はじめに
初めまして。技術部プラットフォームグループの馬崎と申します。
ペパボではOpenStackを利用したプライベートクラウドを運用しており、今回はそのサーバハードウェア選定についての記事です。
ペパボのプライベートクラウドのサーバ概要
採用しているサーバは一般的な1Uサーバです。データセンターに現在は46Uラックを7棟利用しており、2021年7月現在合計で80台のサーバを運用しています。
プライベートクラウドで採用しているサーバ遍歴
プライベートクラウドのサーバはまずレンタルのサーバで開始しました。便宜的にこちらを第一世代、以降採用ごとに第二、第三、第四世代と呼称します。
レンタルで開始したのは積極的に選択したものではなく、当時サーバを準備できる選択肢が他にないための消極的な採用でした。
レンタル可能な機種が数世代前の古いものだったこともあり、プライベートクラウドに採用しているOpenStackのバージョンをHavanaからMitakaにアップデートする際にハードウェアの更新や構成の自由さ、コストの都合で資産として扱いたいなどの理由から購入に切り替えました。
以降も主に採用CPUの世代切り替わりタイミング発生するモデルチェンジを契機に、比較検討検証を行い採用サーバの更新を行っており、現在は第四世代サーバを運用しています。
プライベートクラウド用のサーバ選定の難しいところ
プライベートクラウドサーバの選定の難しさは、特定の単一用途ではないために性能選定が難しい点があります。
例えばWebサーバやDBサーバであればそれぞれで動かすミドルウェアの処理性能が指標になります。WEBサーバであれば単位時間あたりの処理リクエスト数、データベースであれば社内で利用される規模のDBインスタンスでのクエリ処理数、応答性能などが該当します。このように異なる役割を持つVMインスタンスが複数稼働するプライベートクラウドでは、特定の性能指標や用途に限定したベンチマークテストだけでは計ることは難しく、用途を限定せずに安定してパフォーマンスを引き出せる必要があります。
そのため性能検証時のベンチマークもアプリケーションに特化したものよりも全体を俯瞰しやすいものをメインに利用しており、CPUはUnixBench、ディスクIO性能はfioを軸にその他にもGeekBenchやSysBench、STREAMなど複数のベンチマークソフトウェアを利用しています。
各世代の製品を選んだときの選定ポイント
共通しているポイントとしてはより安価に、より稼働インスタンス数を最大化することです。
それに加えて各モデル更新時の選定基準や採用理由については世代ごとに異なる要件がありました。
第一世代から第二世代への更新時の選定(2016年)
レンタルだった第一世代から購入へ切り替えた最初の選定です。
GMOペパボの他のサービスでの購入経験はありましたが、データセンターのロケーションの違いや用途の違いからほぼ白紙からの選定となりました。
第一世代のスペックでの稼働状況を確認して問題点を洗い出す
第一世代機はCPU 16スレッド(4コア8スレッドCPU 2基)、メモリ 64GB、ストレージ 1.44TB(480GB SAS HDD 6本 RAID1+0)のサーバを採用していました。この構成では1サーバ当たりの平均VMインスタンス数は4〜6程度の稼働状態でした。
