こんにちは。3球目攻撃を仕掛けるときは、ボールが戻ってくることを考えずにフルスイングします、 P山 です。今日はGMOペパボでOpenStackを利用したプライベートクラウドを運用する中で発生した、ノイジーネイバー問題と、それをいかに解決したのかを紹介します。
ノイジーネイバー問題
昨今のクラウドサービスで起動するVMやコンテナは一つの物理サーバーを共用して起動されることが多く、物理サーバーのCPUやメモリはハイパーバイザー、OSのスケジューラーなどのプロセスが、それぞれのVMやコンテナにリソースを配分しています。その際に、例えばある物理サーバーに同居しているVM AとVM Bが存在するとして、どちらかのVMが大量にCPUリソースを消費した場合に、VM同士でCPUリソースの競合が発生してしまい、それぞれのVMに対して十分なCPUリソースを割り当て出来ない状態が発生します。このように、一つの物理サーバーに同居しているVM、コンテナなどに対して、十分なリソースが割り当てられない状態をこの記事ではノイジーネイバー問題と定義します。
実際に発生した課題
GMOペパボが提供するサービスのHTTP(S)を提供するVMにおいて、断続的に外形監視がダウンするという状態が発生しました。その際に、該当のVMのCPUメトリクスを確認したところ、Stealの値が平時と比較して高くなっている傾向がありました。Stealについては同僚の @hiboma が調査した steal.md が詳しいです。またこのVMが所属するハイパーバイザーが動作しているサーバー(以降母艦)のCPUメトリクスを確認したところ、全体的な使用率が高い状態になっていました。このようなことが起こる背景としては、われわれが提供しているサービスはホスティングや、EC、ハンドメイド支援事業など多岐にわたりますが、ほぼ全てが日本国内のお客様向けにサービスを提供しているかつ、業態も類似しているので、サービスのトラフィックのピークタイムが重なりやすく、似たような役割のVMが母艦に同居している場合、ピークタイムにリソースが競合してしまうということがわかりました。この問題を解決するために、VM、母艦双方のリソースを定点観測し、Stealに起因したリソース飽和が起きている場合に、自動でライブマイグレーションを実行するような実装を行いました。
Instance Migrator
課題を解決するために、Instance Migratorというソフトウエアを開発しました。Instance Migratorの機能は定期的にVMのメトリクスを取得し、リソースの使用量があらかじめ設定されたしきい値を超えている場合に、サービストラフィックを処理している上位のプロキシやKubernetesからそのVMを切り離し、Stealの少ない母艦にライブマイグレーション後、再度、プロキシやKubernetesに組み込むことです。
われわれは複数のサービスを提供しており、サービスごとに、監視サービスや、オーケストレーション・システムが異なるため、それらを抽象化した実装が行われています。
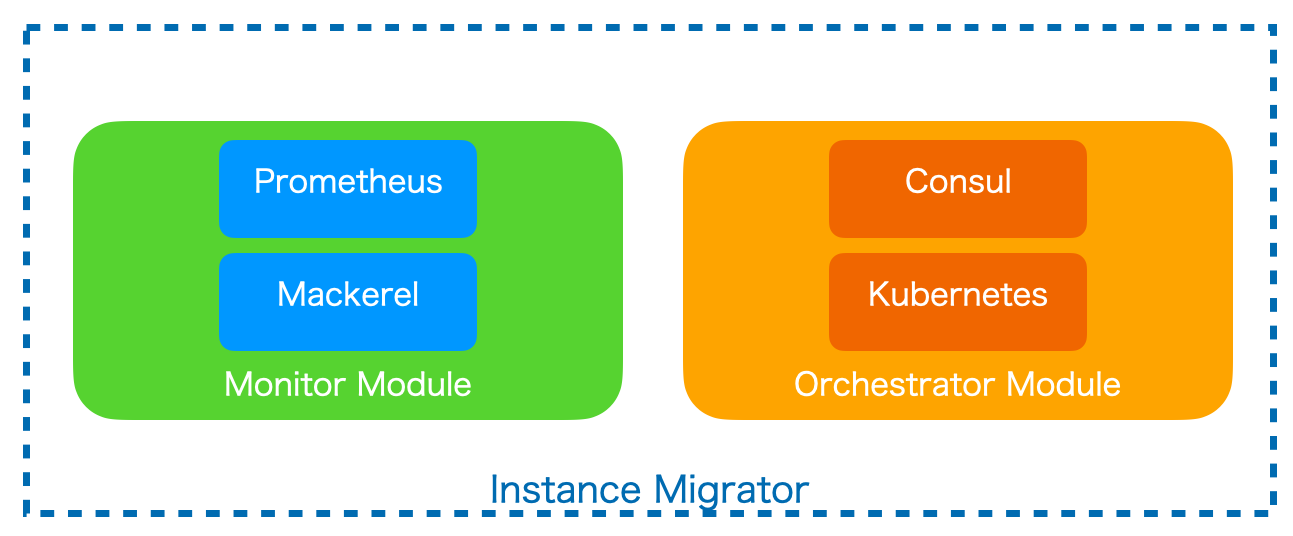
まずMonitor ModuleではMackerelやPrometheusなどの監視サービスからVMや母艦サーバーのロードアベレージとCPU Stealの値を取得し、しきい値判定を行っています。Orchestrator Moduleには利用ソフトウエアごとに、サービスクラスタから該当のVMを切り離したり、組み込んだりする処理を実装しています。Consulであれば、consul maint -enable コマンドを実行して、Consul Templateを利用して生成されている上位のプロキシサーバーの設定を変更することで、切り離しを行っています。Kubernetesであれば、kubectl drain コマンドを実行して、ノードからPodを排出して、スケジューリングを無効にします。この際に、事前のチェックで、VMを切り離してもトラフィックをさばくのに必要なVM数が足りているか、異常に切り離しが発生していないかなどのチェックを行っています。
対象のVMをサービスクラスタから切り離したのちに、母艦のメトリクスを取得して、Steal値が低いかつ、移動する対象のVMと同じ役割のVMが所属しない母艦を移行先に選択し、ライブマイグレーションを実行して、VMの母艦からの移動を行います。
ライブマイグレーションの実行結果を定期的にポーリングして、完了を検知した場合は、Orchestrator Moduleが切り離しと逆の手順を実行して、VMをサービスクラスタに追加します。
最後に
Instance Migratorの活躍もあり、ノイジーネイバー問題に起因するサービスの遅延問題は解決しました。またこれによりこれまでSREが定期的に行っていたVM移動を伴う母艦のリソース平準化作業も削減することが出来ました。GMOペパボではSREの取り組みとしてソフトウエアで課題をするという仕事が多くあります。こういった業務に興味があるSRE未経験の方を対象に【2022/07/01 入社必須】ペパボカレッジ(SRE:Site Reliability Engineer) を現在公開しておりますので、ぜひご応募ください!!!ちょれーーーい。