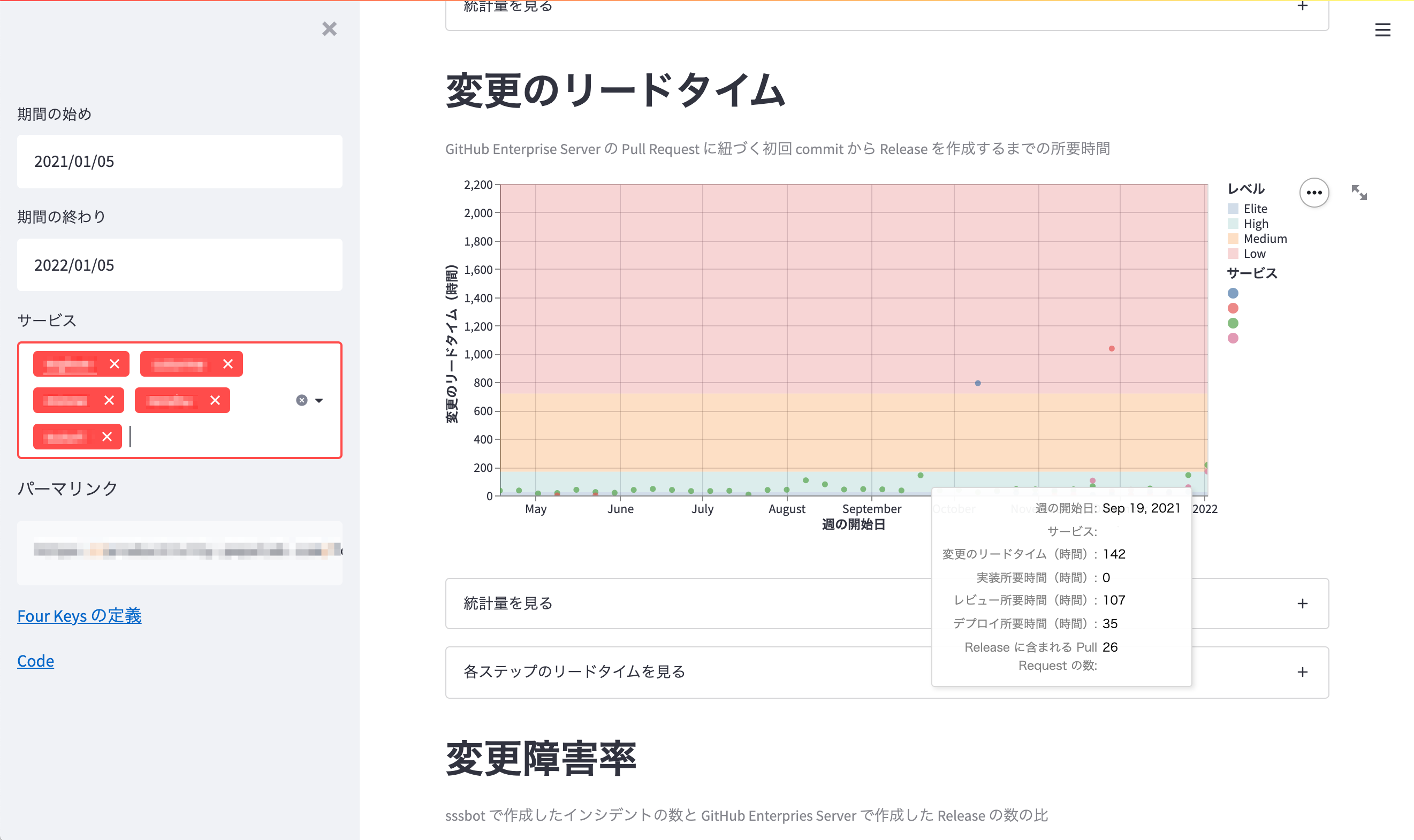
StreamlitによるFour Keysダッシュボードの一部
今回は、集計用のSQLとダッシュボードを表示するコード部分などをStreamlitのアプリケーションとしてまとめ、ひとつのDockerコンテナに固めてGCPのCloud Runにデプロイする方式を取りました。この形にした大きなメリットとして、ダッシュボードに利用するSQLと図表の定義のコードをGitHub上にホストして管理することができる点が挙げられます。このスタイルをデータチームではDashboard as Codeと呼んでいます。
多くのデータ分析の現場では、ダッシュボードの管理や再利用性について課題を感じているかと思いますが、Dashboard as Codeは一つの解ではないかと考えています。
ちなみに社内向けのダッシュボードということでアクセス制限をする必要がありますが、それについてもGCPのサービスの組み合わせで対応しました。具体的には、Google Cloud Load Balancing(GCLB)の配下にCloud Runをデプロイすることで、GCLBとIdentity-Aware Proxyを紐づけることができます。そうすることで会社内のメンバーに紐づいたGoogle Workspaceのアカウントで認証をさせることが可能になりました。
この構成の詳細はデータチームのメンバーである @tosh2230 がブログにまとめています。是非ご覧ください。