社内でのプライベートクラウドの利用拡大もあり稼働インスタンス数は増加が予想され、この平均稼働インスタンスではサーバ筐体が多数必要になり、ラック利用増によるランニングコストの増加や、筐体数が増えることによる管理コストの増加などが懸念されました。
このため1サーバあたりの稼働インスタンス数を増加することを選定の目標としました。
第二世代のスペックの選定
稼働インスタンス数を増やすためにはCPUモデルをCPUコア数の多いものが向いていることから、当時の最新世代のXeon V4世代からコア数に優れたXeon E5 2650V4 (12コア/24スレッド)を2基搭載を選択しました。
当時のペパボのVMインスタンスで利用の多かったフレーバーサイズを元に、1インスタンスの基準値として 4vCPU 8GBメモリ と定め、CPUのオーバーコミット率(ハードウェアのスレッド数に対してVMインスタンスの仮想CPU数を何%まで搭載するかという指標)を200%まで許容する計算で 24(1CPUのスレッド数) * 2(CPU搭載数) * 2.00(オーバーコミット率) / 4(基準インスタンスvCPU数) = 24(搭載可能インスタンス) を計算しました。実際にはインスタンスの利用vCPU数は基準からブレるため20インスタンス程度での稼働を目安として設計しました。
24インスタンスの場合、メモリについては1インスタンス8GB計算で192GBで足りるため、当初256GBで検討していましたが、仮想CPUと異なりオーバーコミットが難しいことや、見積もりの結果512GBとの価格差が許容できる範囲であったため512GB構成の採用を決めました。
ストレージについては第一世代が2.5インチSAS HDDでしたが当時の社内でもSSDの利用が進んでおり、NANDの書き込み寿命に関してもメーカー発表の書き込み上限(TBW)に収まるIO量が想定されたため、第二世代では2.5インチSATA SSDドライブを6本でSoftwareRAID、RAID5を採用しました。
当時の採用のためのベンチマークテストの結果、SoftwareRAIDでの構成にて必要としていたIOPS要求を満たしており、コスト的にもRAIDカードなしの方が安価であったための選択でした。
スペック以外の選定基準
レンタルから購入への切り替えということもあり、データセンタでの保守業務も自社でハンドリングをしなければいけません。
そのため性能面以外でも検討項目は複数あり、以下の項目について比較検討し選定を進めていました。
- サポート
- サポート期間とサポートレベル
- 標準の保守プランでサポートされる補償範囲
- サポートの保守プランの種別と対応内容(4H対応保証、24x365対応、エンジニア派遣の有無など)
- 供給
- 標準的な納品期間
- 供給期間
- 供給停止後の保守期間
- 価格の見直しタイミング
- 構成
- ハードウェア的なメンテナンスのしやすさ
- 構成カスタマイズの柔軟さ
- 社外製品の取り付けなどの対応の柔軟さ
- IPMIの機能や対応分類、オプション範囲
- ハードウェア的な冗長性のレベル
- サーバラックの耐荷重を考慮して重量の軽さ
- サービス、その他
- ラッキングやケーブリングの実施などのサービスの実施可否
スペックが決まり各社のサーバを比較した際には、価格や上記項目以外にIPMIベースの管理ツールも大きな焦点でした。
サーバをデータセンターで遠隔運用する場合、IPMI経由で仮想的にコンソール接続できるリモートコンソール機能があると便利です。電源は入るがOSは起動しないような障害や、エラー出力がコンソールのみの場合など、遠隔地から操作できるリモートコンソールに命を救われたという経験がある方も多いと思います。
このリモートコンソールですが検討当時はJavaベース実装を採用しているメーカーと、HTML5ベース実装を採用しているメーカーが混在していました。検討を行った結果、環境を選ばずブラウザで完結するという恩恵が大きいHTML5ベース実装を採用しました。
上記の条件を元に固めた構成から9社製品10製品に候補を絞り、初回の概算見積もり価格から特に有力な3製品について検証機をレンタルし物理的な使い勝手の確認やベンチマークテストなどを行い採用を決めました。
第二世代から第三世代への更新時の選定(2018)
第二世代を運用して見えてきた課題
第二世代の稼働は順調でしたが、順調故に1サーバあたりの作成インスタンス数に制限を設けずにいたところ当初の想定の20を超え、比較的小さいフレーバーが多いサーバに多い時は60インスタンス以上が稼働している状態になりました。
vCPUのオーバーコミット率も高い時には300%(48スレッドのサーバに対し稼働しているインスタンスのvCPU数が合計144)以上になる場合もありました。結果、第三世代次への更新タイミングの頃から、特定の高負荷インスタンスと同じサーバに収容された他のインスタンスのパフォーマンスが低下する、いわゆる「ノイジーネイバー問題」が発生するようになりました。
新規インスタンスの作成可否のフラグをオーバーコミット不可のメモリ利用可能残量で閾値設定していたことにより、搭載メモリが512GBと多かったこともインスタンスの過剰搭載として裏目に出ていました。
第三世代を選定するにあたって決めたこと
2018年にXeonのモデルチェンジのため発生したサーバ更新の際、新たな機種選定に合わせてスペック構成の見直しも行いました。
ノイジーネイバー問題の発生を回避することを最大の目標に、1母艦あたりの搭載インスタンス数を減らしつつCPUのスペックアップを検討しました。
第三世代のCPUの選定
CPUのスペックアップといっても大きく分けて二つのアプローチがあります。
コア数・スレッド数の強化とクロック周波数の強化です。ざっくりとですがインスタンスの稼働数を増やしたいときは前者を増やし、インスタンスあたりの負荷を軽減したい場合は後者を選択します。今回の場合はインスタンス数を減らしインスタンスの負荷を軽減するため後者のスペックアップを採用しています。
1サーバあたりの稼働インスタンス数は再び20と仮定し、監視ツールから実際に利用されているサーバリソースを確認し必要スペックの定義を行いました。
CPU新製品のリリースに合わせ各メーカーから資料をいただいたり、Intel製品仕様ページを確認しながら有力なCPUをピックアップし、検討を重ねXeon Scalable Processor(以下XeonSP)Gold 6126を採用しました。
CPUの選び方 - クロック周波数のブーストについて
コア数・スレッド数は第二世代のXeon E5 2650V4と同等ですが、クロック周波数が高く、何よりもクロックのブーストが多コアで発生した時の下り幅が小さいことが1番の採用要因となりました。