また、Four Keysの定義自体に関しても、Googleのものを参照しつつペパボ内部の運用上妥当な数値を設定することにしました。その定義は生産性ダッシュボードのDesign Docの一部に含め、こちらもGitHubで管理しています。以下に、2022年頭の段階での定義を掲示します。この定義は、基本的にペパボの4事業部でのGitHubの運用に即し、大きな違和感なく開発現場の生産性を表現できそうな指標を選びました。
| 指標名 | ペパボ | |
|---|---|---|
| デプロイの頻度 | 組織による正常な本番環境へのリリースの頻度 | GitHub Enterprise Server に Release を作成する 1 日あたりの平均頻度 |
| 変更のリードタイム | commit から本番環境稼働までの所要時間 | GitHub Enterprise Server の Pull Request に紐づく初回 commit から Release を作成するまでの所要時間 |
| 変更障害率 | デプロイが原因で本番環境で障害が発生する割合(%) | 本番環境 デプロイ合計回数に対する、インシデント発生のトリガーとなったデプロイ回数の割合 |
| サービス復元時間 | 組織が本番環境での障害から回復するのにかかる時間 | sssbot(社内のインシデントハンドリングを取り扱うSlack bot) でインシデントを作成してから復旧を宣言するまでに要した時間 |
実は、これらの定義に合わせてほんの少しだけ事業部のチームの皆さんに運用の変更をお願いしています。具体的には、アプリケーションのデプロイに合わせてGHES上にリリースを作成してもらうように依頼をして、全社で合わせてもらっています。元々社内では、たとえばCapistranoというツールを使ってデプロイしている場合、capistrano-github-releaseを用いてリリースも一緒に作成していたりしたため、無理がない範囲での変更だったと考えています。