CPUは電力消費量の削減と高性能両立のために一時的に処理能力を引き上げるためクロック周波数を上げる機能を有していますが、この機能に対する理解不足がノイジーネイバー問題の原因の一つでもありました。
カタログに記載されたクロック周波数のブースト時の値をそのまま受け取ってしまっていたため、実際の処理能力を多く見積りすぎていたのです。
例えばXeon E5 2650V4は前述のInte製品 仕様ページの記載ではBase 2.2GHz ターボブースト利用時 2.9GHzとなっています。しかしより詳細な仕様のデータシートを確認すると、2.9GHzが出るのは2コアまでの稼働時のみで3コアでブーストが利用されたときは2.7GHz, 4コアで2.6GHz, 5コア以上の場合は2.5GHzとベースクロックとさほど差のない状態となってしまいます。
最終的に採用したXeonSP Gold6126はこの点で最大ブースト時3.7GHzに対して最小ブースト幅の9コア以上ブースト時でも3.3GHzとE5 2650V4の最大ブースト時、2.9GHz以上の高クロック周波数を保っていることが採用の一番大きなポイントになっていました。
Xeonの対象モデルの稼働コア毎のturbo mode最大周波数(Intel AVX未使用時)
| Model Number | Core 1-2 | Core 3 | Core 4 | Core 5 | Core 6 | Core 7 | Core 8 | Core 9 | Core 10 | Core 11+ |
|---|---|---|---|---|---|---|---|---|---|---|
| E5 2650V4 | 2.9GHz | 2.7GHz | 2.6GHz | 2.5GHz | 2.5GHz | 2.5GHz | 2.5GHz | 2.5GHz | 2.5GHz | 2.5GHz |
| Gold 6126 | 3.7GHz | 3.5GHz | 3.5GHz | 3.4GHz | 3.4GHz | 3.4GHz | 3.4GHz | 3.3GHz | 3.3Ghz | 3.3GHz |
- 数値は共に以下の資料より引用抜粋
第三世代のメモリとストレージ
メモリについては第二世代に対して稼働する想定インスタンス数の低下により512GBでは完全にオーバースペックとなり、CPUにかかる費用が高額化したため容量削減をし384GB(32GBモジュール12枚)にしました。
ストレージも同じくコスト対策と想定稼働インスタンス数の削減による必要量の低下により、SSDのサイズは変えずにRAIDの構成本数を6本から4本に減らすことで容量と価格の削減をしました。
第三世代の採用について
Intel CPU以外にも新たに発売されたAMD EPYCの検討も行いましたが、採用した場合Intel CPUのサーバで作成されたインスタンスとAMD CPUのサーバで作成されたインスタンス間の仮想CPUの互換性が失われ、仮想化の大きな利点であるライブマイグレーションが行えなくなるため情報収集にとどまりました。
第二世代の選定時にある程度絞ったメーカーの2社2機種に絞り、同様に検証を行い最終的には第二世代と同メーカーの後継機種の採用を決めました。
CPU単価が大きく上がったためメモリとSSDの削減をしても1台当たりの購入価格が大きく上がりました。しかしノイジーネイバー問題はそれだけの解決すべき問題でした。
第三世代から第四世代への更新時の選定(2019)
第三世代を運用して見えてきた課題
第三世代はCPU性能を重点に選定し、結果ノイジーネイバーの発生頻度は大きく抑えることができました。
しかし第二世代に対してサーバ1台当たりの価格が上がり、その上でサーバ1台当たりの搭載インスタンス数を少なくしたため、稼働している1インスタンス当たりのハードウェア調達コストは大きく悪化しました。
第四世代の構成の方針決定
第三世代で達成したノイジーネイバーを発生しない状況を維持しつつ、1インスタンスあたりのハードウェア費用を最大限下げることを指針としましました。
またこの年はサーバ本体以外にもネットワーク環境などへの投資があり、サーバに割ける予算が前年より減少してしまったため価格の優先度がより高くなっていました。
1インスタンス当たりのハードウェアコストは (サーバ価格 / 稼働インスタンス数) で求められるため、ハードウェアコストを下げる手法は大きく分けて二つに分けられます。
一つはサーバ価格が同じであればより多くのインスタンスが稼働できる性能にすること。二つ目が稼働インスタンス数が同じであればサーバ価格を安価なものにすることです。
第四世代はこれらどちらか、もしくは両立によるハードウェアコストの削減を目指してのサーバ検討となりました。
第四世代のCPUの選定
ペパボのプライベートクラウドのサーバで一番価格に直結するパーツはCPUです。
CPU単体の価格だけでなく、CPUのスレッド数に合わせて稼働可能なインスタンス数上限を計算することから、それに合わせてメモリやストレージのサイズも連動しているため、CPU選定次第でサーバ価格が決まると言っても過言ではありません。
サーバ1台あたりの価格を下げるため比較的安価なCPUであるXeonSPのBronzeクラスから、反面稼働インスタンス数を最大化するための最上位のPlatinumクラスまで、前述のIntel製品詳細ページで目的に合致しそうな製品をピックアップし比較し、一時期はPlatinumの採用も本気で検討していました。
しかし検証終盤に滑り込みでIntel XeonのCascadeLake世代のCPUにRefreshモデルが発表され、これが価格的にも性能的にも優れていました。
特に良かった製品は第三世代で採用した6126の直系後継モデルである6226の更にリフレッシュモデルに当たる6226Rで、価格は6226より安価でコア数もクロック周波数も強化されていました。特にコア数が12から16に増えた事が大きく、1インスタンスの基準値を4vCPUで計算しているため64スレッドでオーバーコミット率300%なら48インスタンスの稼働が見込めます。
リフレッシュモデル発売前の候補のひとつ、第二世代で採用していた6126の後継モデル6226は12コア24スレッドでした。これを2基搭載してインスタンス稼働見込みを前段と同条件の1インスタンス4vCPU+オーバーコミット率300%で計算すると36インスタンスとなり、リフレッシュモデルの6226Rの稼働見込み48インスタンスは6226の1.3倍です。