まとめと今後
以上で、Four Keysを集計、可視化するために行った開発内容についてお話ししました。
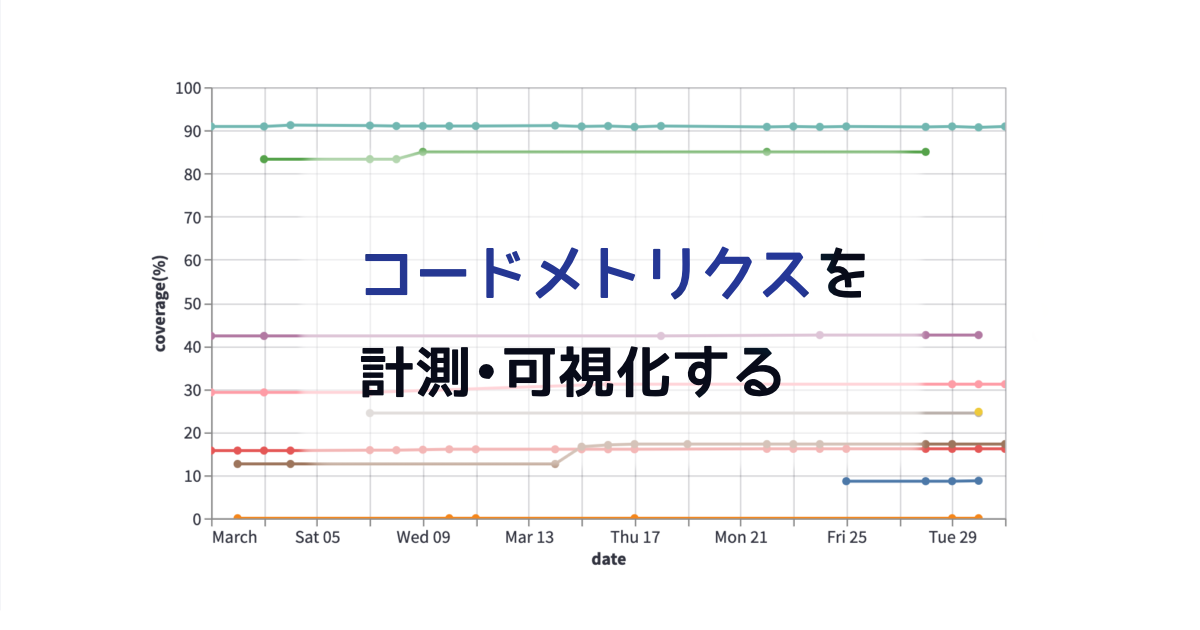
ところで今回のFour Keys集計の副産物として、GHES上での全体的な活動の状況も計測できるようになった点が挙げられます。取得したデータの中には、Four Keysでは未使用であっても有益な指標が存在します。例えばActions APIを経由して取得しているWorkflow runsのデータを用いると、CIのテスト実行時間の推移も可視化することができます。技術基盤チームの @k1LoW が開発しているoctocovで取得できるメトリックと合わせて、テストの効率や生産性を可視化できることが期待できます。
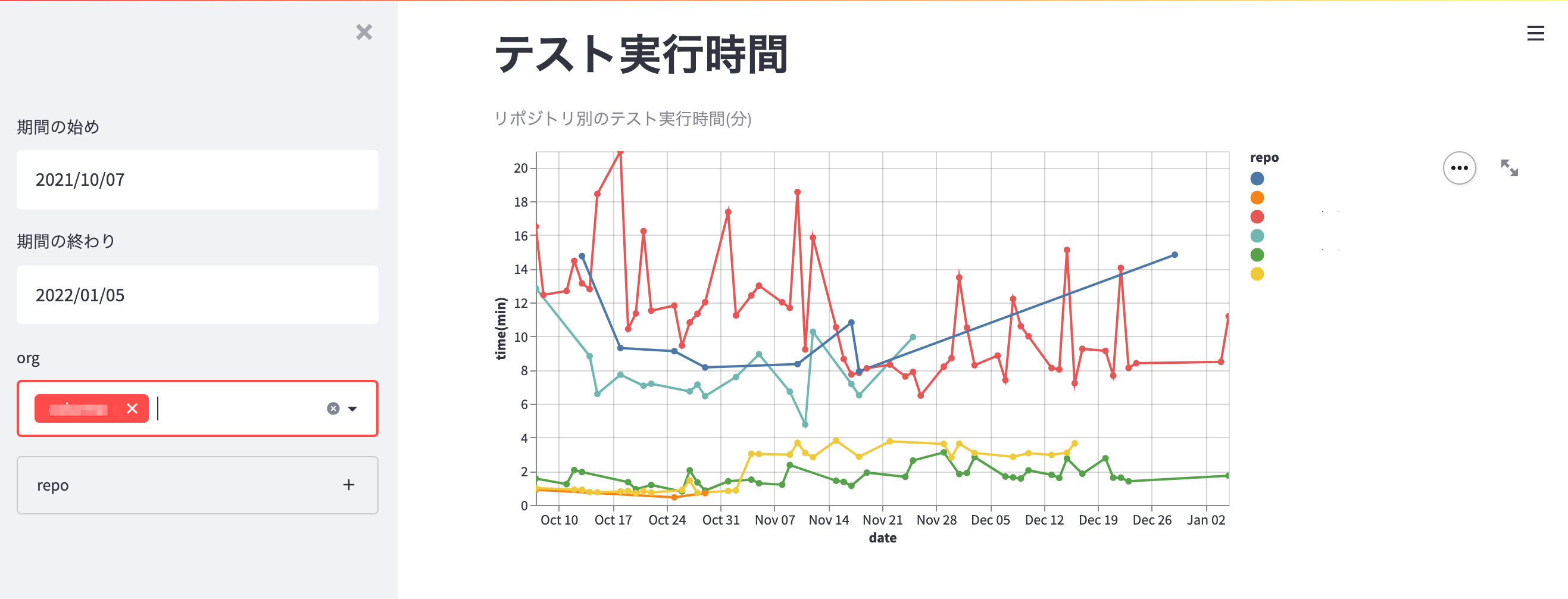
テストメトリックのダッシュボードの例
これらの数値を必要に応じ組み合わせ、引き続きペパボの組織の特性により合致した生産性の指標を探していこうと考えています。
ペパボはリモートワークを全面的に押し進めつつも、開発者を含む生産性の向上にも同時に取り組んでいます。GHESを含むSaaS上での活動情報はそういった取り組みにおいて重要なデータとなるでしょう。
画像について
今回掲示した図表に含まれるロゴ等は、それぞれのサービス、言語、ライブラリを指し示す目的で、規約の範囲で利用しています。また、図表の一部にtwemoji(CC BY 4.0)の画像を用いています。