価格面でもIntalの定価ベース(米ドル)ですが1CPUあたり6226が$1776、6226Rが$1306とリフレッシュモデルの方が3割以上も安くなっています。CPUは2基搭載するため差額の重要度はより高く、この差額によりインスタンス稼働数増加を支えるメモリやSSDなどの増強をしつつもサーバ1台あたりの値段を維持する事ができました。
安価なCPUを採用してサーバ数を増やす方針や、より高価なCPUを採用してサーバ当たりの稼働インスタンス数を更に上げることも検討しましたが、価格と稼働インスタンス数を計算していくと今回採用した6226Rでの構成が安価なCPUを採用した場合やより高価なCPUを採用した場合と比較して、一番コストパフォーマンスに優れる構成でした。
一見良いところばかりのこのCPUの最大の問題点は消費電力です。現在利用しているデータセンタのラックは電力が2kVA3系統の契約となっており、1基で150WのこのCPUはラックあたりの搭載数という点で大きな欠点でした。しかし過去のサーバ運用上、TDP上限まで電力を消費しているサーバというのは意外と少ないため最終的にこのCPUを選択しました。
CPUの選定時のベンチマークの一例
CPU選定時には検証機を借りて様々な構成でベンチマークテストを行っています。次の画像は一例としてUnixBenchにて整数演算処理と不動小数点演算処理を1並列〜128並列までテストし、スコアをグラフにしたものです。第四世代の選定初期に計測したもので、主に第三世代より高性能なCPUの比較検討に用いたグラフです。
グラフ中では4種類のCPUをテストしていますが、第三世代で採用した6126以外の製品名は非公表とさせていただきます。
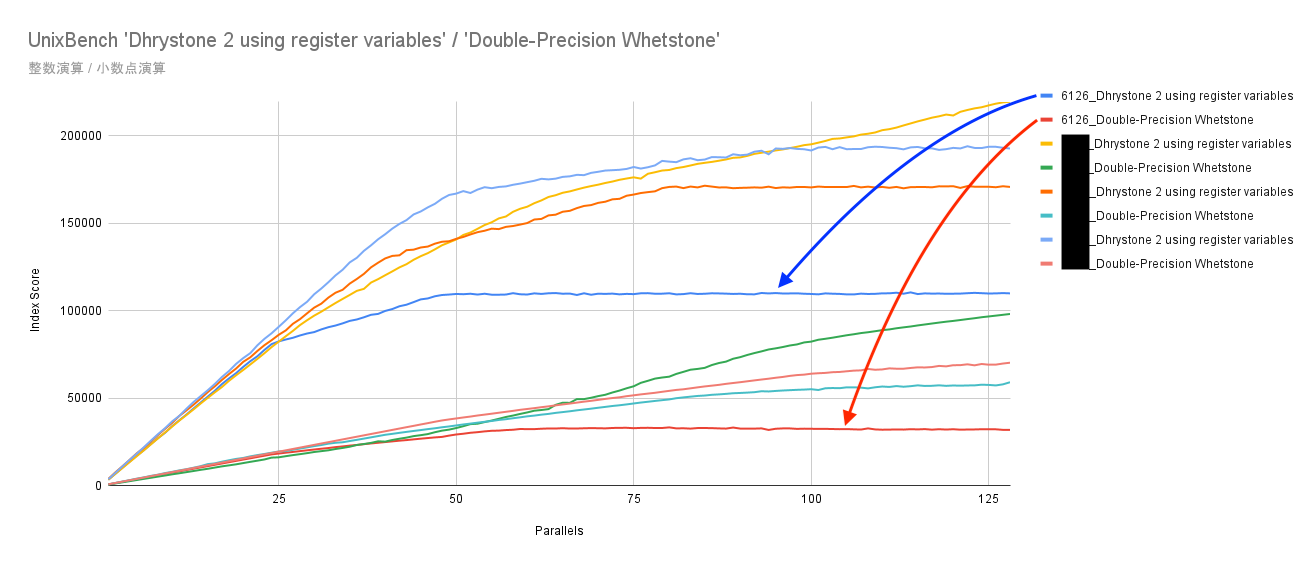
ペパボではハイパースレッディング(HTT)を有効にしています。第三世代の6126は12コア24スレッドのCPUで2基搭載しています(青と赤のライン)。24並列のテストまではリニアにスコアが上昇したものの、1物理コアで2スレッドが稼働することになる24並列以上のテストではスコアの伸びがなだらかになり、スレッド数上限の48並列のテストで頭打ちに。以降は並列数を上げても誤差範囲の数値のブレに止まっていることが見て取れます。
6126よりも高性能なCPUとの比較のため、グラフ上では第三世代の採用のCPU性能が低く見えますが、価格的には約2.3倍〜約4.8倍と高コスト帯のCPUとの比較のため、価格まで含めたトータルバランスでは6126は優秀でした。
この後6126の後継である6226を中心に同クラスのCPUを中心とした検証を行い、前述の6226Rの採用に繋がりました。
このようにベンチマークのスコア以外にも価格や作業中のサーバの熱量、消費電力など様々な要素を検討しCPUの選定を行っています。
第四世代のメモリとストレージについて
CPUが決まり、稼働可能なインスタンス数を最大化する方針となったため、メモリとストレージについても同様に多数のインスタンスを支るために強化します。
第二世代選定時の基準フレーバーサイズ 8GBメモリ以上のメモリを利用するインスタンスも増えてきたため、オーバーコミットなく多数のインスタンスを実行する場合512GBでは不安が残ります。丁度選定時に64GBなど大容量のメモリモジュールの価格が下がってきたことや対象のCPUのメモリチャネルが6(ざっくりとメモリの搭載枚数が6の倍数を搭載時にメモリの性能を一番引き出せる)ため、64GBモジューのメモリを12枚(1CPUあたり6枚を2CPU分)搭載した768GB構成の採用を決めました。
ストレージについても同様に増加を行いましたが、ディスク1本あたりの単体容量は第三世代から変えずに搭載本数を4本から6本に増やす方向で構成を決めました。1.92TBでRAID5を構成しているため、利用可能なディスクサイズはおおよそ5.76TBから9.6TBへの増加になります。
HardWareRAIDの選択
当初SoftwareRAIDで開始したプライベートクラウドでしたが、選定したサーバ機種がRAIDカード越しでないと管理ツール上から見れるデータが少なく、また故障時に保守サービスとのやりとりがRAIDカード搭載前提の場合が多く微妙な使いにくさを感じていました。
第二世代の頃よりRAIDカードの搭載キャッシュメモリの容量も増え、搭載することでWriteの性能向上も期待できることからRAIDカード搭載を選択、第四世代からHardWareRAIDへと切り替えました。
第四世代の採用について
選定に当たってはCPUの項目で記載した様々な構成での見積もりを行った記録の一端がこちらの画像になります。
金額や製品名が記載されているものなのでそのままお見せできないのが残念ですが、スプレッドシートでCPUスレッド数やメモリ容量ストレージ容量などなどを1行目の第三世代と比較し、搭載量やCPUコア単価などの価格の増減を可視化しました。
予算面で特に気を使った第四世代ですが上記のような検討を経て最終的には第三世代から単体の費用が微増するものの稼働インスタンス数が倍近くに増え、結果として1インスタンスあたりのサーバ費用の軽減を達成するとができました。
サーバ消費電力と熱の問題とその対応
CPU選定の項目で記載した通り、今回のCPUはTDP150Wの高消費電力CPUでしたがこれが導入後にネックとなりました。
既存の第二世代、第三世代のサーバのカタログスペック上のサーバ消費電力と、実際の稼働中サーバで計測した消費電力の差異から算定した比率を第四世代に当てはめ、実効消費電力は1台500W台程度を予想していました。しかし導入早々に600W〜最大700Wと想定に対し大幅に大きい電力消費を計測しました。
また重ねて想定外だったのが熱の問題です。今までのペパボの運用ではデータセンターのサーバにて熱による問題が発生したことなかったため完全に不意打ちでした。ログに熱によるCPU速度制限(サーマルスロットル)が現れるようになり、電力と熱の双方の問題解決が必要になりました。
ファンオフセット設定と電力制限(PowerCapping)
サーバ1台あたりの電力が過大になると1ラック当たりのサーバ搭載数が絞られ、1台の稼働インスタンス数が多くなってもラックあたりの稼働インスタンス数は伸びないという問題につながります。これを解決するためにPowerCappingを導入しました。
PowerCappingとはハードウェア・ソフトウェアいずれかの制御で消費電力を一定以上にならないよう抑える機能で、採用しているサーバでは管理ツールに実装されているため、管理ツール上から電力を制限する事としました。
とはいえ無闇に電力を制限してサーバの性能が劣化してしまったら高性能なCPUを選んだ意味がなく元も子もありません。そこで電力の制限値をを小刻みに設定し、都度ベンチマークツールで性能計測、電力制限と速度のバランスの良い落とし所を探しました。
また合わせて熱問題解決のため、冷却ファンの速度設定としてオフセット設定の変更にも着手しました。こちらも管理ツール上からのファン設定の変更で行えましたが、想定外だったのはファンの設定変更による消費電力の変動です。ファンの回転数などそこまで影響しないだろうと未設定の状態から一段上の冷却設定に変更したところ、60Wも消費電力が上昇しシビアな電力状況に追い討ちとなりました。
しかし熱問題も解決しないとサーマルスロットルによる性能劣化が発生する恐れがあるため、PowerCappingと複合で設定と検証を行いました。
はなはだ簡易ではありますが行った様々なテストのうちPowerCappingの簡単な表になります。
| 設定最大ワット制限値 | UnixBench dhry2reg index | 管理ツール計測実効ワット | 最大CPU温度 | 出力比 |
|---|---|---|---|---|
| 設定なし | 125459.6 | 569W | 91 | 100% |
| 513W | 121482.2 | 515W | 83 | 90% |
| 456W | 113432.8 | 463W | 86 | 80% |
| 399W | 104215.4 | 404W | 78 | 70% |
| 342W | 87052.3 | 347W | 68 | 60% |
| 285W | 60607.6 | 296W | 60 | 50% |
冷却ファンの設定を変更し、PowerCappingと組み合わせてのベンチマークスコアの検証も行いました。
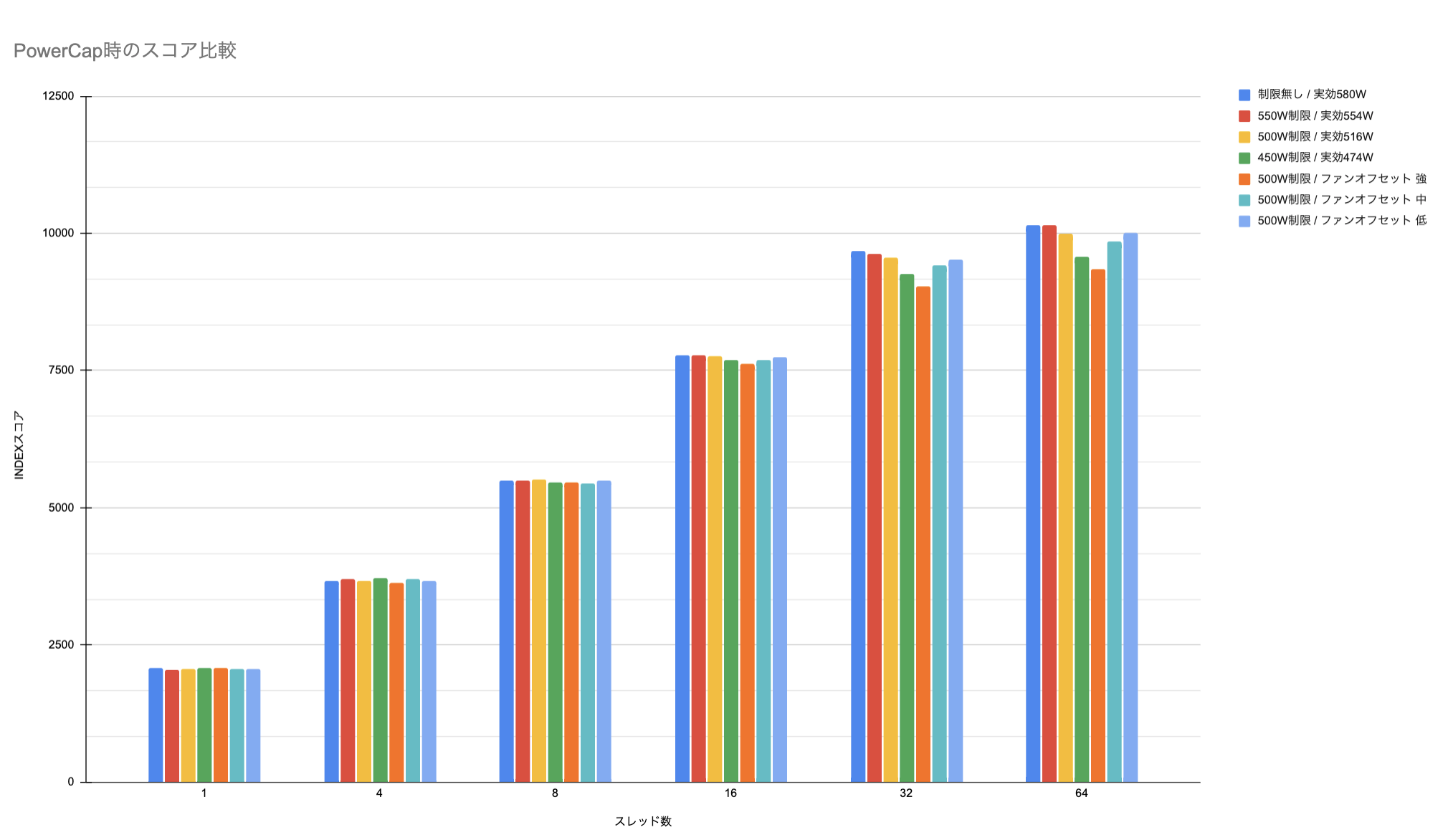
面白い点としてファンの回転数が電力をある程度消費するため、PowerCappingを導入した状態でより強い冷却設定を行った場合に冷却ファンに電力リソースを奪われ、弱い冷却設定よりもCPU性能が出ないことが分かりました。
結果を知っていれば当然だと思える内容ですがベンチマークを実行してこの結果が出たときには意外性を感じました。これらのベンチマークの結果、現在は550W制限+ファンオフセット弱の組み合わせてで設定し安定して稼働しています。
終わりに
ペパボのプライベートクラウドのサーバハードウェア選定、如何でしたでしょうか。
サービスが稼働する土台でありながら意外と知られていないサーバやハードウェア事情。最近はクラウドの隆盛で自社で購入ということは減ってきた感もありますが、運用によってはクラウドの利用より大幅なコストダウンを図れるかもしれませんよ。
一歩間違えると性能が出ずにサービス全体に悪影響を及ぼしたり、構成の煩雑さやミスマッチから運用コストの悪化などを招く怖さがあり、選定には大きな緊張を伴います。
ソフトウェアに対してハードウェアはインターネット上での情報共有も少なく、各社各人で持っている苦悩や工夫、ノウハウにナレッジを学べる機会は意外と限られているように感じます。私も他の方や他の会社の話を聞いてみたいですね。また興味があるという方は是非お声がけください。
春にIntel、AMD共にサーバ向けCPU新製品を販売開始し、メーカー各社が対応した新製品の販売を開始したためペパボでも第四世代からの更新時期となってきました。2022年以降に採用する第五世代の検討、ペパボでご一緒にサーバをいじり回してみませんか?



